Let’s design a Twitter like social media service, similar to services like Facebook, Instagram, etc.
What is Twitter?
Twitter is a social media service where users can read or post short messages (up to 280 characters) called tweets. It is available on the web and mobile platforms such as Android and iOS.
Requirements
Our system should meet the following requirements:
Functional requirements
- Should be able to post new tweets (can be text, image, video, etc.).
- Should be able to follow other users.
- Should have a newsfeed feature consisting of tweets from the people the user is following.
- Should be able to search tweets.
Non-Functional requirements
- High availability with minimal latency.
- The system should be scalable and efficient.
Extended requirements
- Metrics and analytics.
- Retweet functionality.
- Favorite tweets.
Estimation and Constraints
Let’s start with the estimation and constraints.
Note: Make sure to check any scale or traffic-related assumptions with your interviewer.
Traffic
This will be a read-heavy system, let us assume we have 1 billion total users with 200 million daily active users (DAU), and on average each user tweets 5 times a day. This gives us 1 billion tweets per day.
200 space million times 5 space messages = 1 space billion/day
200 million×5 messages=1 billion/day
Tweets can also contain media such as images, or videos. We can assume that 10 percent of tweets are media files shared by the users, which gives us additional 100 million files we would need to store.
10 space percent times 1 space billion = 100 space million/day
10 percent×1 billion=100 million/day
What would be Requests Per Second (RPS) for our system?
1 billion requests per day translate into 12K requests per second.
frac{1 space billion}{(24 space hrs times 3600 space seconds)} = sim 12K space requests/second
(24 hrs×3600 seconds)1 billion=∼12K requests/second
### Storage
If we assume each message on average is 100 bytes, we will require about 100 GB of database storage every day.
1 space billion times 100 space bytes = sim 100 space GB/day
1 billion×100 bytes=∼100 GB/day
We also know that around 10 percent of our daily messages (100 million) are media files per our requirements. If we assume each file is 50 KB on average, we will require 5 TB of storage every day.
100 space million times 100 space KB = 5 space TB/day
100 million×100 KB=5 TB/day
And for 10 years, we will require about 19 PB of storage.
(5 space TB + 0.1 space TB) times 365 space days times 10 space years = sim 19 space PB
(5 TB+0.1 TB)×365 days×10 years=∼19 PB
### Bandwidth
As our system is handling 5.1 TB of ingress every day, we will a require minimum bandwidth of around 60 MB per second.
frac{5.1 space TB}{(24 space hrs times 3600 space seconds)} = sim 60 space MB/second
(24 hrs×3600 seconds)5.1 TB=∼60 MB/second
### High-level estimate
Here is our high-level estimate:
| Type | Estimate |
|---|---|
| Daily active users (DAU) | 100 million |
| Requests per second (RPS) | 12K/s |
| Storage (per day) | ~5.1 TB |
| Storage (10 years) | ~19 PB |
| Bandwidth | ~60 MB/s |
Data model design
This is the general data model which reflects our requirements.
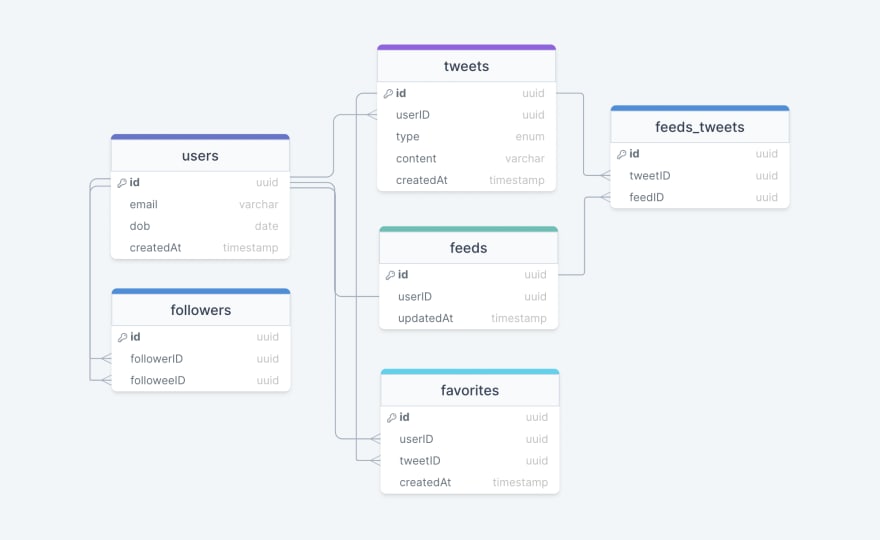
We have the following tables:
users
This table will contain a user’s information such as name, email, dob, and other details.
