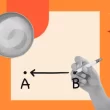
Hi,
I am trying to read the characters from the image, which has characters with black color in the background. Attaching the code which i used to extract, currently its giving the partial output. Can you help me to guide how to make it accurate?
import pytesseract
from PIL import Image
pytesseract.pytesseract.tesseract_cmd = ‘C:UsersM562765AppDataLocalProgramsTesseract-OCRtesseract.exe’
Paths to your images
image_paths = [
‘C:/Users/M562765/Downloads/Unable-images/Unable/crop1.jpg’]
Function to process an image and extract text
def extract_text_from_image(image_path):
# Open the image
img = Image.open(image_path)
# Use pytesseract to perform OCR
extracted_text = pytesseract.image_to_string(img, config='--psm 6') # PSM 6 assumes a block of text
return extracted_text.strip()
Process all images and print results
for img_path in image_paths:
text = extract_text_from_image(img_path)
print(f”Text extracted from {img_path}: {text}”)