Check out GitHub: https://github.com/apache/incubator-seatunnel

SeaTunnel Connector Acess Plan
During the recent live event of the SeaTunnel Connector Access Plan, Beluga open source engineer Wang Hailin shared the “SeaTunnel Connector Access Plan and Development Guide to Avoiding Pit,” and taught everyone how to develop a connector from scratch, including the whole process – from preparation to testing, and final PR.
Instructors

Wang Hailin, Beluga Open Source senior engineer
Wailin Hailin is an open source enthusiast, SkyWalking Committer, and DolphinScheduler and SeaTunnel contributor. His current work focuses on performance monitoring, data processing, and more. He likes to study related technical implementations and participate in community exchanges and contributions.
This presentation is divided into 5 parts:
-
About the connector access incentive program
-
Preparation before claiming/developing connector
-
Small things in development
-
Considerations for writing E2E Tests
-
Preparations to submit a PR
1. About the Connector Access Incentive Plan
Firstly, let me introduce the SeaTunnel Connector Access Incentive Program, and the steps to develop a connector from start to finish (even for novices). This includes the whole process of preparation for development, testing, and final PR.
The SeaTunnel community released a new connector API not long ago, which supports running on various engines, including Flink, Spark, and more. This eliminates the need for repeated development of the old version.
After the new API is released, the old connector needs to be migrated, or the new connector should be supported.
In order to motivate the community to actively participate in the SeaTunnel Connector Access work and help build SeaTunnel into a more efficient data integration platform, the SeaTunnel community initiated activities, sponsored by Beluga Open Source.
The activities have three modes: simple, medium, and hard for the task of accessing the connector. The threshold is low.
You can see which tasks need to be claimed on the activity issue list, as well as segmentation based on difficulty and priority. You can choose the activity you are comfortable with. You can start contributing based on the difficulty level.

The ecological construction of SeaTunnel can become more complete and advanced only with the help of your contributions. You are welcome to participate actively.
In order to express our gratitude, our event has set up a link where points can be exchanged for physical prizes. The more points you get, the more prized you can win!
Presently, we’ve seen many small partners participate in the event and submit their connectors. It’s not too late to join as there is still a significant period of time before the event ends. Based on the difficulty of the activity, the deadline may be relaxed or extended.

2. Preparations Before Claiming/Developing Connectors
So, how do you get involved with this amazing activity?
By first getting to know the basics of a connector.
01. What is a connector?
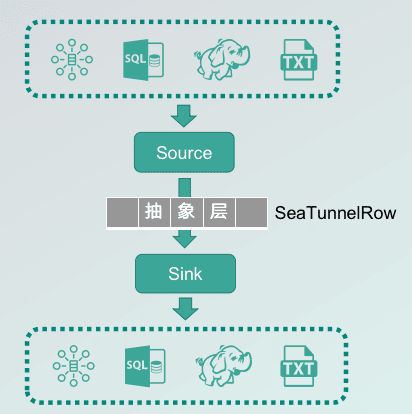
A connector is composed of Source and SInk (Source + Sink).
In the above figure, the connectors are connected to various data sources at the upper and lower layers. The source is responsible for reading data from external data sources, while the sink is responsible for writing data to external sources.
There is also an abstraction layer between the source and the sink.
Through this abstraction later, the data types of various data sources can be uniformly converted into the data format of SeaTunnelRow. This allows users to arbitrarily assemble various sources and sinks, so as to realize the integration of heterogeneous data sources, and data synchronization between multiple data sources.
02. How to claim a connector
After understanding the basic concepts, the next step is to claim the connector.
GitHub link: https://github.com/apache/incubator-seatunnel/issues/1946
You can use the above-mentioned GitHub link to see our plans for connecting to the connector. You can make any additions at any time.
First, find a connector that has not been claimed. To avoid conflicts, search the entire issue to see if anyone has submitted a PR.
After claiming the connector, we suggest that you create an issue of the corresponding feature, synchronize the problems you encountered in the development, and discuss the design of your solution.
If you encounter any problems and need help, you can describe them in the issue, and the community can take it up together. Participate in the discussions to help solve the problem. This is also added to the record of the function implementation process, which makes it easy to refer to when maintaining and modifying in the future.
03. Compile the project
After claiming the connector, it’s time to prepare the development environment.
First, fork the SeaTunnel project to the local development environment and compile it.