tweets
As the name suggests, this table will store tweets and their properties such as type (text, image, video, etc.), content, etc. We will also store the corresponding userID.
favorites
This table maps tweets with users for the favorite tweets functionality in our application.
followers
This table maps the followers and followees as users can follow each other (N:M relationship).
feeds
This table stores feed properties with the corresponding userID.
feeds_tweets
This table maps tweets and feed (N:M relationship).
What kind of database should we use?
While our data model seems quite relational, we don’t necessarily need to store everything in a single database, as this can limit our scalability and quickly become a bottleneck.
We will split the data between different services each having ownership over a particular table. Then we can use a relational database such as PostgreSQL or a distributed NoSQL database such as Apache Cassandra for our use case.
API design
Let us do a basic API design for our services:
Post a tweet
This API will allow the user to post a tweet on the platform.
postTweet(userID: UUID, content: string, mediaURL?: string): boolean
Parameters
User ID (UUID): ID of the user.
Content (string): Contents of the tweet.
Media URL (string): URL of the attached media (optional).
Returns
Result (boolean): Represents whether the operation was successful or not.
Follow or unfollow a user
This API will allow the user to follow or unfollow another user.
follow(followerID: UUID, followeeID: UUID): boolean
unfollow(followerID: UUID, followeeID: UUID): boolean
Parameters
Follower ID (UUID): ID of the current user.
Followee ID (UUID): ID of the user we want to follow or unfollow.
Media URL (string): URL of the attached media (optional).
Returns
Result (boolean): Represents whether the operation was successful or not.
Get newsfeed
This API will return all the tweets to be shown within a given newsfeed.
getNewsfeed(userID: UUID): Tweet[]
Parameters
User ID (UUID): ID of the user.
Returns
Tweets (Tweet[]): All the tweets to be shown within a given newsfeed.
High-level design
Now let us do a high-level design of our system.
Architecture
We will be using microservices architecture since it will make it easier to horizontally scale and decouple our services. Each service will have ownership of its own data model. Let’s try to divide our system into some core services.
User Service
This service handles user-related concerns such as authentication and user information.
Newsfeed Service
This service will handle the generation and publishing of user newsfeeds. It will be discussed in detail separately.
Tweet Service
The tweet service will handle tweet-related use cases such as posting a tweet, favorites, etc.
Search Service
The service is responsible for handling search-related functionality. It will be discussed in detail separately.
Media service
This service will handle the media (images, videos, files, etc.) uploads. It will be discussed in detail separately.
Notification Service
This service will simply send push notifications to the users.
Analytics Service
This service will be used for metrics and analytics use cases.
What about inter-service communication and service discovery?
Since our architecture is microservices-based, services will be communicating with each other as well. Generally, REST or HTTP performs well but we can further improve the performance using gRPC which is more lightweight and efficient.
Service discovery is another thing we will have to take into account. We can also use a service mesh that enables managed, observable, and secure communication between individual services.
Note: Learn more about REST, GraphQL, gRPC and how they compare with each other.
