In the ever-evolving landscape of cybersecurity, the emergence of Artificial Intelligence (AI) presents both opportunities and challenges. One such challenge arises in the form of Transfer Learning as an Attack Vector. Transfer learning attacks represent a sophisticated approach wherein adversaries leverage pre-existing models to craft and deploy malicious interventions, circumventing traditional defense mechanisms.
This text delves into the intricacies of such attacks, exploring their phases, methodologies, and potential impacts. By dissecting real-world scenarios and offering comprehensive strategies for prevention and mitigation, it aims to equip practitioners with the knowledge needed to fortify their defenses against this evolving threat landscape. Through a fusion of theoretical insights and practical considerations, I navigate the complex interplay between cybersecurity and AI, trying to illuminate pathways towards resilience in an era defined by technological convergence and adversarial innovation.
Here, I consider a Transfer learning attack when an attacker trains a model on one task and then fine-tunes it on another task to cause it to behave in an undesirable way. According to Zhu et al.(2019), “transferable poisoning attacks [are the ones] that succeed without access to the victim network’s outputs, architecture, or (in some cases) training data”.

Phases of an Attack Scenario
This section presents a malicious agent perspective about the Transfer Learning attacks.
Stage 1: Reconnaissance and Planning
• Identify Target Model: Research publicly available pre-trained models or deployed models within the target organization. Understand their functionality and intended use.
• Analyze Data and Domain Similarities: Evaluate the overlap between the target model’s domain and the attacker’s desired attack domain.
• Choose Attack Goal: Define the desired outcome of the attack (e.g., misclassification, data exfiltration, model manipulation).
Stage 2: Data Poisoning and Crafting Adversarial Examples
• Poisoning the Source: If possible, inject manipulated data (poisoned data) into the original model’s training dataset to influence its learning in a way beneficial to the attack.
• Crafting Adversarial Examples: Generate carefully crafted inputs (adversarial examples) that exploit the target model’s vulnerabilities to cause misclassification or achieve the desired attack goal. One of the techniques involved here is the pixel attack. Dropout during poison creation via adversarial perturbation (noise added via feature collision or convex polytope) helps to enhance transferability of this type of attack, without altering the labels of the dataset. This artificially generated label drift may compromise CI/CD pipeline and generate new LLM incorrectly trained.
Stage 3: Model Manipulation and Transfer
• Leverage Adapters: Employ adapter modules to bridge the gap between the pre-trained model’s domain and the attack domain. Adapters fine-tune specific layers of the model without retraining the entire architecture. In this scenario, even the poisoning of a fraction of training data (0.001%) may compromise the model.
• Fine-tuning and Retraining: Alternatively, if data allows, retrain the entire model or specific layers on the attacker’s crafted dataset to achieve the desired malicious behavior.
Stage 4: Deployment and Exploitation
• Deploy the Attack Model: Integrate the manipulated model into the target system or exploit it remotely through APIs or other attack vectors.
• Trigger the Attack: Use the crafted inputs or leverage vulnerabilities in the deployment environment to activate the attack and achieve the desired malicious outcome.
Other Possible Strategies
Black-box Attacks: If direct access to the model is unavailable, the attacker might use black-box techniques like query manipulation or gradient-based methods to infer and manipulate the model’s behavior. Check Carlini et al. (2024) for more information about this type of attack.
Now, consider freezing versus retraining layers. I will try to weigh the risks involved in each one of these strategies.
Freezing the original model weights:
- Risk: The attacker might exploit existing vulnerabilities or knowledge leakage from the pre-trained model.
- Benefit: Faster deployment, less computational resources required.
Retraining the whole model:
- Risk: Requires more data and computational resources, potential for introducing new vulnerabilities.
- Benefit: Potentially improves resilience by erasing attacker-injected knowledge, allows for domain-specific adaptations.
Ultimately, the bigger risk depends on your specific scenario:
- Limited Data: If data is scarce for retraining, freezing weights might be riskier due to potential overfitting and vulnerability reuse.
- High-Attack Surface: If the pre-trained model has a large attack surface, retraining might be preferable despite resource constraints.
- Critical Application: For critical applications with high security requirements, retraining to address known vulnerabilities might be necessary even with additional costs.
Remember, the best approach requires a careful evaluation of risks and benefits considering your specific threat model and resource limitations.
Social Engineering: The attacker might crafted misleading messages that played on human psychological vulnerabilities, tricking users into responding in ways that benefited the attacker’s goals, further compromising campaign’s impact.

