This benchmark compares the performance of Snowflake and UUID. It was built using Go, Docker, SQLx, and PostgreSQL.
The graphs below were generated using Python3.
Understanding the benchmark
Go is the main programming language used for the benchmark. Each ID type (Snowflake or UUID) has its own .go file for running the benchmark separately. The benchmarked operations include:
- SELECTION (SELECT * FROM)
- ORDERED SELECTION (SELECT ORDER BY)
- ID GENERATION
- ID GENERATION + INSERT
- ID SEARCH (SELECT WHERE)
- UPDATE
For each benchmark, 200k IDs are generated (either Snowflake or UUID) before performing each benchmark operation. To reduce variability, the database is truncated after each benchmark run, and 30 iterations are performed to obtain a larger and more statistically significant sample.
How to run?
- Install Go
- Install Docker
- Install Python3
- Run the following commands:
docker-compose up -d
and then, run the Snowflake benchmark:
./run-snowflake.sh
or the UUID benchmark:
./run-uuid.sh
How to analyze the data
After running the benchmarks, you can analyze the data by running the following command:
python3 benchmark_analysis.py
this will generate the graphs and print the data analysis. The generated graphs will be saved in the images folder. The data from the benchmarks will be saved in the reports folder.
Results
Now, let’s interpret the results!
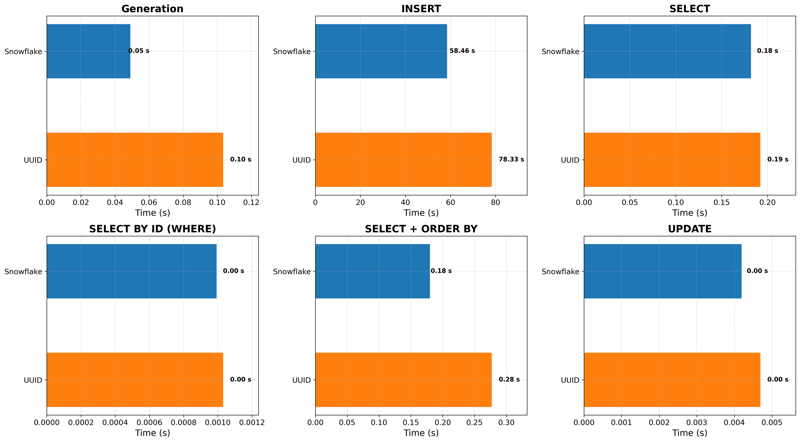
ID Generation
For ID Generation, UUIDs have very high variance and standard deviation, in counterpart Snowflakes were pretty stable during the 30 benchmark iterations.
| ____ | UUIDv4 | SnowflakeID |
|---|---|---|
| Mean | 103.4446 | 49.0516 |
| Variance | 987.8148 | 0.3929 |
| Std Deviation | 31.4295 | 0.6268 |

ID Insertion
For ID Insertion, UUIDs have very high variance and standard deviation, the same happened with SnowflakeIDs, but with lower values, performing the operations in fewer milliseconds.
| ____ | UUIDv4 | SnowflakeID |
|---|---|---|
| Mean | 78328.77 | 58455.25 |
| Variance | 27940797.04 | 5445730.74 |
| Std Deviation | 5285.90 | 2333.60 |

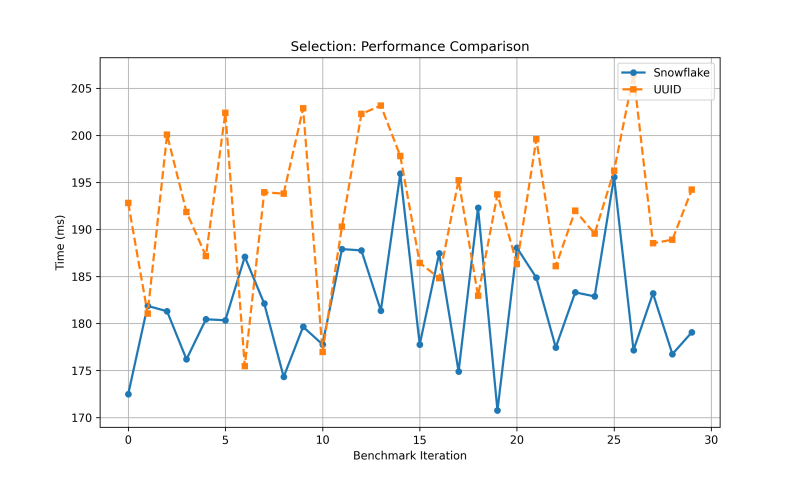
ID Selection
For ID Selection, UUIDs and Snowflake IDs had very high variance and standard deviation. Also, the mean wasn’t that different, showing that Snowflake IDs are indeed faster than UUIDs but by a small margin.
| ____ | UUIDv4 | SnowflakeID |
|---|---|---|
| Mean | 192.1073 | 181.9380 |
| Variance | 59.0411 | 38.1682 |
| Std Deviation | 7.6838 | 6.1780 |
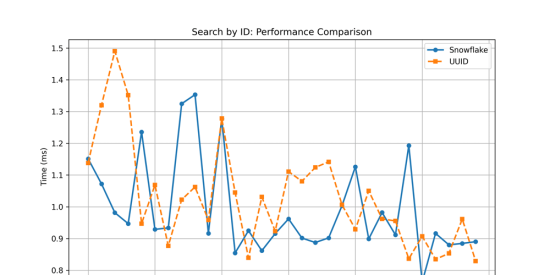
ID Search (WHERE)
For ID Search, the results were very similar to ID Selection, with the margin being even smaller. For this operation, the variance and standard deviation can be considered low for both ID types.
| ____ | UUIDv4 | SnowflakeID |
|---|---|---|
| Mean | 1.0309 | 0.9924 |
| Variance | 0.1609 | 0.0223 |
| Std Deviation | 0.0259 | 0.1494 |

