

1. Executive Summary
JAX, a high-performance numerical computation library, is celebrated for its XLA-accelerated compute capabilities, which often surpass other frameworks in raw computational speed. However, this inherent speed frequently exposes data loading as a critical bottleneck, hindering the full utilization of powerful accelerators like GPUs and TPUs. Traditionally, JAX users have resorted to intricate methods, often stitching together disparate libraries such as TensorFlow Datasets, tf.data, torch.utils.data, or even implementing manual batching with NumPy. These ad-hoc solutions introduce significant boilerplate code, compromise reproducibility, and struggle with efficient multi-process or asynchronous data handling.
Addressing this fundamental challenge, jax-dataloader and Grain emerge as two prominent, purpose-built solutions. jax-dataloader offers a lightweight, zero-dependency, and Python-native approach, providing a familiar PyTorch-like API for seamless integration into JAX pipelines. In contrast, Grain, a Google-backed library, is engineered for enterprise-grade robustness, emphasizing determinism, resilience to preemption, and deep integration with the broader JAX and Google Cloud ecosystem, particularly for large-scale distributed training on TPUs.
Analysis reveals that jax-dataloader delivers substantial performance improvements, demonstrating up to a 3.1x speedup over manual NumPy batching and comparable performance to PyTorch’s DataLoader in certain benchmarks. Grain, while not directly benchmarked against jax-dataloader in available data, is designed for optimal performance in distributed, fault-tolerant environments. The distinct design philosophies of these tools reflect a maturing JAX ecosystem that is now offering specialized solutions tailored to different scales and operational requirements. jax-dataloader caters to users seeking a familiar, lightweight, and performant experience, while Grain provides a robust, highly scalable, and fault-tolerant solution for demanding distributed workloads.
This report will delve into the intricacies of JAX’s data loading challenges, explore the architectural strengths and practical applications of jax-dataloader and Grain, provide a comparative analysis, and discuss advanced considerations for distributed data loading, ultimately offering guidance on selecting the optimal solution for various JAX-based machine learning projects.
2. The JAX Data Loading Challenge: Bottlenecks and Requirements
JAX has garnered significant acclaim for its “blazing-fast XLA-accelerated compute” and “unmatched” computational speed, particularly when leveraging hardware accelerators. This exceptional processing capability, however, paradoxically illuminates a critical weakness in many JAX-based machine learning workflows: the data loading pipeline. When the computational core runs at unparalleled speeds, the slower process of fetching, preprocessing, and transferring data to the accelerators becomes the primary bottleneck, preventing the full utilization of expensive GPU and TPU resources.
Historically, JAX users have navigated this challenge by “stitching together multiple libraries like TensorFlow Datasets, tf.data, torch.utils.data, or even manually batching with NumPy”. These fragmented approaches, while functional, introduce a host of limitations. The integration of disparate libraries often results in extensive boilerplate code, making data pipelines cumbersome to develop, understand, and maintain. Such ad-hoc solutions frequently lack deterministic behavior, undermining scientific reproducibility — a crucial aspect of machine learning research and reliable production deployments. Furthermore, efficiently managing data loading across multiple processes or asynchronously to continuously feed accelerators proves to be a complex and error-prone endeavor.1 The absence of a unified, native solution also complicates performance profiling and debugging, leading to a common frustration: “You spend more time preparing the data than training the model”.
The recognized need for a robust, JAX-native data loading solution has driven the development of tools that embody specific ideal characteristics. Such a solution should prioritize composability, allowing its modules to be separable and interchangeable, enabling users to customize individual stages of the pipeline. It must deliver high performance, capable of prefetching data sufficiently to prevent GPU starvation. A minimal dependency footprint is also highly desirable, avoiding unnecessary external framework baggage. Crucially, the loader needs to ensure reproducibility and determinism, which are paramount for both research integrity and production stability. It should be plug-and-play, integrating seamlessly with any JAX pipeline, and support diverse data types, from images and natural language processing (NLP) datasets to custom input pipelines. Finally, robust multi-processing and prefetching capabilities are essential for scaling training to large datasets and distributed environments.