Choosing a Resilient Model against Transfer Learning
In order to increase Machine Learning models’ security, we have to address all phases of MLOps, since data until deployment / CICD. Each MLOps phase carries specific properties than may be used to reduce attack surface and model/system vulnerability.
Dataset Properties
Data Domain Gap: if the data is specific for a given domain, models are less susceptible to knowledge transfer across other unrelated domains, as the shared knowledge is usually small.
Data Integrity: Implement data quality checks and anomaly detection to identify and remove poisoned data that attackers might inject to manipulate the model.
Data Augmentation: Employ data augmentation techniques like random transformations or adversarial perturbation to improve model generality and thus reduce attack surface and vulnerabilities.
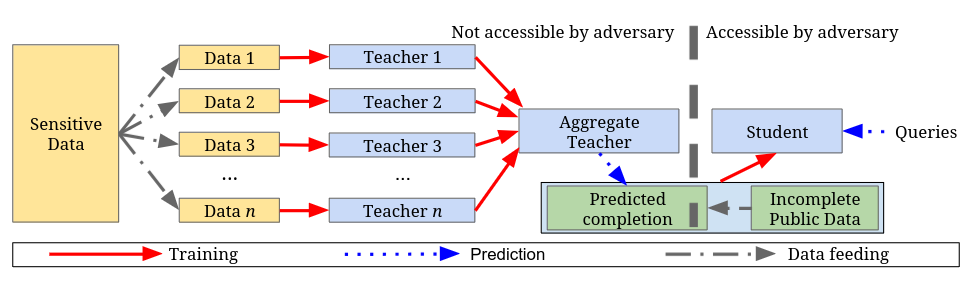
Differential privacy: it is assumed that the presence of private data, like health records and demographic data help some algorithms to have greater accuracy. If a model is trained on open health information, but a malicious actor applies transfer learning using a dataset with private health records, this may compromise a specific group of people. If someone has access to the weights of a model who was trained on sensitive data, he/she may freeze most of the weights and do transfer learning with a public dataset of the same domain, private information may be compromised at inference time. This also applies to teacher and student methodology: teacher models may be trained on disjoint subsets of sensitive data. Then, by using unlabeled non-sensitive data, a student model is trained on the aggregate output of the ensemble, such that the student learns to accurately mimic the ensemble. It also involves an ethical approach, because as private data allows an algorithm to have greater accuracy, one may feel compelled to use this data for better results.
It is known that student models, smaller and simpler models with better generalization properties are more robust to attacks. Differential privacy also enters in the accuracy/security trade-off. When you add private data from a model, you reach greater accuracy but the model becomes more susceptible to attacks. When you remove private data, the model loses part of its accuracy, generalizes better and becomes more robust to attacks.
Model Complexity and Architecture
Model Interpretability: if possible, opt for models with higher interpretability (e.g., decision trees, rule-based models) to understand attack vectors and make adjustments. However, even these models are prone to attacks, as seen in Ferry et al. (2024).
Model Modularity: Prefer models with modular components or trained on specific tasks, as attackers might struggle to manipulate the entire model for their advantage.
Feature Extraction Modules: Separate modules could extract features like edges, textures, and colors from different image regions.
Object Recognition Modules: Modules specialized in recognizing specific objects could process the extracted features.
Fusion Layer: The outputs from object recognition modules would be combined, considering relative positions and context clues to determine the final classifications.
Regularization Techniques: Use regularization techniques like L1/L2 norm, dropouts, or early stopping to prevent overfitting and reduce potential for knowledge leakage.
If the original model is overfitted, probably you won’t get rid of poison. In these situations, the attacker can add a simple dropout layer and contaminate 0.001% of training data and the attack will be successful. To get rid of poison (supposing the model weights are already poisoned by bad data), probably you need to unfreeze the whole model weights (if it is a small model) and retrain with curated data. In LLMs, if the model is poisoned it will be probably due to a transfer learning attack, as malicious actors would not spend money to train a huge model from zero. Thus, you should get rid of contaminated layers or reinitialize the contaminated layers with Xavier initialization (for instance) and fine tune the model again.
Training and Deployment
Adversarial Training: Train the model with adversarial examples to improve robustness against similar attacks in deployment. The more overfitted a model, the bigger the probability of leakage of training data. Thus, adversarial attacks enter the trade-off security/accuracy, by providing better generalization and robusteness against transfer learning attacks. This means that if the model is contaminated in the supply chain with bad data, it will be less prone to vulnerabilities, given that a model that generalizes well has little memory of the dataset, when compared to an overfitted model. When you overfit a model, it will spit out exactly the training data, given memorization, and the model does not learn patterns that will allow for a correct generalization.