Here’s the compilation reference documentation: https://github.com/apache/incubator-seatunnel/blob/dev/docs/en/contribution/setup.md
Run the testcase in the documentation after the compilation is successful. You might encounter some issues/problems during the first contact compilation process, such as the following compilation errors:
![]()

The solution to the above exceptions:
-
rm {your_maven_dir}/repository/org/apache/seatunnel
-
./mvnw clean
-
Recompile it
04. Understand Connector related code structure
The success of project compilation means that the development environment is ready. Next, let’s take a look at the project code structure and API interface structure of the connector.
Engineering Code structure
After the project is compiled, there are three parts related to the connector. The first part is the code implementation and dependency management of the new connector module.
-
seatunnel-connectors-v2 stores the connector submodule
-
seatunnel-connectors-v2-dist manages connectors-v2 maven dependencies
The second part is the example. When testing locally, you can build a corresponding case on the example to test the connector.
-
seatunnel-flink-connector-v2-example example running on Flink
-
seatunnel-spark-connector-v2-example example running on Spark
The third part is the E2E-testcase: adding targeted test cases on the respective running engines of Spark or Flink, and verifying the functional logic of the connector through automated testing.
-
seatunnel-flink-connector-v2-e2e testcase running on Flink
-
seatunnel-spark-connector-v2-e2e testcase running on Spark
Code structure (interfaces, base classes)
The public interfaces and base classes used in the development are fully described in our readme. For example, API function usage scenarios.
Here’s the link: https://github.com/apache/incubator-seatunnel/blob/dev/seatunnel-connectors-v2/README.en.md
05. See how other people develop connectors
After going through the above steps, don’t rush to start the work. Instead, first, check out how others do it.
We strongly recommend you check out the connector novice development tutorial shared on the community official account:
- [SeaTunnel Connector Minimalist Development Process]
- [New API Connector Development Analysis]
- [The way of decoupling Apache SeaTunnel (Incubating) and the computing engine – what we’ve done to reconstruct the API]
In addition, you can refer to the merged Connector code to see the scope of changes, the public interfaces and dependencies used, and the test cases.
https://github.com/apache/incubator-seatunnel/pulls?q=is:pr+is:merged+label:connectors-v2
3. Small Issues/Task During Development
Next, you have to officially enter the connector development process. What problems may be encountered during the development process?
The connector is divided into the source and sink ends — you can choose either one or both.
01. Source-related development
The first thing to pay attention to when developing a source is to determine the reading mode of the source: is it streaming or batch? Is support still required?
Use the Source#getBoundedness interface to mark the modes supported by the source.
For example, Kafka naturally supports streaming reading, but it can also support batch mode reading by obtaining lastOffset in the source.
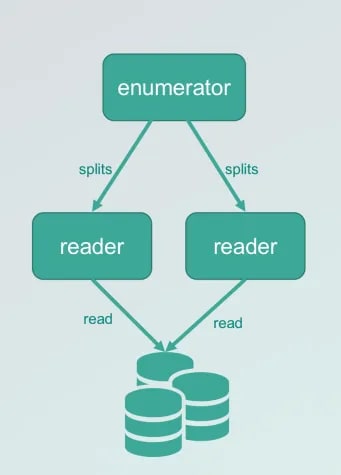
Another question to be aware of: does the source require concurrent reads? If it is single concurrency, after the source is started, a reader will be created to read the data from the data source.
If you want to achieve multi-concurrency, you need to implement an enumerator interface through which data blocks are allocated to readers, and the readers each read their allocated data blocks.
For example, the Kafka source uses partition sharding, and the jdbc source uses fields for range query sharding. It should be noted here that if it is a concurrent reading method, the stability of the data block distribution rules must be ensured.
This is because currently, the connector has a corresponding enumerator on each shard in actual operation, and it is necessary to ensure that the enumerator has data in each shard.
Thirdly, does the source need to support resumable transfer/state restoration?
If you want to support this, you need to implement:
-
Source#restoreEnumerator: restore state
-
Enumerator#snapshotState: storage shard allocation
-
Reader#snapshotState: stores the read position
02. Sink-related development
If the sink is a common sink implementation, use Sink#createWriter to write our data according to the concurrency of the source.
If you need to support failure recovery, you need to implement:
-
Sink#restoreWriter: restore state
-
Writer#snapshotState: snapshot state
If you want to support two-phase commit, you need to implement the following interfaces:
-
Sink#createCommitter
-
Writer#prepareCommit: pre-commit
-
Committer#commit: abort Phase 2 commit

03. Connector related
Next, let’s take a look at some of the general problems, especially when the first contribution is made with different styles for each environment, there are often various problems. Therefore, it is recommended that you import tools/checkstyle/checkStyle.xml from the project during development, and use a unified coding format.