The recognized absence of a performant, composable, plug-and-play DataLoader akin to PyTorch’s, as explicitly stated in the problem description, highlights a specific area where the JAX ecosystem has been maturing. JAX itself is intentionally “narrowly-scoped,” focusing on efficient array operations and program transformations like jit, grad, and vmap.2 It deliberately leaves higher-level concerns, such as comprehensive data loading, to its “evolving ecosystem”.5 This design choice, while empowering JAX with unparalleled flexibility and performance in its core domain, initially created a usability hurdle for end-to-end machine learning workflows when compared to more opinionated frameworks like PyTorch or TensorFlow, which bundle extensive utilities. The emergence of specialized tools like jax-dataloader and Grain directly addresses this critical usability and performance gap. Their development signifies a natural and necessary progression for the JAX ecosystem, where fundamental infrastructure needs are being systematically filled with specialized, high-performance tools, thereby enhancing JAX’s overall utility and accessibility for complex machine learning tasks.
3. jax-dataloader: A Native Solution for JAX
jax-dataloader was developed with the explicit motivation of resolving the persistent “bottleneck: data loading” problem encountered when working with large datasets in JAX. The tool is designed to be “easy-to-use, zero-dependency, high-performance,” built “natively in Python + NumPy with seamless JAX compatibility”. Its core philosophy centers on providing a “batteries-included” data loader experience, reminiscent of PyTorch’s DataLoader, while strictly adhering to JAX’s minimalist principles.7 This includes supporting both map-style and iterable-style datasets, offering multi-processing and prefetching capabilities to prevent GPU starvation, and prioritizing reproducibility and determinism.
The architecture of jax-dataloader is fundamentally modular, separating concerns into a clear, composable pipeline: Dataset → Sampler → Collate → Prefetch → Device Transfer. This design allows users to customize or replace any stage, providing significant flexibility for diverse data loading requirements.
The key components facilitate practical usage within JAX workflows:
- Dataset: Users extend jax_dataloader.Dataset, implementing __getitem__ and __len__ methods to define how individual data samples are retrieved and the total size of the dataset, respectively.
- Sampler: This component dictates the strategy for shuffling and batching data, such as using a RandomSampler.
- DataLoader: As the central orchestrator, the DataLoader class takes various parameters, including the dataset, sampler, num_workers (for parallel data loading), collate_fn (for custom batching logic), prefetch_factor (for controlling prefetching depth), and to_jax (for automatic device transfer).8 It also features a backend parameter, allowing users to specify ‘jax’, ‘pytorch’, or ‘tensorflow’ for data loading, though PyTorch datasets are specifically noted to work only with the ‘pytorch’ backend.7 jax-dataloader supports wrapping jax.numpy.array into an ArrayDataset and can directly ingest datasets from Hugging Face (datasets.Dataset), PyTorch (torch.utils.data.Dataset), and TensorFlow (tf.data.Dataset), enhancing its interoperability.7
- Prefetching: Under the hood, jax-dataloader employs multi-threaded and optionally multi-process prefetching mechanisms. This ensures that data is prepared and ready before the accelerators require it, preventing GPU starvation and leading to significant throughput improvements, with benchmarks showing peak throughput improved by up to 3x.
