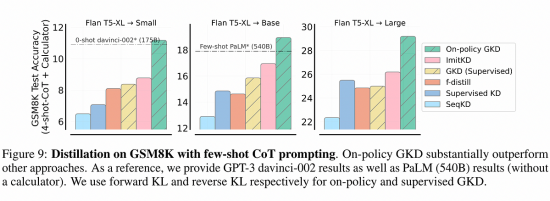
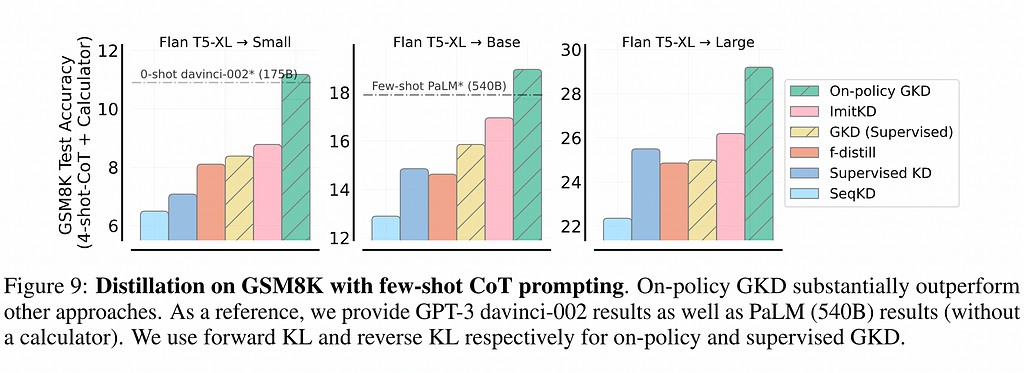
Large Language Models (LLMs) are rapidly evolving, with recent developments in models like Gemini and Gemma 2 bringing renewed attention to the technique of Knowledge Distillation (KD). Particularly, these models have employed “online” or “on-policy” Distillation in various pre- and post-training steps, showcasing the potential of this approach in pushing the boundaries of LLM capabilities. This blog post we will look into the intricacies of Online Knowledge Distillation, its implementation, and its implications for the future of LLM development.
Understanding Online Knowledge Distillation
Concept and Motivation
Online Knowledge Distillation, also known as on-policy Knowledge Distillation, is an advanced training technique where a smaller student model learns from a larger, more capable teacher model during the training process. The key distinction from traditional KD lies in its dynamic nature: the student learns from distributions of samples that it generates itself, rather than from a fixed dataset.
The primary motivation behind this approach is to address the train-inference mismatch often observed in traditional KD methods. In conventional setups, the student model might be trained on outputs from the teacher that are significantly different from what the student can produce during inference. Online KD aims to bridge this gap by allowing the student to learn from its own generated outputs, with guidance from the teacher.
Key Components
- Student Model: A smaller, typically fine-tuned model that we aim to improve.
- Teacher Model: A larger, more capable model (e.g., GPT-4, Gemini Ultra, Claude 3.5) that provides the “gold standard” outputs.
- Input Dataset: A collection of prompts or inputs used to generate responses.
The Training Process
- Generation: The student model generates outputs based on the input dataset.
- Probability Computation:
• The student model computes token-level probabilities for both the input and its generated output.
• The teacher model computes token-level probabilities for the same input-output pairs. - Distribution Minimization: Apply a divergence measure (e.g., KL divergence or Jensen-Shannon divergence) to minimize the difference between the teacher and student distributions.
Technical Implementation
Objective Function
The core of Online KD is the objective function used to align the student’s distribution with the teacher’s. Typically, this involves minimizing the Kullback-Leibler (KL) divergence or Jensen-Shannon divergence (JSD) between the two distributions.
