
By Chansung Park and Sayak Paul (ML-GDEs)
In this post, we’ll share the lessons and findings learned from conducting load tests for a Deep Learning model across numerous deployment configurations. These configurations involve REST-based deployments with FastAPI and TensorFlow Serving. In this way, we aim to equip the readers with a holistic understanding of the differences between the two.
This post is less about code and more about the architectural decisions we had to make for performing the deployments. We’ll first provide an overview of our setup, including the technical specifications. We’ll also share our commentaries on some of the critical design choices we made and their impacts.
Technical Setup
As mentioned above, we employ two promising candidates for deployments — FastAPI and TensorFlow Serving. Both are feature-rich and have targeted specifications embedded in their designs (more on this later).
To perform our testing, we use a pre-trained ResNet50 model, which can classify a variety of images into different categories. We then serve this model in two different setups — FastAPI and TensorFlow Serving, which share some commonalities in their setups:
- Docker to containerize the environment.
- Kubernetes to orchestrate a cluster of container nodes for scalability. We use Kubernetes Engine (GKE) to manage this.
- GitHub Actions to automatically roll out deployments on GKE.
Our deployment platform (nodes on the Kubernetes Cluster) is CPU-based. We don’t employ GPUs at any stage of our processes. To further optimize the runtime of the model served with FastAPI, we use ONNX. This notebook provides a comparison between latency of the ONNX model and the original TensorFlow model. TensorFlow Serving doesn’t yet allow us to serve ONNX models, but we can still build a CPU-optimized TensorFlow Serving image and take advantage of a few other options which can reduce the latency and boost the overall throughput of the system. We will discuss these later in the post.
You can find all the code and learn how the deployments were performed in the following repositories:
- GitHub – sayakpaul/ml-deployment-k8s-fastapi: This project shows how to serve an ONNX-optimized image classification model as a web service with FastAPI, Docker, and Kubernetes.
- GitHub – deep-diver/ml-deployment-k8s-tfserving: This project shows how to serve an TF based image classification model as a web service with TFServing, Docker, and Kubernetes(GKE).
In the repositories, you’ll find example notebooks and detailed setup instructions for playing around with the code. As such, we won’t be discussing the code line by line but rather shed light on the most important parts when necessary.
Throughout the rest of this post, we’ll discuss the key considerations for the deployment experiments respective to FastAPI and TensorFlow Serving, including their motivation, limitations, and our experimental results.
With the emergence of serverless offerings like Vertex AI, it has never been easier to deploy Machine Learning (ML) models and scale them securely and reliably. These services help reduce the time-to-market tremendously and increase overall developer productivity. That said, there might still be instances where you’d like more granular control over things. This is one of the reasons why we wanted to do these experiments in the first place.
Considerations
FastAPI and TensorFlow Serving have their own constraints and design choices that can impact a deployment. In this section, we provide a concise overview of these considerations.
Framework choice: FastAPI has quickly become a good tool for deploying REST APIs. Besides, it leverages a C++ based event system which has been proven to be performant in Node.js. On the other hand, TensorFlow Serving is a production-ready framework to deploy standard TensorFlow models supporting both REST and gRPC based interfaces at the same time. Since FastAPI is not a battle-tested framework for ML deployment but many organizations use it for that purpose, we wanted to compare the performance between it and TensorFlow Serving.
Deployment infrastructure: We chose GKE because Kubernetes is the de facto deployment platform in the modern IT industry (when using GCP), and GKE lets us focus on the ML parts without worrying about the infrastructure since it is a fully managed Google Cloud Platform (GCP) service. Our main interest is in how to deploy models for CPU-based environments, so we have prepared a CPU-optimized ONNX model for the FastAPI server and a CPU-optimized TensorFlow Serving image.
Trade-off between more or fewer servers: We started experiments for both FastAPI and TensorFlow Serving setups with the simplest possible VMs equipped with 2vCPU and 4GB RAM, then we gradually upgraded the specification up to 8vCPU and 64GB RAM. On the other hand, we decreased the number of nodes in the Kubernetes cluster from 8 to 2 because it is a trade-off between costs to deploy cheaper servers versus fewer expensive servers.