- Device Transfer: The to_jax=True parameter within the DataLoader and explicit use of jax.device_put are crucial for efficiently transferring NumPy arrays to JAX devices, bridging the gap between host-side data preparation and device-side computation.
jax-dataloader incorporates several advanced features and customization options, including custom collate_fn for handling complex data structures like padding or nested elements, built-in image transforms, deterministic sampling through jdl.manual_seed for reproducibility, fault-tolerant multiprocessing, and synthetic data generation for benchmarking purposes.7
The development journey of jax-dataloader involved navigating complex edge cases, particularly those related to “Multiprocessing + fork behavior in JAX,” “Randomness propagation (RNG splitting),” and “Memory sharing via shared buffers vs serialization”. Successfully addressing these challenges was critical to producing a “clean, extensible pipeline” suitable for production environments. Installation is straightforward via pip install jax-dataloader, and the library maintains minimal dependencies, with optional installs for PyTorch, Hugging Face, or TensorFlow integrations if needed.7
The design of jax-dataloader to be “zero-dependency” and built “natively in Python + NumPy” represents a deliberate strategic choice. This approach aligns with JAX’s own minimalist philosophy, which focuses on core numerical computation and transformations rather than bundling extensive higher-level utilities.5 By avoiding dependencies on large machine learning frameworks like TensorFlow or PyTorch, jax-dataloader sidesteps their potential overheads and versioning complexities, providing a lightweight and self-contained solution. Concurrently, its adoption of a “PyTorch-like API” is a clever move to lower the barrier to entry for the substantial community of PyTorch developers. Many machine learning practitioners are familiar with PyTorch’s data loading paradigms, and offering a similar interface in JAX makes the transition smoother and more intuitive.3 This dual strategy positions jax-dataloader as both a highly accessible and clean solution, fostering broader adoption of JAX by addressing a common pain point with a familiar yet JAX-native approach.
Furthermore, the challenges encountered during jax-dataloader’s development, such as “Randomness propagation (RNG splitting)” and “Multiprocessing + fork behavior in JAX”, underscore a deeper architectural consideration within JAX. JAX’s functional programming paradigm, characterized by immutable arrays, pure functions, and explicit handling of pseudo-random number generator (PRNG) keys 3, often contrasts with the stateful nature of traditional data iteration. Successfully adapting a stateful process like data loading to JAX’s stateless, compiled execution model necessitates a robust implementation of JAX-idiomatic patterns. The ability of jax-dataloader to effectively manage these complexities, particularly in distributed or concurrent settings, means it is more than just a fast loader; it is a JAX-native fast loader. This ensures that the data pipeline does not introduce non-JAX-idiomatic behavior that could lead to subtle bugs or performance regressions within compiled JAX code, thereby contributing significantly to the stability and reproducibility of JAX applications.
4. Grain: Google’s Data Loading Library for JAX
Grain is a specialized library developed by Google, explicitly designed “for reading data for training and evaluating JAX models”.10 It is recognized as a key data loading tool within the broader JAX ecosystem.5 At its core, Grain embodies principles of being “open source, fast, and deterministic”.10 Its design prioritizes power, allowing users to incorporate arbitrary Python transformations; flexibility, through modular and overrideable components; resilience to preemptions, by maintaining minimal checkpoint sizes and enabling seamless resumption; and performance, having been rigorously tested across various data modalities including text, audio, images, and videos.10 A notable design choice is its commitment to “minimal dependencies,” specifically avoiding a direct reliance on TensorFlow, even when interacting with TensorFlow-related data formats.10
The library’s functionality is built upon several core concepts and components:
- DataLoader: This is the central class responsible for orchestrating the reading and transformation of input records. It integrates a Sampler, a DataSource, and applies various Transformations to produce the output elements. The DataLoader also manages the launching of child processes for parallelizing the input pipeline, collecting outputs, and gracefully shutting down these processes.11
- Sampler: An iterator that dictates the order in which records are read. It produces RecordMetadata objects, which contain crucial information for each record: a monotonically increasing index (unique and used for checkpointing), a record_key (a reference to the record in the serialized file format), and a rng (a per-record Random Number Generator for applying random transformations).11 Grain provides an IndexSampler implementation to manage these sampling strategies.11