Newsfeed
When it comes to the newsfeed, it seems easy enough to implement, but there are a lot of things that can make or break this feature. So, let’s divide our problem into two parts:
Generation
Let’s assume we want to generate the feed for user A, we will perform the following steps:
- Retrieve the IDs of all the users and entities (hashtags, topics, etc.) user A follows.
- Fetch the relevant tweets for each of the retrieved IDs.
- Use a ranking algorithm to rank the tweets based on parameters such as relevance, time, engagement, etc.
- Return the ranked tweets data to the client in a paginated manner.
Feed generation is an intensive process and can take quite a lot of time, especially for users following a lot of people. To improve the performance, the feed can be pre-generated and stored in the cache, then we can have a mechanism to periodically update the feed and apply our ranking algorithm to the new tweets.
Publishing
Publishing is the step where the feed data is pushed according to each specific user. This can be a quite heavy operation, as a user may have millions of friends or followers. To deal with this, we have three different approaches:
- Pull Model (or Fan-out on load)
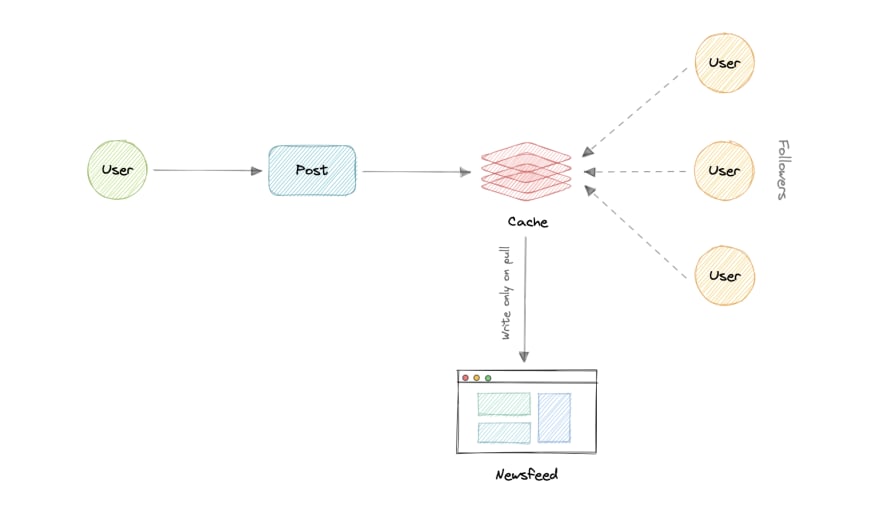
When a user creates a tweet, and a follower reloads their newsfeed, the feed is created and stored in memory. The most recent feed is only loaded when the user requests it. This approach reduces the number of write operations on our database.
The downside of this approach is that the users will not be able to view recent feeds unless they “pull” the data from the server, which will increase the number of read operations on the server.
- Push Model (or Fan-out on write)
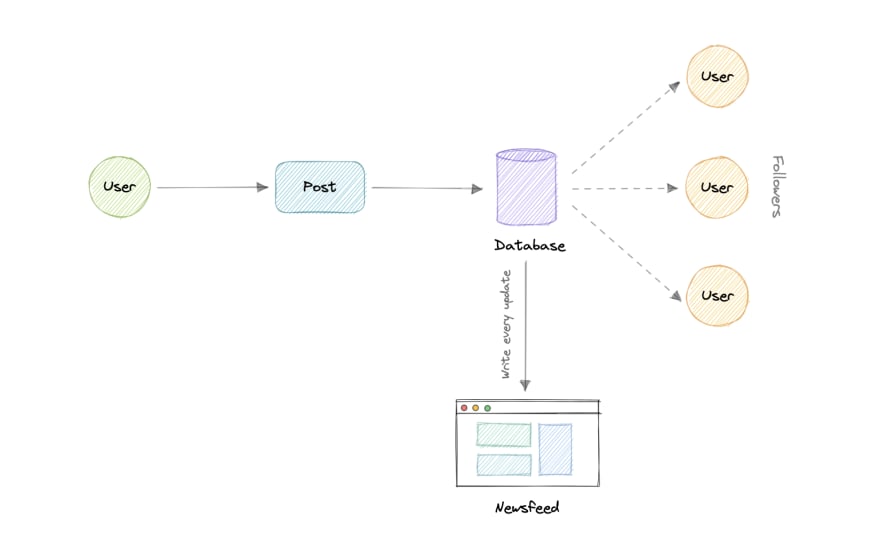
In this model, once a user creates a tweet, it is “pushed” to all the follower’s feeds immediately. This prevents the system from having to go through a user’s entire followers list to check for updates.
