

Problem
Traditionally, educators create unit tests to automatically score students’ programming tasks. However, the precondition for running unit tests is that the project codes must be runnable or compiled without errors. Therefore, if students cannot keep the project fully runnable, they will only receive a zero mark. This is undesirable, especially in the programming practical test situation. Even if students submit partially correct code statements, they should earn some scores. As a result, educators will need to review all source codes one by one. This task is very exhausting, time-consuming, and hard to grade in a fair and consistent manner.
Solution — Scoring a programming code with LLM
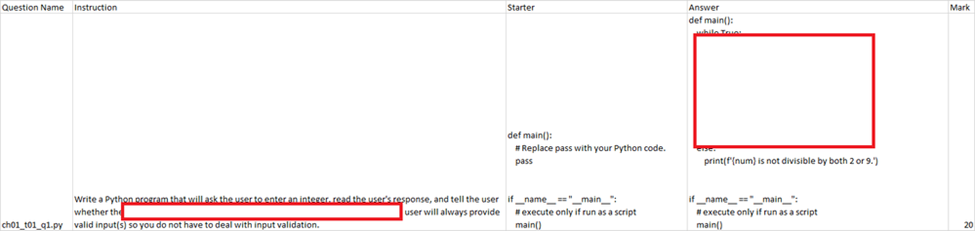
For a programming test, we provide starter code to students. They are required to read the instructions and write additional code to meet the requirements. We have a standard answer already. We will store the question name, instructions, starter code, answer and mark in an Excel sheet. This sheet will be used to prompt and score student answers.
1. Crafting the Chat Prompt:
- Design a comprehensive chat prompt that incorporates essential elements such as “instruction”, “starter”, “answer”, “mark”, “student_answer”, and “student_commit”.
- Utilize “Run on Save” functionality to encourage students to commit their code regularly upon saving. This serves as a reliable indicator of their active engagement and honest efforts.
2. Setting Up the LLM:
- Create an LLM within Vertex AI, specifically the codechat-bison model.
- Configure the temperature setting to a low value since scoring doesn’t necessitate creative responses.
3. Utilizing PydanticOutputParser:
- Employ PydanticOutputParser to generate the desired output format instructions and extract them into a Python object.
4. Connecting the Components:
- Seamlessly integrate all the aforementioned components to establish a smoothly functioning chain. This ensures efficient prompt management and effective LLM utilization.
https://github.com/wongcyrus/GitHubClassroomAIGrader/blob/main/gcp_vertex_ai_grader.ipynb
from langchain.chat_models import ChatVertexAI
from langchain.prompts.chat import ChatPromptTemplate
import langchain
langchain.debug = False
from langchain.output_parsers import PydanticOutputParser
from langchain.pydantic_v1 import BaseModel, Field, validator
from langchain.prompts import PromptTemplate, SystemMessagePromptTemplate, HumanMessagePromptTemplate
# Define your desired data structure.
class ScoreResult(BaseModel):
score: int = Field(description="Score")
comments: str = Field(description="Comments")
calculation: str = Field(description="Calculation")
parser = PydanticOutputParser(pydantic_object=ScoreResult)
def score_answer(instruction, starter, answer, mark, student_answer, student_commit, temperature=0.1,prompt_file="grader_prompt.txt"):
template = "You are a Python programming instructor who grades student Python exercises."
with open(prompt_file) as f:
grader_prompt = f.read()
data = {"instruction": instruction,
"starter": starter,
"answer": answer,
"mark": mark,
"student_answer": student_answer,
"student_commit": student_commit}
prompt = PromptTemplate(
template="You are a Python programming instructor who grades student Python exercises.n{format_instructions}n",
input_variables=[],
partial_variables={"format_instructions": parser.get_format_instructions()},
)
system_message_prompt = SystemMessagePromptTemplate(prompt=prompt)
human_message_prompt = HumanMessagePromptTemplate(prompt=PromptTemplate(
template=grader_prompt,
input_variables=["instruction", "starter", "answer", "mark", "student_answer", "student_commit"],
)
)
chat_prompt = ChatPromptTemplate.from_messages([system_message_prompt, human_message_prompt])
llm = ChatVertexAI(
model_name=model_name,
location=location,
max_output_tokens=1024,
temperature=0.2
)
runnable = chat_prompt | llm | parser
# Get the result
data = {"instruction": instruction,
"starter": starter,
"answer": answer,
"mark": mark,
"student_answer": student_answer,
"student_commit": student_commit}
output = runnable.invoke(data)
return output
The output of parser.get_format_instructions() in system prompt.
The output should be formatted as a JSON instance that conforms to the JSON schema below.
As an example, for the schema {"properties": {"foo": {"title": "Foo", "description": "a list of strings", "type": "array", "items": {"type": "string"}}}, "required": ["foo"]}
the object {"foo": ["bar", "baz"]} is a well-formatted instance of the schema. The object {"properties": {"foo": ["bar", "baz"]}} is not well-formatted.
