
Using generative AI to create music and video clips

Amongst the many areas being empowered by generative AI, one that I am really looking forward to is music creation, while generative AI for audio has advanced quite a lot in other forms like audio classification, text-to-speech (TTS), speech-to-text (STT), and similar cases, music generation has mostly began to only see relevant progress since last year, especially by some projects like AudioCraft by Meta or MusicLM by Google, now we are enabled to create good quality music with AI, which is the main topic that we will work here.
With this project (AI Beats), we will go through the steps required to create cool video clips composed of AI-generated music, and AI-generated animations.
Here are some examples of content generated by this project
https://medium.com/media/d73d8a262682e58d50ed178eb806b978/hrefhttps://medium.com/media/44036a527eb52e2f4177acfc18a14809/href
Generating music clips with AI
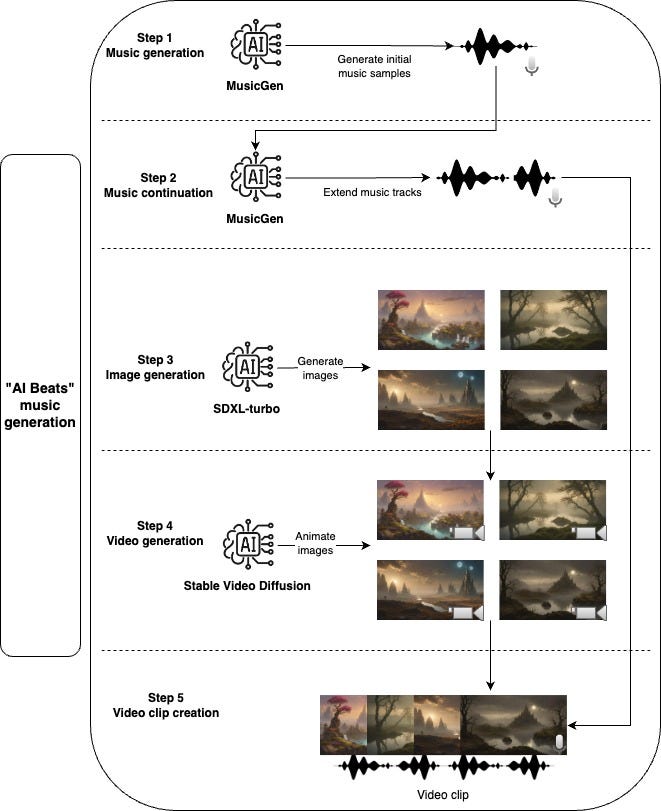
Music generation workflow overview
First, we use a generative model to create music samples, the default model used here is only able to generate a max of 30 seconds of music, for this reason, we take another step to extend the music samples. After finishing with the audio part we can generate the video, first, we start with a Stable Diffusion model to generate images and then we use another generative model to give it a bit of motion and animation. To compose the final video clip, we take each generated music and join together with as many animated images as necessary to match the length of the music track.
Now let’s go through a detailed description of each step.
Note: the code examples here were simplified for education purposes, to see the complete original code visit the project’s repository.
1. Music generation
The first step is to generate the music tracks. AI has evolved to the point that now this is as simple as generating images or text (although the quality is not on the same level yet), here we will use the MusicGen model with the HuggingFace library, we simply provide a prompt with a short description of the music.
# Loading the model
model = pipeline(
task="text-to-audio",
model="facebook/musicgen-small",
)
# Generating the music sample
music = model("lo-fi music")
# Saving the music file
scipy.io.wavfile.write(
"music.wav",
data=music["audio"],
rate=music["sampling_rate"],
)
This model also has other configuration parameters that can improve the generated music and change its length, to learn more visit its model card.
2. Music continuation
As we want music tracks with 1 to 2 minutes and this music generation model (MusicGen) is only able to generate a maximum of 30 seconds of music, we need a way to extend those tracks, the good news is that this same model can extend an audio given part of it as input, in a similar way that text models generate text continuations. We just need to use Meta’s AudioCraft lib and its API.
# Load the original music
sampling_rate, music = load_audio("music.wav")
# Load the models using AudioCraft
model = MusicGen.get_pretrained("facebook/musicgen-small")
# Define the length of the audio that will be generated (30s)
# This length includes the prompt duration
# In this case only the last 20s is actually new music
model.set_generation_params(duration=30)
# Take the portion of the original music that will be used as the prompt
# Here we use 10s of the original music
prompt_music_init = 10 * sampling_rate
prompt_music_waveform = torch.from_numpy(
music[:, :, -prompt_music_init:]
)
extended_music = (
model.generate_continuation(
prompt_music_waveform,
prompt_sample_rate=sampling_rate,
)
)
We can repeat this process as much as we want to generate longer music samples, from my experience the longer the track is, the noisier it tends to get, good music would be between 30 seconds and 1 minute, longer than this you would probably have to try a few times until you get something satisfactory.
3. Image generation
After being done with the audio part we can start to work on the clip visuals, the approach that I chose here, animating images, is not the most aesthetic but I really wanted to play with the diffusion models capable of creating motion from images. If you want to try something different you could use a static image (maybe just sliding the camera across the image), or maybe even play with a text-to-video model, as long as it can produce outputs close to OpenAI’s Sora it should be fine, let me know if you have other ideas.
For the approach that I chose here, the first step would be to create images, for this, I am using SXDL-turbo which has a great trade-off between image quality and resource usage. As with many other HuggingFace models, the usability is quite simple.
# Loading the model
model = AutoPipelineForText2Image.from_pretrained("stabilityai/sdxl-turbo")
# Generating the image
img = model(prompt="Mystical Landscape").images[0]
# Saving the image
img.save("image.jpg")
The SXDL-turbo has other parameters that you can play to get different results and it can generate high-quality images even with a single inference step. The prompt is essential to get images with the desired quality and style, make sure to spend some time tuning it.