Options to benefit multi-core environments: We wanted to see if high-end VMs can outperform simple VMs with options to take advantage of the multi-core environment even though there are fewer nodes. To this end, we experimented with different workers using uvicorn and gunicorn for FastAPI deployment, with the number of inter_op_parallelism and intra_op_parallelism threads for TensorFlow Serving deployment set according to the number of CPU cores.
Dynamic batching and other considerations: Modern ML frameworks such as TensorFlow Serving usually support dynamic batching, initial model warm-up, multiple deployments of multiple versions of different models, and more out of the box. For our purpose of online prediction, we have not tested these features carefully. However, according to the official document, dynamic batching capability is also worth exploring to enhance the performance. We have seen that the default batching configuration could reduce the latency a little, even though the results of that are not included in this blog post.
Implementing these features in a FastAPI server by yourself is nontrivial, so it is an advantage to use TensorFlow Serving instead of a pure REST API server framework such as FastAPI.
Experiments
We have prepared the following environments. We used a uvicorn worker in the smallest machine of 2vCPU and 4GB RAM, but we chose gunicorn over uvicorn in a bigger machine. It is recommended to use uvicorn in a Kubernetes environment but gunicorn is preferred in some situations as per the official FastAPI’s documentation, so we wanted to explore both.
The number of gunicorn workers is set with the formula of (2 x $num_cores) + 1 according to the official guideline for FastAPI. In TensorFlow Serving, the number of intra_op_parallelism_threads is set equal to the number of CPU cores, while the number of inter_op_parallelism_threads is set from 2 to 8 for experimental purposes as it controls the number of threads to parallelize the execution of independent operations. Below we provide the details on the adjustments we performed on the number of vCPUs, RAM size, and the number of nodes for each Kubernetes cluster. Note that the number of vCPUs and the RAM size is applicable for the cluster nodes individually.
The load tests are conducted using Locust. We have run each load test for 5 minutes. We spawned requests every second to clearly see how TensorFlow Serving behaves with the increasing number of clients. So you can assume that requests/second doesn’t reflect the real-world situation where clients try to send requests at any time.
2vCPUs, 4GB RAM, 8 Nodes:
We have load-tested FastAPI deployment with the 1, 2, and 4 of uvicorn workers, and the number of inter_op_parallelism_threads is set to 2, 4, and 8 for the TensorFlow Serving load test.
4vCPUs, 8GB RAM, 4 Nodes:
According to the formula, the number of gunicorn workers is set to 7 for FastAPI deployment and the number of inter_op_parallelism_threads is set to 2, 4, and 8 for the TensorFlow Serving load test.
8vCPUs, 16GB RAM, 2 Nodes:
According to the formula, the number of gunicorn workers is set to 17 for FastAPI deployment and the number of inter_op_parallelism_threads is set to 2, 4, and 8 for the TensorFlow Serving load test.
8vCPUs, 64GB RAM, 2 Nodes:
According to the formula, the number of gunicorn workers is set to 7 for FastAPI deployment and the number of inter_op_parallelism_threads is set to 2, 4, and 8 for the TensorFlow Serving load test.
You can find code for experimenting with these different configurations in the above-mentioned repositories. The deployment for each experiment is provisioned through Kustomize to overlay the base configurations, and file-based configurations are injected through ConfigMap.
Results
The result of all load tests on the various configurations can be found in the above-mentioned repositories. This section only includes the best results from FastAPI and TensorFlow Serving. Figure 1 shows such results. Following are the configurations we found to be the best ones for FastAPI and TensorFlow Serving, respectively:
- FastAPI: 8 nodes, 2 uvicorn workers, 2vCPUs, 4GB RAM
- TensorFlow Serving: 2 nodes, 8 intra_op_parallelism_threads, 8 inter_op_parallelism_threads, 8vCPUs, 16GB RAM
The hardware is based on the E2 series of VMs provided by GCP.