Whether it is a source or a sink, it will involve defining the data format. The community is pushing for a unified data format definition.
-
To define Schema, please refer to PR: https://github.com/apache/incubator-seatunnel/pull/2392
-
To define Format, please refer to PR: https://github.com/apache/incubator-seatunnel/pull/2435
If you feel that the compilation speed is slow, you can temporarily annotate the old version of the connector-related module in order to speed up both development and debugging.
04. How to seek help
When you encounter problems during development and need help, you can:
-
Describe the problem in your Issue and call active contributors
-
Discuss on mailing lists and Slack
-
Communicate through the WeChat group (if you have not joined, please follow the SeaTunnel official account to join the group, and add a small assistant WeChat seatunnel1)
-
There may be a community docking group for docking third-party components (allowing you to do more with less).
4. Notes on Writing E2E Tests
E2E testing is very important. It is often called the gatekeeper of connector quality.
This is because, if the connector you wrote is not tested, it could be difficult for the community to judge whether there are problems with the implementation of the static code.
Therefore, E2E testing is not only functional verification but also a process of checking data logic, which can reduce the pressure on the community to review code and ensure basic functional correctness.
In E2E testing, these are some of the problems that may be encountered:
01. E2E Failed – Test Case Network Address Conflict
Because the E2E network deployment structure has the following characteristics:
-
External components that Spark, Flink, and e2e-testcase depend on (for example, MySQL), use the container networkAliases(host) as the access address
-
e2e-testcase on both sides of Spark and Flink may run in parallel under the same host
-
External components that e2e-testcase depends on, need to map ports to hosts for e2e-testcase to access
Therefore, E2E has to pay attention to:
-
The external components e2e-testcase depends on the ports mapped to the external networkAliases, and so cannot be the same in the testcases on both sides of Spark and Flink
-
e2e-testcase uses localhost, the above-mapped port, to access external components
-
e2e’s configuration file uses networkAliases(host), the external components that depend on port access in the container
Here’s the E2E Testcase reference PR: https://github.com/apache/incubator-seatunnel/pull/2429
02. E2E failure – Spark jar package conflict
Spark uses the parent first class loader by default, which may conflict with the package referenced by the connector. For this, the userClassPathFirst classloader can be configured in the Connector environment.
However, the current packaging structure of SeaTunnel will cause userClassPathFirst to not work properly, so we created an issue, https://github.com/apache/incubator-seatunnel/pull/2474, to track this issue. Everyone is welcome to contribute solutions.
Currently, this can only be resolved by replacing conflicting packages in the spark jars directory with the documentation.
03. E2E failure – Connector jar package conflict
Both the old and new versions of Connector are dependent on the E2E project and cause conflicts.
PR https://github.com/apache/incubator-seatunnel/pull/2414 has resolved this issue.
Version conflict between Connector-v2:
-
Mainly occurs during E2E, because the E2E project depends on all Connectors
-
We may plan to provide a separate test project for each Connector (or version) in the future
04. Insufficient E2E – Sink Logic Verification
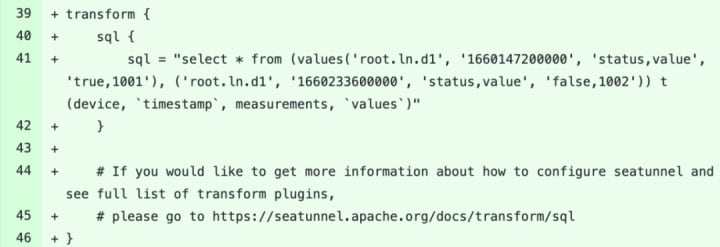
The FakeSource of the Connector-v2 version can only generate random data of a few fixed columns at present, and the community partners are optimizing it to make it better. https://github.com/apache/incubator-seatunnel/pull/2406
That said, we can temporarily solve this problem by simulating the data of the specified content through Transform#sql:
05. Insufficient E2E – Source validation data
The Assert Sink can configure column rules, but cannot do row-level value checking. For this problem, you can temporarily use other connector sinks with external storage for query verification data.
06. E2E stability improvement
In many cases, when E2E starts, you might use Thread.sleep to wait for resource initialization. Here, sleep will cause fewer initialization failures but more time-wasting issues.
In addition, due to the instability of resources, network, and other issues, you might be able to run it now but not later.