4. Video generation
Now that we have the images to play with, we can start animating them, for this task, I picked the Stable Video Diffusion model, similar to the SDXL-turbo that we used before, this model was also created by Stability AI. This will add motion to images which usually results in parts of the image moving or an effect like the camera moving along the image, the bad thing is that at least for landscape images, they seem to get noisier the longer the animation goes.
Here is how we can animate images with this model:
# Load the model
model = StableVideoDiffusionPipeline.from_pretrained(
"stabilityai/stable-video-diffusion-img2vid"
)
# Load the image from previous step
image = load_image("image.jpg")
# Generate the aniumation, as a sequence of frames
frames = model(image).frames[0]
# Save the frames as a video
export_to_video(frames, "video.mp4")
By default this model generates 25 frames each time, if we want longer videos we could simply take the last frame and do the same process to generate an extra 25 frames, we could repeat this process as much as we want, but from my experience the video quality starts to get bad at the second iteration.

5. Video clip creation
By this point, we would have several music tracks and many video samples (from the previous step), all we need to do is build music videos with them, this process is quite simple as well thanks to MoviePy, this library provides some great tools to deal with video and audio with a simple API.
# Load one of the music tracks
audio = AudioFileClip("audio.wav")
audio_clip_duration = 0
videos = []
# Iterate over a list of video files (from step 4)
# In this loop we will incrementally add video files
# until we have videos to match the size of the music track
for video_path in video_paths:
# Load one of the videos
video = VideoFileClip(video_path)
# Add the video to the list
videos.append(video)
# Stop the loop if we get enough videos
audio_clip_duration += video.duration
if audio_clip_duration >= audio.duration:
break
# Merge all videos together
audio_clip = concatenate_videoclips(videos)
# Set the music track as the audio for the merged video
audio_clip.set_audio(audio)
# Save the final audio clip
audio_clip.write_videofile("audio_clip.mp4")
And that is all, after these steps, we have a cool audio clip fully AI-generated like the ones in the example section, if you give this a try I would love to see what you create, and feel free to change the code and try different ideas.
Next steps
This project is quite modular and flexible, if you want, you could provide your own music tracks, images, or video samples.
For the music part, tracks with the “lo-fi” prompt style sounded quite good, you could try to generate other styles of music, or even try other generative models, the field is evolving quite fast.
For the video part, there is a lot that can be done, as I suggested you could simply use static images, other kinds of image animation models, or even more complex text-to-video models.
At the final stage of audio clip mixing, there is a lot that can be done, you could use other libraries to improve the music quality, or you could loop the track to make it longer, I am not an expert here so I am probably missing a lot of good ideas on the mixing part.
If you are interested in content creation with generative AI, you might enjoy my previous article where I used AI to create trailers from movies, a small spoiler: they were spooky movies.
Creating Movie Trailers With AI
I hope this was interesting and I am eager to see the cool audio clips you will create and the interesting ideas you will bring!
![]()
How to generate music clips with AI was originally published in Google Developer Experts on Medium, where people are continuing the conversation by highlighting and responding to this story.