- DataSource: This component handles the direct reading of individual records from underlying files or storage systems. Grain offers ArrayRecordDataSource for reading from ArrayRecord files and, notably, a tfds.data_source for TensorFlow Datasets that operates without requiring a TensorFlow dependency.11 This highlights Grain’s commitment to minimal dependencies while still leveraging existing data ecosystems. Additionally, Grain supports in-memory data sources that are sharable across multiple processes, effectively avoiding data replication in each worker’s memory.11
- Transformations: These represent operations applied to input elements. Transformations must be picklable to ensure compatibility with Python’s multiprocessing for parallel execution.11 Grain provides a BatchTransform (where batch_size refers to the global batch size if applied before sharding, or per-host if applied after) and abstract classes like MapTransform, RandomMapTransform, and FilterTransform for users to implement custom data manipulations.11
A significant strength of Grain lies in its deep integration with the JAX ecosystem, particularly with Orbax for distributed checkpointing. Grain provides PyGrainCheckpointHandler specifically for checkpointing the DataLoader’s iterator.11 Orbax, a powerful library for checkpointing various JAX objects including Flax models and Grain DatasetIterators, works seamlessly with Grain to manage and synchronize all JAX processes in a multi-host environment, ensuring robust distributed checkpointing.11 Checkpoints generated by Grain contain information about the sampler and data source, allowing for validation and enabling the iteration to resume precisely from a saved point, even after preemption. Saving checkpoints with Orbax is asynchronous by default, necessitating a wait_until_finished() call to ensure completion before examination.11
Grain has been practically demonstrated in various JAX workflows, including its use for data loading in JAX AI Stack tutorials 6 and specifically for large language model (LLM) pretraining on Google Colab’s Cloud TPU v2.12 Installation is straightforward via pip install grain 12, and examples show its application with datasets like MNIST.13
The emphasis Grain places on “deterministic,” “resilient to preemptions,” and “minimal size checkpoints,” coupled with its deep “Integration with Orbax” 10, indicates a design philosophy geared towards enterprise-grade robustness and scalability. These features are critical for addressing the inherent challenges of large-scale, distributed machine learning, especially in cloud environments where training jobs can be long-running and subject to interruptions (e.g., preemption of spot instances on TPUs). Determinism ensures that if a training job is interrupted and subsequently resumed, the progress remains consistent and reproducible, which is vital for both research integrity and production reliability. The focus on minimal checkpoint size directly mitigates I/O overhead, a significant factor when dealing with massive datasets and frequent checkpointing intervals. This collective emphasis strongly suggests that Grain is built to meet the rigorous demands of industrial-scale machine learning, where reliability, efficiency, and fault tolerance in distributed settings are paramount.
Furthermore, Grain’s provision of a tfds.data_source that functions “without a TensorFlow dependency” 11, while being listed alongside TensorFlow Datasets and Hugging Face Datasets in JAX documentation 5, reveals a sophisticated approach to ecosystem interoperability. This design choice is highly significant as it acknowledges the vast existing data ecosystem built around TensorFlow Datasets. By offering a direct interface to TFDS without requiring the entire TensorFlow framework, Grain provides a crucial bridge, enabling JAX users to leverage rich, pre-processed datasets that are commonly available in TFDS format, without incurring the overhead or potential conflicts of integrating a full external framework. This demonstrates a strategic focus on data access and compatibility over framework lock-in, facilitating a cleaner separation of concerns. This approach enhances the practical utility of JAX for a broader range of machine learning tasks by simplifying data ingestion from common sources, suggesting a mature ecosystem strategy where components from different frameworks can be leveraged selectively to maximize efficiency and maintain JAX’s lightweight nature.
5. Comparative Analysis of JAX Data Loading Solutions
The landscape of data loading solutions for JAX presents developers with distinct choices, each with its own strengths and ideal use cases. Understanding their comparative features and performance characteristics is crucial for making informed architectural decisions.