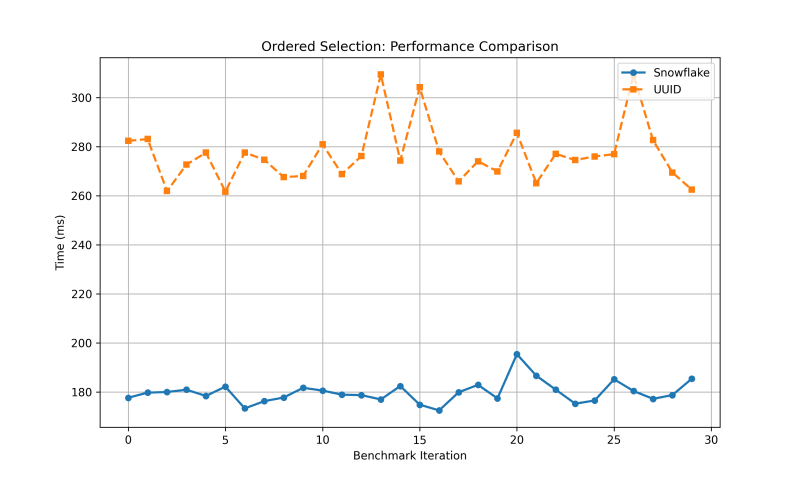
Ordered Selection (SELECT + ORDER BY)
For Ordered Selection, Snowflake IDs performed much better than UUIDs, having lower values for mean, variance, and standard deviation. UUIDs had a quite high variance value.
| ____ | UUIDv4 | SnowflakeID |
|---|---|---|
| Mean | 276.9748 | 179.8317 |
| Variance | 145.4764 | 19.3050 |
| Std Deviation | 12.0613 | 4.3937 |
Update
For the UPDATE operation, the results were very similar to the ID Search: Snowflake IDs performed a little bit better but by a very close margin. In this case, Snowflake IDs had a higher variance and standard deviation if compared to UUIDs.
| ____ | UUIDv4 | SnowflakeID |
|---|---|---|
| Mean | 4.6903 | 4.1918 |
| Variance | 1.4904 | 2.2434 |
| Std Deviation | 1.2208 | 1.4978 |

Validating Results
The results were validated by running the benchmarks multiple times (30), calculating the average and the standard deviation, and running a t-test to compare the means of the two groups. The t-test was performed with a 95% confidence level.

T-Test
T-tests are very good for saying if a benchmark or an optimization is significant, or relevant. For that, we use a 95% confidence level, which means that if the result of your T-test is within 0.000 (~100%) and 0.05 (95%), it lies in a high confidence interval, so you can state that your optimization is TRUE and relevant!
We can see that for UPDATE and ID SEARCH, the performance gap between Snowflake and UUID is not relevant according to the T-test. At the same time, we can notice that for all the other four operations benchmarked, the difference is evident and very clear. Snowflake IDs with a better overall in ordered selection, ID generation, and insertion.
Why is UUID’s variance so high?
UIDs, with their design focus on randomness, inherently exhibit high variance in generation times. Here’s a concise breakdown:
-
Randomness Source: UUIDs depend on a pool of entropy for random number generation. Fluctuations in this pool’s availability can lead to variability in creation time.
-
System Factors: The system’s workload and resource allocation can also impact the speed of UUID generation, causing inconsistent timing.
-
Inherent Entropy: With 122 bits dedicated to randomness out of 128, a UUID is highly entropic by nature, leading to intrinsic variability.
These factors combined mean that UUID generation can be a process with variable timing, reflecting the complex interplay between system entropy and resource demands.
Conclusion 📝
Is UUIDv4 bad?
No way! UUIDs are excellent and very useful. UUIDs are perfect for huge distributed systems and for scenarios where uniqueness is the most important factor. Even though those are the main strengths of UUIDS, they are also its main weaknesses. UUIDs are purely random and unique, making them unpredictable, unsortable, and too big. It can be a problem sometimes.
When to use each?
UUIDs (v4): if you want simplicity, easy setup, and compatibility, at the same time your system doesn’t expect a very high throughput; use UUIDs. A UUIDv4 has a size of 128 bits.
Snowflake IDs: Snowflakes are an “enhanced” BigInt, so if you are willing to improve performance, sort your data, and maintain secure public IDs; use Snowflake. A SnowflakeID has a size of 64 bits.
To improve ✨
This benchmark isn’t perfect and has some points to improve and to cover in the next version. Some of them:
- Concurrent testing
- Test in different databases besides Postgres
- Benchmark other UUID versions (ULID, UUIDv7)
- Display results in req/s (requests per second)
- Use even larger samples
- Measure the disk used by each
Links 🔗