For a given input sequence x and output sequence y, the objective can be formulated as:
L(θ) = E[D_KL(P_T(y|x) || P_S(y|x; θ))]
Where:
- θ represents the parameters of the student model
- P_T is the teacher’s probability distribution
- P_S is the student’s probability distribution
- D_KL is the KL divergence
Algorithm Outline
- Initialize student model S with parameters θ
- For each training iteration:
a. Sample a batch of inputs {x_i} from the dataset
b. Generate outputs {y_i} using the student model S(x_i; θ)
c. Compute probabilities P_S(y_i|x_i; θ) and P_T(y_i|x_i)
d. Calculate the KL divergence: D_KL(P_T || P_S)
e. Update θ to minimize the divergence using gradient descent
Advantages and Insights
- Performance Improvement: Online KD has been shown to outperform traditional imitation learning approaches.
- Flexibility in Divergence Measures: While KL divergence is common, research has shown that reverse KL performed best on instruction tuning tasks.
- Compatibility with Other Techniques: Online KD can be combined with other optimization objectives, such as those used in Reinforcement Learning from Human Feedback (RLHF) or AI Feedback (RLAIF).
- Quantifiable Improvements: Studies have reported improvements of up to 2% on the MMLU (Massive Multitask Language Understanding) benchmark and 1% on BBH (Big-Bench Hard) for base-5 models compared to traditional imitation learning.
Case Study: Gemma’s Approach
The recent Gemma 2 report highlights an interesting application of on-policy distillation to refine Supervised Fine-Tuning (SFT) models before RLHF. Their approach involves:
- Fine-tuning a student model on synthetic data from a larger teacher model.
- Generating completions from the fine-tuned student model using the same prompts from the SFT step.
- Fine-tuning the model again using knowledge distillation, minimizing the KL divergence between the student and teacher distributions across each completion.
This method effectively addresses the train-inference mismatch by allowing the student to learn from its own generated outputs, guided by the teacher’s expertise.
Theoretical Foundations
The theoretical underpinnings of Online Knowledge Distillation are explored in depth in the paper “On-Policy Distillation of Language Models: Learning from Self-Generated Mistakes” by Agarwal et al. This work introduces the concept of Generalized Knowledge Distillation (GKD), which offers several key advantages:
- Dynamic Training Set: Instead of relying on a fixed set of output sequences, GKD trains the student on its self-generated outputs.
- Flexible Loss Functions: GKD allows for the use of alternative loss functions between student and teacher, which can be crucial when the student lacks the capacity to fully mimic the teacher’s distribution.
- Integration with RL: The method facilitates seamless integration of distillation with reinforcement learning fine-tuning techniques like RLHF.
Challenges and Considerations
While Online Knowledge Distillation offers significant benefits, it’s important to consider potential challenges:
- Computational Cost: The dynamic nature of the training process can be more computationally intensive than traditional KD.
- Teacher Model Selection: The choice of teacher model significantly impacts the results, and finding the right balance between teacher capability and student capacity is crucial.
- Hyperparameter Tuning: The effectiveness of Online KD can be sensitive to hyperparameters, requiring careful tuning for optimal results.
Future Directions
The success of Online Knowledge Distillation in models like Gemini and Gemma points to several exciting future directions:
- Hybrid Approaches: Combining Online KD with other advanced training techniques like few-shot learning or meta-learning.
- Multi-Modal Distillation: Extending the principles of Online KD to multi-modal models, potentially improving cross-modal understanding and generation.
- Adaptive Teachers: Developing methods where the teacher model itself adapts during the distillation process, potentially leading to even more effective knowledge transfer.
Conclusion
Online Knowledge Distillation represents a significant advancement in the training of Large Language Models. By addressing the train-inference mismatch and allowing for dynamic, self-improving learning, this technique has the potential to push the boundaries of what’s possible with smaller, more efficient models. As research in this area continues to evolve, we can expect to see further refinements and applications of Online KD, potentially revolutionizing the way we approach model compression and performance optimization in the field of natural language processing.
![]()
Online Knowledge Distillation: Advancing LLMs like Gemma 2 through Dynamic Learning was originally published in Google Developer Experts on Medium, where people are continuing the conversation by highlighting and responding to this story.


![[boost]](https://prodsens.live/wp-content/uploads/2025/02/31353-boost-380x250.png)