Continuous Monitoring and Updates: Monitor model performance for deviations, update/retrain the model and check for data drift regularly to counter evolving attack techniques. These are components of the CI/CD pipeline.
Secure Deployment Environment: Employ secure deployment environments with access control and encryption to prevent unauthorized access and manipulation. Prefer a secret manager instead of authentication keys. Be sure the user in a container is not the default root user. Double check the libraries used in the Machine Learning models for malicious scripts and vulnerable components.
Let’s consider the cloud with a service perimeter, least privilege concept and separation of duties. In this environment, the data scientist may compromise training data and thus, model weights. However, in another environment, when the Machine Learning Engineer deploys this trained model, by only using the saved model weights and no data, he can evaluate the model against a set of benchmarks. If the data scientist model is overfitted and contaminated, the evaluation by the ML Engineer will be poor. However, if the data scientist has access to training AND development environments, he/she can manipulate also the evaluation/monitoring process.
Additional Considerations
Threat Model: Define the specific attack scenario and prioritize variables based on the likely attack vectors.
Performance Trade-offs: Balancing attack resilience with desired model performance might require trade-offs. One of them is data privacy. Evaluate based on your specific application needs.
Emerging Research: Stay updated on advancements in defending against transfer learning attacks and consider implementing new techniques as they become available.

Example Attack Scenarios
1. Dataset poisoning: an attacker trains a machine learning model on a malicious dataset that contains manipulated images of faces. The attacker wants to target a face recognition system used by a security firm for identity verification. The attacker then transfers the model’s knowledge to the target face recognition system. The target system starts using the attacker’s manipulated model for identity verification.
As a result, the face recognition system starts making incorrect predictions, allowing the attacker to bypass the security and gain access to sensitive information or even physical facilities. For example, the attacker could use a manipulated image of themselves and the system would identify them as a legitimate user.
2. Image Classification Misclassification: an attacker applies transfer learning to a pre-trained image classifier on a dataset containing poisoned images where specific objects are slightly modified to be misclassified (e.g., stop signs appearing as speed signs). This model is then deployed to manipulate real-world traffic systems.
3. Sentiment Analysis Manipulation: a malicious actor applies transfer learning to a pre-trained sentiment analysis model on fake reviews praising their product and criticizing competitors. This manipulated model is then integrated into online platforms to mislead potential customers.
4. Speech Recognition Attack: Attacker crafts adversarial audio samples containing inaudible triggers that manipulate a pre-trained speech recognition model into executing unauthorized commands on a voice-activated device, after transfer learning.
5. Chatbot Poisoning: Adversarial text prompts are used to transfer learning from a pre-trained chatbot model to a biased model with harmful responses, exploiting the model’s understanding of language and social cues for malicious purposes.

Strategies to prevent and mitigate potential Transfer Learning attacks
Preventative Measures
Use secure and trusted training datasets: Using secure and trusted training datasets can help prevent the transfer of malicious knowledge from the attacker’s model to the target model. Ensure the integrity and security of your training data by implementing data quality checks, anomaly detection, and tamper-evident mechanisms. Also, protect PII (Personal Identifiable Information).
Implement model isolation: Implementing model isolation can help prevent the transfer of malicious knowledge from one model to another. For example, separating the training and deployment environments can prevent attackers from transferring knowledge from the training environment to the deployment environment. When choosing models with limited attack surface, opt for models with simpler architectures and fewer layers, making them less prone to knowledge leakage and easier to analyze for vulnerabilities.
Use Knowledge Distillation: Distillation is a training procedure initially designed to train a deep neural network using knowledge transferred from a different deep neural network, transferring knowledge from a large model with many hyperparameters to a simpler and smaller one, with better generalization properties. This will require that the data poisoning crafted as an adversarial example be completely different from the original data, what will generate a correct classification, not altering the behavior of the deep neural network.
Applying GANs (Generative Adversarial Networks) to semi-supervised learning can greatly reduce the privacy loss by radically reducing the need for supervision, creating a more robust model.
Use differential privacy: Using differential privacy can help protect the privacy of individual records in the training dataset and prevent the transfer of malicious knowledge from the attacker’s model to the target model. A trade-off is a possible decrease of the accuracy of the model.
Leverage adversarial training: Introduce adversarial examples during training to harden the model against similar attacks in deployment.
Regularly monitor and update: Continuously monitor model performance for deviations and update the model or data regularly to adapt to evolving threats. Be aware of data drift (different distribution in training data), label drift (different distribution in labels) and concept drift (evolving construct being modeled).