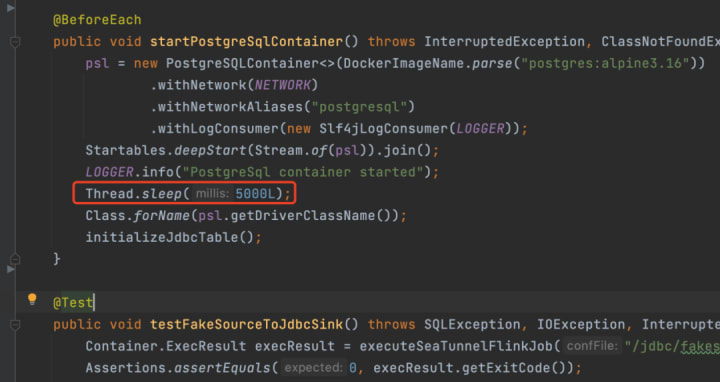
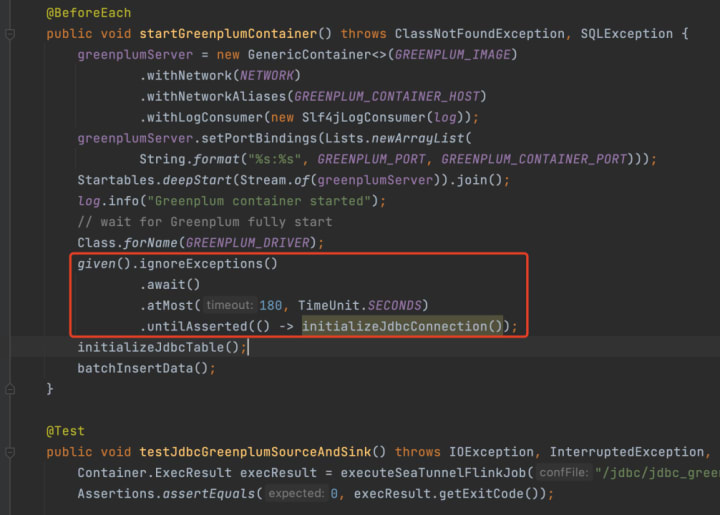
To avoid this problem, Thread.sleep can be replaced with Awaitility.
07. A method to speed up E2E
At present, I see that most people run E2E tests separately for both source and sink. If you want to speed up the PR process, it is recommended that you combine both the sink and source into one E2E testcase for verification, and run the testcase only once.
5. Checks Before Submitting a PR
After completing the previous steps, please make sure you do some checks before submitting PR – including the following aspects:
Complete recompile project:
-
Codestyle validation, dependency validation
-
The successful compilation before does not mean that it can be compiled successfully now
Running E2E locally succeeds:
- Both Flink and Spark are verified
Supplement or change the document and review it again before submitting:
-
Review for places not covered by tests
-
Places that hav been reviewed before and needs to be checked again
-
Review for including all files, not just code
The above operations and steps can greatly save CI resources, speed up PR Merged, and reduce the costs of community reviews.
Apache SeaTunnel
– Keep in touch –
Come and Grow With the Community!
Apache SeaTunnel (incubating) is a distributed, high-performance, easily scalable, data integration platform for massive data (offline & real-time) synchronization and transformation.
-
Warehouse address: https://github.com/apache/incubator-seatunnel
-
Proposal: https://cwiki.apache.org/confluence/display/INCUBATOR/SeaTunnelProposal
-
Apache SeaTunnel(Incubating) 2.1.0 download address: https://seatunnel.apache.org/download
We are more than happy to welcome more people to join!
Though the journey of SeaTunnel (formerly Waterdrop) has just begun after being able to enter the Apache Incubator, the development and growth of the community require that more people join.
We believe that under the guidance of The Apache Way, such as “Community Over Code,” “Open and Cooperation,” “Meritocracy” (meritocracy), and “Diversity and Consensus Decision Making,” we will usher in more diverse and inclusive community ecology, and jointly build the technological progress brought by the spirit of open source!
We sincerely invite all partners who are interested in making local open source to join the SeaTunnel contributor family and build open source together!
-
Submit issues and suggestions: https://github.com/apache/incubator-seatunnel/issues
-
Contributed code: https://github.com/apache/incubator-seatunnel/pulls
-
Subscribe to the community development mailing list: dev-subscribe@seatunnel.apache.org
-
Development mailing list: dev@seatunnel.apache.org
-
Join Slack:
-
https://join.slack.com/t/apacheseatunnel/shared_invite/zt-1f6uymuh1-KXbFKYoJ8yYy8_4R66yJNA
-
Follow on Twitter: https://twitter.com/ASFSeaTunnel