However, the downside of this approach is that it would increase the number of write operations on the database.
- Hybrid Model
A third approach is a hybrid model between the pull and push model. It combines the beneficial features of the above two models and tries to provide a balanced approach between the two.
The hybrid model allows only users with a lesser number of followers to use the push model and for users with a higher number of followers celebrities, the pull model will be used.
Ranking Algorithm
As we discussed, we will need a ranking algorithm to rank each tweet according to its relevance to each specific user.
For example, Facebook used to utilize an EdgeRank algorithm, here, the rank of each feed item is described by:
Rank = Affinity times Weight times Decay
Rank=Affinity×Weight×Decay
Where,
Affinity: is the “closeness” of the user to the creator of the edge. If a user frequently likes, comments, or messages the edge creator, then the value of affinity will be higher, resulting in a higher rank for the post.
Weight: is the value assigned according to each edge. A comment can have a higher weightage than likes, and thus a post with more comments is more likely to get a higher rank.
Decay: is the measure of the creation of the edge. The older the edge, the lesser will be the value of decay and eventually the rank.
Nowadays, algorithms are much more complex and ranking is done using machine learning models which can take thousands of factors into consideration.
Retweets
Retweets are one of our extended requirements. To implement this feature we can simply create a new tweet with the user id of the user retweeting the original tweet and then modify the type enum and content property of the new tweet to link it with the original tweet.
For example, the type enum property can be of type tweet, similar to text, video, etc and content can be the id of the original tweet. Here the first row indicates the original tweet while the second row is how we can represent a retweet.
| id | userID | type | content | createdAt |
|---|---|---|---|---|
| ad34-291a-45f6-b36c | 7a2c-62c4-4dc8-b1bb | text | Hey, this is my first tweet… | 1658905644054 |
| f064-49ad-9aa2-84a6 | 6aa2-2bc9-4331-879f | tweet | ad34-291a-45f6-b36c | 1658906165427 |
This is a very basic implementation, to improve this we can create a separate table itself to store retweets.
Search
Sometimes traditional DBMS are not performant enough, we need something which allows us to store, search, and analyze huge volumes of data quickly and in near real-time and give results within milliseconds. Elasticsearch can help us with this use case.
Elasticsearch is a distributed, free and open search and analytics engine for all types of data, including textual, numerical, geospatial, structured, and unstructured. It is built on top of Apache Lucene.
How do we identify trending topics?
Trending functionality will be based on top of the search functionality. We can cache the most frequently searched queries, hashtags, and topics in the last N seconds and update them every M seconds using some sort of batch job mechanism. Our ranking algorithm can also be applied to the trending topics to give them more weight and personalize them for the user.
Notifications
Push notifications are an integral part of any social media platform. We can use a message queue or a message broker such as Apache Kafka with the notification service to dispatch requests to Firebase Cloud Messaging (FCM) or Apple Push Notification Service (APNS) which will handle the delivery of the push notifications to user devices.
For more details, refer to the Whatsapp system design where we discuss push notifications.
Detailed design
It’s time to discuss our design decisions in detail.