Feature Comparison
To provide a clear overview, the following table compares jax-dataloader, Grain, and other common data loading approaches in the JAX ecosystem:
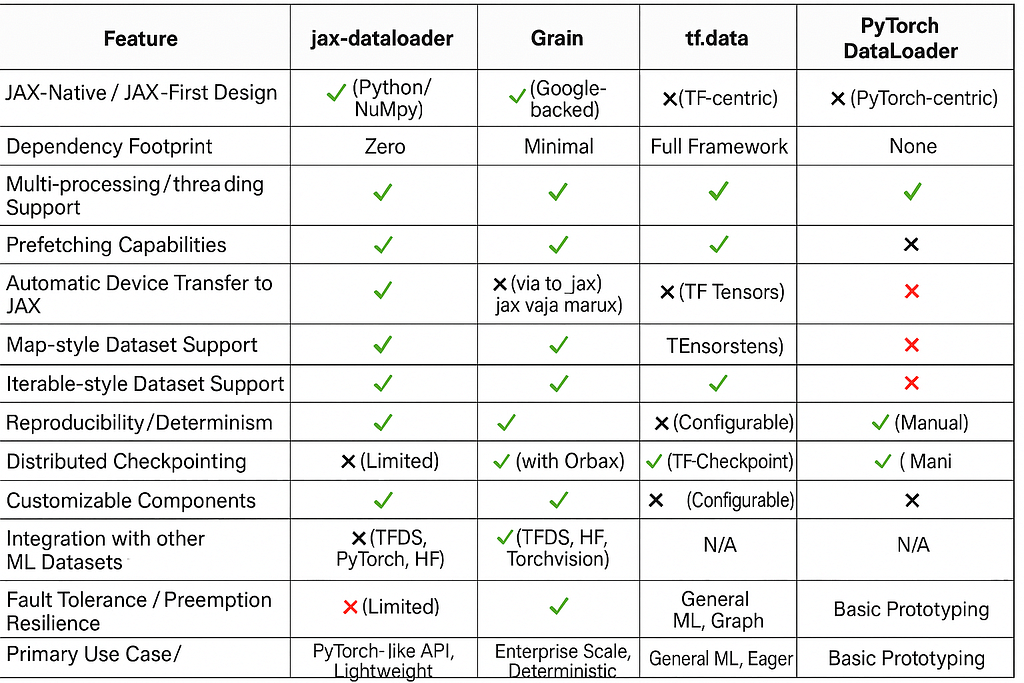
Performance Benchmarks
jax-dataloader has demonstrated significant performance gains in its own benchmarks. It reported “Peak throughput improved up to 3×”. More specifically, on a 4-core CPU with SSD storage, it achieved a “3.1× speedup over manual NumPy,” a “2.6× speedup over tf.data,” and “Comparable performance with PyTorch”.

While specific comparative benchmarks for Grain against jax-dataloader are not provided in the available information, Grain is designed to be “Performant” and has been “tested it against multiple data modalities”.10 Its inherent features, such as resilience to preemptions and minimal dependencies, contribute to its performance in large-scale, distributed settings by reducing overheads and enabling efficient restarts.10
It is important to consider the general performance context of JAX itself. JAX’s “compile-first approach” through jax.jit and XLA can introduce an “up-front compilation cost” and potentially higher “VRAM usage due to staging buffers” in smaller models or tests.14 However, JAX truly “shines in scenarios where batch sizes are larger, and the training loop is run many times, allowing it to reuse compiled functions efficiently”.14 Consequently, effective data loading solutions for JAX must not only be fast in data preparation but also adept at handling this compilation overhead and ensuring efficient data transfer to devices.

Design Philosophy and Use Case Suitability
The distinct design philosophies of jax-dataloader and Grain reflect a natural segmentation of the JAX user base and their optimization priorities. This is not a contradiction but rather a complementary specialization within the maturing JAX ecosystem.