Below we present various results we got with these two configurations. We also included additional results to show how TensorFlow Serving behaves on a VM equipped with higher RAM capacity in terms of latency and throughput.
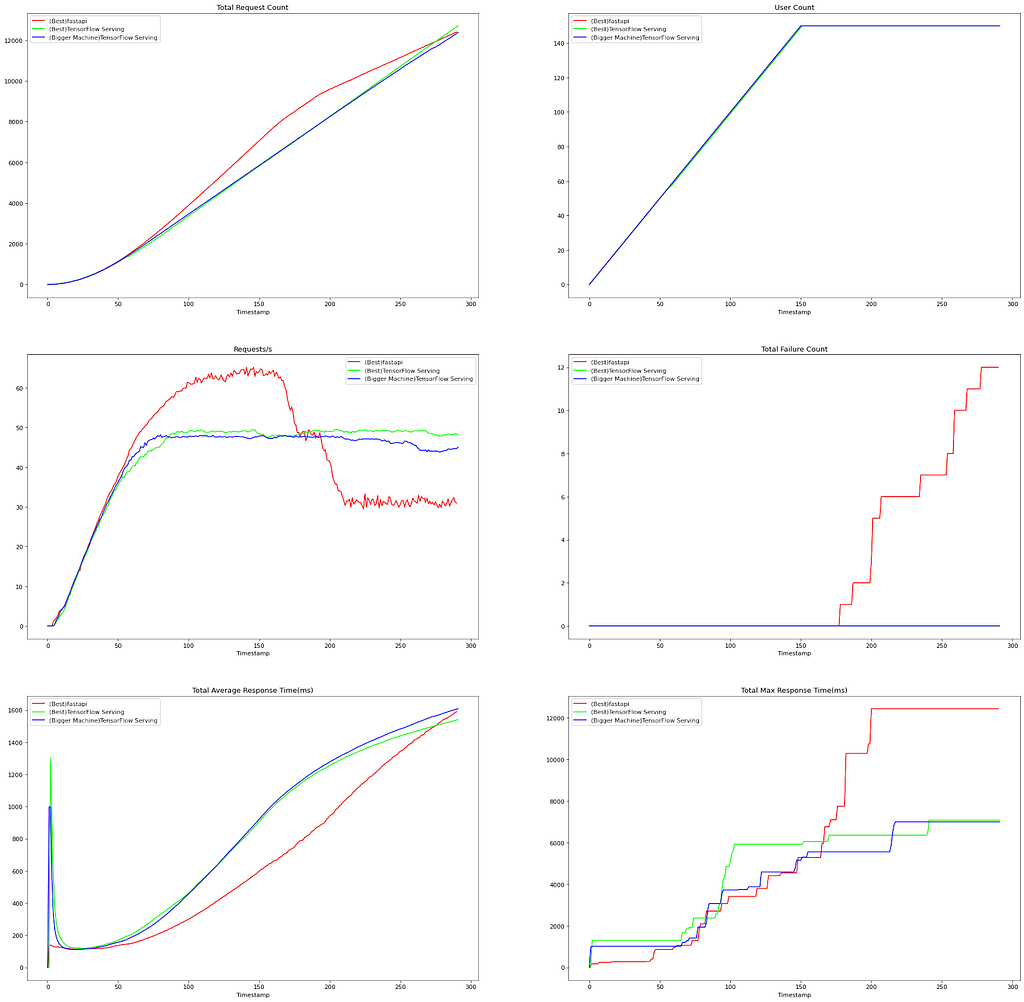
We have observed the following aspects individually for both deployments by picking the best options.
- FastAPI tends to perform better when deployed on more, smaller (less CPU and RAM) machines, and uvicorn workers seem to work better than gunicorn workers in the Kubernetes environment.
- TensorFlow Serving is more efficient when deployed on fewer, larger (more CPU and RAM) machines. It is important to find the right number of inter_op_parallelism_threads with experimentation. With a higher number, better performance is not always guaranteed, even when the nodes are equipped with high-capacity hardware.