Data Partitioning
To scale out our databases we will need to partition our data. Horizontal partitioning (aka Sharding) can be a good first step. We can use partitions schemes such as:
- Hash-Based Partitioning
- List-Based Partitioning
- Range Based Partitioning
- Composite Partitioning
The above approaches can still cause uneven data and load distribution, we can solve this using Consistent hashing.
For more details, refer to Sharding and Consistent Hashing.
Mutual friends
For mutual friends, we can build a social graph for every user. Each node in the graph will represent a user and a directional edge will represent followers and followees. After that, we can traverse the followers of a user to find and suggest a mutual friend. This would require a graph database such as Neo4j and ArangoDB.
This is a pretty simple algorithm, to improve our suggestion accuracy, we will need to incorporate a recommendation model which uses machine learning as part of our algorithm.
Metrics and Analytics
Recording analytics and metrics is one of our extended requirements. As we will be using Apache Kafka to publish all sorts of events, we can process these events and run analytics on the data using Apache Spark which is an open-source unified analytics engine for large-scale data processing.
Caching
In a social media application, we have to be careful about using cache as our users expect the latest data. So, to prevent usage spikes from our resources we can cache the top 20% of the tweets.
To further improve efficiency we can add pagination to our system APIs. This decision will be helpful for users with limited network bandwidth as they won’t have to retrieve old messages unless requested.
Which cache eviction policy to use?
We can use solutions like Redis or Memcached and cache 20% of the daily traffic but what kind of cache eviction policy would best fit our needs?
Least Recently Used (LRU) can be a good policy for our system. In this policy, we discard the least recently used key first.
How to handle cache miss?
Whenever there is a cache miss, our servers can hit the database directly and update the cache with the new entries.
For more details, refer to Caching.
Media access and storage
As we know, most of our storage space will be used for storing media files such as images, videos, or other files. Our media service will be handling both access and storage of the user media files.
But where can we store files at scale? Well, object storage is what we’re looking for. Object stores break data files up into pieces called objects. It then stores those objects in a single repository, which can be spread out across multiple networked systems. We can also use distributed file storage such as HDFS or GlusterFS.
Content Delivery Network (CDN)
Content Delivery Network (CDN) increases content availability and redundancy while reducing bandwidth costs. Generally, static files such as images, and videos are served from CDN. We can use services like Amazon CloudFront or Cloudflare CDN for this use case.
Identify and resolve bottlenecks

Let us identify and resolve bottlenecks such as single points of failure in our design:
- “What if one of our services crashes?”
- “How will we distribute our traffic between our components?”
- “How can we reduce the load on our database?”
- “How to improve the availability of our cache?”
- “How can we make our notification system more robust?”
- “How can we reduce media storage costs”?
To make our system more resilient we can do the following:
- Running multiple instances of each of our services.
- Introducing load balancers between clients, servers, databases, and cache servers.
- Using multiple read replicas for our databases.
- Multiple instances and replicas for our distributed cache.
- Exactly once delivery and message ordering is challenging in a distributed system, we can use a dedicated message broker such as Apache Kafka or NATS to make our notification system more robust.
- We can add media processing and compression capabilities to the media service to compress large files which will save a lot of storage space and reduce cost.
This article is part of my open source System Design Course available on Github.

karanpratapsingh
/
system-design
Learn how to design systems at scale and prepare for system design interviews
System Design Course
Hey, welcome to the course. I hope this course provides a great learning experience.
This course is also available on my website. Please leave a ⭐ as motivation if this was helpful!
Table of contents
-
Getting Started
-
Chapter I
-
Chapter II
-
Chapter III
- N-tier architecture
- Message Brokers
- Message Queues
- Publish-Subscribe
- Enterprise Service Bus (ESB)
- Monoliths and Microservices
- Event-Driven Architecture (EDA)
- Event Sourcing
- Command and Query Responsibility Segregation (CQRS)
- API Gateway
- REST, GraphQL, gRPC
- Long polling, WebSockets, Server-Sent Events (SSE)
-
Chapter IV