When to choose jax-dataloader:
jax-dataloader is an excellent choice for users already familiar with PyTorch’s DataLoader API who are seeking a seamless transition to JAX.7 Its emphasis on minimal dependencies and a pure Python/NumPy stack aligns well with projects prioritizing a lean, self-contained environment.7 Scenarios where composability and fine-grained control over the data pipeline stages are desired also benefit from its modular architecture. It is particularly well-suited for single-host or smaller-scale multi-GPU training, where its robust prefetching and multi-worker capabilities can effectively keep accelerators fed.
When to choose Grain:
Grain is positioned for large-scale, distributed training in multi-host environments, especially when leveraging TPUs.12 Its core strengths in strong determinism and resilience to preemption make it ideal for long-running jobs in cloud environments where interruptions are possible.10 Deep integration with the broader Google machine learning ecosystem, including Orbax for distributed checkpointing and efficient handling of TFDS datasets, further solidifies its suitability for users operating within this ecosystem.5 Projects where data sources are primarily ArrayRecord files or TFDS will find Grain particularly efficient.11
Considerations for Integrating tf.data or PyTorch DataLoader:
While jax-dataloader and Grain offer JAX-native solutions, existing tf.data or PyTorch DataLoader pipelines can still be integrated. tf.data provides robust data pipeline construction, especially for complex transformations and very large datasets. However, its use introduces TensorFlow dependencies and potential impedance mismatches with JAX’s functional paradigm.13 Similarly, PyTorch DataLoader is highly popular and flexible, and can be used with JAX by converting PyTorch tensors to NumPy arrays.3 Both approaches, however, introduce framework dependencies and may incur performance overheads due to inter-framework data conversion and explicit device transfers.3
Scenarios where Manual NumPy might still be viable:
For very small datasets or simple, one-off scripts used for rapid prototyping, the overhead of a dedicated data loader might be negligible. However, for anything beyond trivial scale, manual NumPy batching will quickly become a performance bottleneck.
The distinct optimization goals of jax-dataloader and Grain reflect the diverse needs within the JAX user community. jax-dataloader caters to users who value ease of migration from PyTorch and a lightweight, self-contained solution, often for single-node or smaller distributed setups. This approach prioritizes developer experience and minimal overhead. In contrast, Grain, as a Google-backed project, is engineered for the rigorous demands of large-scale, enterprise-grade distributed training. Its emphasis on fault tolerance, determinism, and seamless integration with cloud infrastructure (like TPUs and Orbax for checkpointing) directly addresses the critical requirements of industrial-scale machine learning. This demonstrates that the JAX ecosystem is maturing to offer tailored solutions, allowing users to choose based on their project’s specific scale and operational requirements.
The concept of “JAX-native” data loading is also undergoing an evolution. Initially, “native” often implied adapting existing Python/NumPy tools or creating shims to convert data from PyTorch or TensorFlow data loaders into NumPy arrays for JAX consumption.3 jax-dataloader advances this by building a new data loader entirely within the Python/NumPy ecosystem, specifically optimized for JAX’s performance characteristics, thereby minimizing external framework dependencies. Grain, while also “JAX-first,” exemplifies a different facet of “native” by providing robust integration with common data formats like TFDS while selectively shedding their full framework dependencies.11 This indicates a strategic focus on data format compatibility without the burden of full framework adoption. This signifies a growing maturity where data loading is no longer an afterthought but a first-class citizen in JAX’s high-performance design, with solutions purpose-built to align with JAX’s unique architectural principles.