For the comparison between both deployments, TensorFlow Serving focuses more on reliability than throughput performance. As shown in Figure 1, Requests/second of TensorFlow Serving is a little lower than ONNX optimized FastAPI deployment. We believe it sacrifices some throughput performance to achieve reliability. This is the expected behavior of TensorFlow Serving, as stated in the official document. On the other hand, it seems FastAPI is more capable of handling more requests than TensorFlow Serving, but the latency is not stable as some requests are handled with irregularly higher response time, and even some failures are observed as the number of requests increases.
Even though handling as many requests as possible is important, keeping the server as reliable as possible is also substantially important when dealing with a production system. There is a trade-off between performance and reliability, so you must be careful to choose the right one. However, it seems like the throughput performance of TensorFlow Serving is close enough to FastAPI. Also, since we have tested a simple image classification model on a CPU-based deployment scenario, FastAPI with an optimized ONNX model might be a good option. However, if you want to factor in richer features such as dynamic batching and sharing GPU resources efficiently between models, we believe TensorFlow Serving is the right one to choose.
Note on gRPC and TensorFlow Serving
We are dealing with an image classification model for the deployments, and the input to the model will include images. Hence the size of the request payload can spiral up depending on the image resolution and fidelity. Therefore it’s particularly important to ensure the message transmission is as lightweight as possible. Generally, message transmission is quite a bit faster in gRPC than REST. This post provides a good discussion on the main differences between REST and gRPC APIs.
TensorFlow Serving can serve a model with gRPC seamlessly, but comparing the performance of a gRPC API and REST API is non-trivial. This is why we did not include that in this post. The interested readers can check out this repository that follows a similar setup but uses a gRPC server instead.
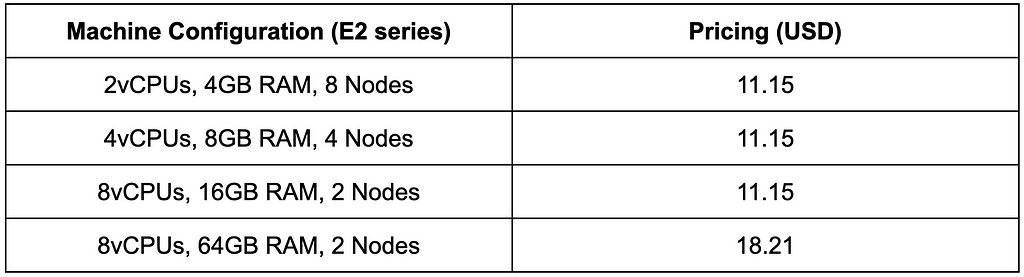
Costs
We used the GCP cost estimator for this purpose. Pricing for each experiment configuration was assumed to be live for 24 hours per month (which was sufficient for our experiments).
Conclusion
In this post, we discussed some crucial lessons we learned from our experience of load-testing a standard image classification model. We considered two industry-grade frameworks for exposing the model to the end-users — FastAPI and TensorFlow Serving. While our setup for performing the load tests may not fully resemble what happens in the wild, we hope that our findings will at least act as a good starting point for the community. Even though the post demonstrated our approaches with an image classification model, the approaches should be fairly task-agnostic.
In the interest of brevity, we didn’t do much to push further the efficiency aspects of the model in both the APIs. With modern CPUs, software stack, and OS-level optimizations, it’s possible to improve the latency and throughput of the model. We redirect the interested reader to the following resources that might be relevant:
- Scaling up BERT-like model Inference on modern CPU — Part 1
- Scaling up BERT-like model Inference on modern CPU — Part 2
- Load testing and monitoring AI Platform models
- Best practices for performance and cost optimization for machine learning
Acknowledgements
We are grateful to the ML Developer Programs Team at Google that provided GCP credits for supporting our experiments. We also thank Hannes Hapke and Robert Crowe for providing us with helpful feedback and guidance.
![]()
Load-testing TensorFlow Serving and FastAPI on GKE was originally published in Google Developers Experts on Medium, where people are continuing the conversation by highlighting and responding to this story.





{kind=link}