Implement secure deployment environments: Utilize access control, least privilege, RBAC, encryption, and other security measures to protect deployed models from unauthorized access and manipulation.
Perform regular security audits: Regular security audits can help identify and prevent transfer learning attacks by identifying and addressing vulnerabilities in the system.
Mitigation Techniques
Data Augmentation: Diversify your training data with random transformations and variations to improve model generalization and reduce susceptibility to specific attack patterns. Think about generalization properties as a defense against attacks. If you have pure data, this can be easily memorized if overfitted, like images. The image parts, corners in the convolution may be overfitted and thus memorized, creating vulnerabilities. When you augment data, you increase generalization properties and decrease memorization. When you add regularization and dropout to this augmented data, plus adversarial training you will make the model generalize better, with less memorization and less leakage of training data. This model will be less susceptible to attacks like pixel attack (adversarial contamination).
Model distillation: Transfer knowledge from a complex pre-trained model to a smaller, more interpretable model, making it easier to detect and understand potential attack vectors.
Ensemble methods: Combine predictions from multiple diverse models to make them more resilient to individual attacks and improve overall attack detection.
Post-processing and anomaly detection: Implement post-processing techniques and anomaly detection systems to identify suspicious outputs and potentially revert to safer predictions.
Stay informed and proactive: Regularly update your knowledge about emerging transfer learning attack techniques and proactively implement new defense strategies.
Conduct threat modeling: Identify potential attack scenarios and tailor your defenses accordingly.
Prioritize based on risk: Focus on protecting models with the highest sensitivity or attack surface.
Consider trade-offs: Balancing resilience with desired model performance might require compromises.
Security is an ongoing process, and no single technique is foolproof. By implementing a combination of these strategies and staying vigilant, you can significantly reduce the risk of successful Transfer Learning attacks and protect your models and data.
Cybersecurity professionals (and ML Engineers) must remain vigilant in the face of evolving Transfer Learning attack techniques. By implementing a multi-faceted approach that encompasses secure training datasets, model isolation, adversarial training, and regular security audits, organizations can significantly reduce the risk of successful attacks. It is crucial to continuously monitor model performance, stay informed about emerging threats, and proactively implement new defense strategies. A proactive approach that prioritizes risk management and considers trade-offs between resilience and performance will enable organizations to effectively address transfer learning attacks and enhance their overall cybersecurity posture.
References
Carlini, N. et al. (2024) Stealing Part of a Production Language Model. Available at: https://arxiv.org/pdf/2403.06634.pdf
Ferry, J., Fukasawa, R., Pascal,T., Vidal. T.. (2024) Trained Random Forests Completely Reveal your Dataset. Available at: https://arxiv.org/pdf/2402.19232v1.pdf
Lin, J., Dang,L., Rahouti,M., Xiong,K. (2021) ML Attack Models: Adversarial Attacks and Data Poisoning Attacks. Available at: https://arxiv.org/pdf/2112.02797.pdf
Liu, Y., Backes, M., Zhang, X. (2023) Transferable Availability Poisoning Attacks. Available at: https://arxiv.org/pdf/2310.05141.pdf
Madry, A., Makelov, A., Schmidt, L., Tsipras, D., & Vladus, A. (2017). Towards deep learning models resistant to adversarial attacks. Available at: https://arxiv.org/pdf/1706.06083.pdf
Papernot, N., McDaniel, P., Wu, X., Jha, S., & Swami, A. (2016). Distillation as a defense to adversarial perturbations against deep neural networks. In Proceedings of the 2016 IEEE Symposium on Security and Privacy (SP) (pp. 582–597). Available at: https://ieeexplore.ieee.org/stamp/stamp.jsp?tp=&arnumber=7546524
Papernot, N., Abadi, M., Erlingsson, U., Goodfellow, I., Talwar, K. (2017) Semi-supervised Knowledge Transfer for Deep Learning from Private Training Data. Available at https://arxiv.org/pdf/1610.05755.pdf
Ribeiro, M. T., Singh, S., & Guestrin, C. (2016). “Why should I trust you?” Explaining the predictions of any classifier. Available at: https://arxiv.org/pdf/1602.04938.pdf
Zhu, C. et al. (2019) Transferable Clean-Label Poisoning Attacks on Deep Neural Nets. Proceedings of the 36 th International Conference on Machine Learning, Long Beach, California, PMLR 97, 2019. Available at: http://proceedings.mlr.press/v97/zhu19a/zhu19a.pdf
![]()
Cybersecurity in AI: Transfer Learning as an Attack Vector was originally published in Google Developer Experts on Medium, where people are continuing the conversation by highlighting and responding to this story.