6. Advanced Considerations for Distributed Data Loading in JAX
Achieving optimal performance in JAX, especially when dealing with large models and datasets, necessitates a deep understanding of distributed data loading. JAX is inherently designed to operate efficiently in multi-host or multi-process environments, where the input data is typically split across various processes.1 In such setups, each JAX process possesses a set of local devices (e.g., GPUs or TPUs) to which it can directly transfer data and execute computations.1 A fundamental concept in this distributed paradigm is the Sharding associated with every jax.Array, which precisely describes how the global data is laid out across all available devices.15 This sharding information is critical for JAX to correctly understand and manage data distribution for parallel computation. To enable JAX to recognize and utilize devices beyond the local process, jax.distributed.initialize() must be invoked in a multi-process setup.1 Furthermore, jax.sharding.Mesh and PartitionSpec are key constructs used to define how tensors are sharded across devices, enabling both data parallelism and model parallelism.12
Several strategies exist for distributed data loading, each with its own trade-offs in terms of complexity and efficiency:
- Option 1: Load the global data in each process. This is the simplest approach, where every process loads the entire dataset and then transfers only the necessary shards to its local devices. While straightforward, it is generally less efficient due to redundant data loading.15
- Option 2: Use a per-device data pipeline. This strategy involves each device having its own dedicated data loader responsible for fetching only the specific data shard it requires. This is often the most efficient method but also the most complex to implement, as it demands intricate logic to determine and load precisely what each device needs.15
- Option 3: Use a consolidated per-process data pipeline. In this approach, each process sets up a single data loader that fetches all the data required by its local devices. The data is then sharded locally before being transferred to each individual device.15
- Option 4: Load data and reshard inside computation. This strategy involves loading the global data exactly once across all processes, and then performing the data resharding within the JAX computation itself. This approach is versatile and can be applied beyond just batched data records, extending to scenarios like loading model weights from a checkpoint or handling large spatially-sharded images.15
The intricacies of JAX’s distributed environment mean that data loading transcends simple I/O and becomes an integral part of the distributed systems problem. The concept of Sharding is central to this, as it dictates not just how data is brought into JAX, but how it is organized and distributed across devices for parallel computation. A critical implication is that if incorrect data shards are inadvertently placed on the wrong devices, the computation may still execute without explicit errors, as JAX’s functional nature means it has no inherent way to know what the input data should be. However, this silent failure mode can lead to incorrect final results.15 This underscores why robust data loading solutions, like Grain with its strong determinism and Orbax integration, or meticulously configured jax-dataloader pipelines, are not merely about speed but are fundamental for ensuring correctness and simplifying debugging in complex distributed JAX applications. This elevates data loading from a mere utility to a core architectural concern in high-performance JAX systems, where the choice and configuration of the data loader must align perfectly with the model’s sharding and parallelism scheme, whether it’s data parallelism, model parallelism, or a combination of both.15
For achieving optimal performance at scale, particularly on TPUs, it is “strongly recommended” to co-locate the input data pipeline using colocated Python.16 This advanced technique involves running user-specified Python code, including data loading logic, directly on the TPU or GPU hosts. This eliminates the common “CPU bottleneck,” where the CPU cannot prepare data fast enough to keep the accelerators busy, and instead leverages the TPU’s fast interconnects for rapid data transfer.16 Pathways-utils is a Python package that provides essential utilities and tools to streamline the deployment and execution of JAX workloads on the Pathways on Cloud architecture, handling the necessary adaptations for the cloud environment.16 It registers a custom ArrayHandler that facilitates efficient checkpoint operations through the IFRT proxy, allowing Pathways workers on accelerators to directly save and restore data.16 Furthermore, Orbax is thoroughly tested with Pathways for distributed checkpointing and restoring with Cloud Storage.16
The recommendation to “co-locate your input data pipeline” via colocated Python to “eliminate the CPU bottleneck and leverages the TPU’s fast interconnects for data transfer” 16 points to a sophisticated principle of hardware-software co-design. This is not simply about making I/O faster; it is about optimizing the entire data flow path within the specialized hardware architecture. By moving data loading logic directly onto the accelerator host, JAX can utilize the high-bandwidth, low-latency interconnects (such as TPU ICI or NVLink) that exist between hosts and devices, which offer significantly superior performance compared to traditional host-to-device PCIe transfers.1 This implies that achieving peak performance in JAX, especially on TPUs, requires a holistic view that extends beyond just the software data loader. It necessitates an understanding of the underlying hardware topology and the strategic use of features like colocated Python to minimize data transfer overheads and maximize accelerator utilization. This perspective is particularly relevant for Grain, which is developed within the Google ecosystem and is likely designed with such co-location strategies in mind to deliver optimal TPU performance. It highlights that even the most efficient software data loader can be constrained by hardware architecture if not deployed and configured optimally within the overall system.
7. Conclusion and Recommendations
The evolution of data loading solutions in JAX, epitomized by jax-dataloader and Grain, signifies a critical maturation of its ecosystem. These tools directly address the long-standing bottleneck of data feeding in JAX’s high-performance computational environment, transforming it from an ad-hoc challenge into a structured, optimized process.
Summary of Strengths and Weaknesses:
- jax-dataloader: Its primary strengths lie in its PyTorch-like API, offering a familiar and intuitive experience for developers transitioning from PyTorch. Being a zero-dependency, Python/NumPy native solution, it maintains a lightweight footprint and integrates seamlessly into JAX pipelines. It demonstrates strong performance in single-host scenarios and provides a highly composable design. Its main limitation is less explicit support for complex multi-host distributed checkpointing compared to Grain.
- Grain: This library excels in enterprise-grade robustness, offering strong determinism and resilience to preemption, which are crucial for long-running, large-scale training jobs. Its deep integration with Orbax for distributed checkpointing and efficient handling of TFDS datasets (without requiring the full TensorFlow dependency) makes it a powerful choice within the Google ML ecosystem. Grain’s primary weakness might be a potentially steeper learning curve for users unfamiliar with its specific components and a less direct “PyTorch-like” API.
Actionable Recommendations for JAX Developers:
- For Rapid Prototyping or PyTorch Users: For projects prioritizing ease of use, a familiar API, and a low dependency footprint, especially in single-node or smaller distributed setups, jax-dataloader is the recommended choice. Its design facilitates a quick ramp-up and clean integration.
- For Large-Scale, Distributed Training (especially on Google Cloud/TPUs): Grain is the superior choice for projects demanding robust features like determinism, fault tolerance, and seamless integration with distributed checkpointing via Orbax. Its design is inherently suited for the demands of industrial-scale machine learning on cloud infrastructure.
- For Leveraging Existing Datasets/Pipelines: Both jax-dataloader and Grain offer pathways to integrate with existing TensorFlow Datasets (TFDS) or PyTorch datasets. However, Grain’s ability to utilize tfds.data_source without pulling in the entire TensorFlow dependency is a notable advantage for maintaining a leaner environment.
- For Extreme Performance on TPUs: To maximize accelerator utilization and eliminate CPU bottlenecks, especially on TPUs, developers should investigate colocated Python and Pathways-utils in conjunction with their chosen data loader. This hardware-software co-design approach leverages high-speed interconnects for optimal data throughput.
- Always Benchmark: Regardless of the chosen solution, it is imperative to conduct thorough benchmarks with your specific dataset, model, and hardware configuration. This empirical validation will help identify actual bottlenecks and guide further optimization efforts.
Future Outlook for JAX Data Loading:
The continued development and refinement of jax-dataloader and Grain underscore a maturing JAX ecosystem that is systematically addressing critical infrastructure needs. As JAX continues to push the boundaries of large-scale machine learning, further innovations in distributed data loading are anticipated. This may include more tightly integrated solutions for data sharding and device placement, potentially simplifying the complexities of distributed data pipelines even further. The growing emphasis on determinism and resilience will likely persist and expand, becoming increasingly vital as models grow in size and training runs become longer and more resource-intensive. The diversification of JAX’s data loading tools indicates a healthy and expanding ecosystem capable of supporting a wide spectrum of machine learning applications, from rapid research prototyping to robust, production-grade deployments.
![]()
Optimizing Data Loading Performance in JAX with jax-dataloader and Grain was originally published in Google Developer Experts on Medium, where people are continuing the conversation by highlighting and responding to this story.