Here is the output schema:
```
{"properties": {"score": {"title": "Score", "description": "Score", "type": "integer"}, "comments": {"title": "Comments", "description": "Comments", "type": "string"}, "calculation": {"title": "Calculation", "description": "Calculation", "type": "string"}}, "required": ["score", "comments", "calculation"]}
```
Programming question
{instruction}
{starter}
{answer}
{student_answer}
Number of times code commit to GitHub: {student_commit}
Student add the code statement from Starter.
Student follows the question to add more code statements.
Rubric:
- If the content of StudentAnswer is nearly the same as the content of Starter, score is 0 and comment “Not attempted”. Skip all other rules.
- The maximum score of this question is {mark}.
- Compare the StudentAnswer and StandardAnswer line by line and Programming logic. Give 1 score for each line of correct code.
- Don't give score to Code statements provided by the Starter.
- Evaluate both StandardAnswer and StudentAnswer for input, print, and main function line by line.
- Explain your score calculation.
- If you are unsure, don’t give a score!
- Give comments to the student.
The output must be in the following JSON format:
"""
{{
"score" : "...",
"comments" : "...",
"calculation" : "..."
}}
"""
In scenarios where a failure occurs, manual intervention is necessary to rectify the issue. This can involve switching to a more robust model, fine-tuning the parameters, or making slight adjustments to the prompt. To initiate the troubleshooting process, it’s essential to create a backup of the batch job output. This serves as a crucial reference point for analysis and problem-solving.
backup_student_answer_df = student_answer_df.copy()
Manually execute the unsuccessful cases by adjusting the following code and running them again.
print(f"Total failed cases: {len(failed_cases)}")
orginal_model_name = model_name
# You may change to use more powerful model
# model_name = "codechat-bison@002"
if len(failed_cases) > 0:
print("Failed cases:")
for failed_case in failed_cases:
print(failed_case)
# Get row from student_answer_df by Directory
row = student_answer_df.loc[student_answer_df['Directory'] == failed_case["directory"]]
question = failed_case['question']
instruction = standard_answer_dict[question]["Instruction"]
starter = standard_answer_dict[question]["Starter"]
answer = standard_answer_dict[question]["Answer"]
mark = standard_answer_dict[question]["Mark"]
student_answer = row[question + " Content"]
print(student_answer)
student_commit = row[question + " Commit"]
result = score_answer(instruction, starter, answer, mark, student_answer, student_commit, temperature=0.3)
#update student_answer_df with result
row[question + " Score"] = result.score
row[question + " Comments"] = result.comments
row[question + " Calculation"] = result.calculation
# replace row in student_answer_df
# student_answer_df.loc[student_answer_df['Directory'] == failed_case["directory"]] = row
#remove failed case from failed_cases
failed_cases.remove(failed_case)
model_name = orginal_model_name
Based on experience, most of the cases can be resolved by changing some parameter.
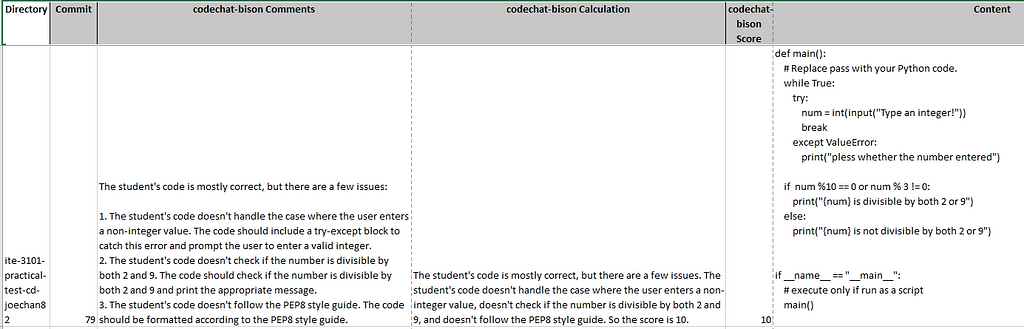
The output of human_review.ipynb
Conclusion
In this approach, we leverage the power of a pretrained Language Model (LLM), specifically the code chat model from Vertex AI, to score students’ programming assignments. Unlike traditional unit testing methods, this technique allows for partial credit to be awarded even if the submitted code is not fully runnable.
Key to this process is the crafting of a well-structured chat prompt that incorporates essential information such as instructions, starter code, answer, mark, student answer, and student commit status. This prompt guides the LLM in evaluating the student’s code.
The LLM is configured with a low temperature setting to ensure precise and consistent scoring. A PydanticOutputParser is employed to extract the desired output format instructions in a Python object.
By seamlessly integrating these components, we establish a smooth workflow that efficiently manages prompts and utilizes the LLM’s capabilities. This enables accurate and reliable scoring of programming assignments, even for partially correct code submissions.
This approach addresses the challenges faced by educators in grading programming assignments, reduces manual effort, and promotes fair and consistent assessment.
Project collaborators include, Markus, Kwok,Hau Ling, Lau Hing Pui, and Xu Yuan from the IT114115 Higher Diploma in Cloud and Data Centre Administration and Microsoft Learn Student Ambassadors candidates
About the Author
Cyrus Wong is the senior lecturer of Hong Kong Institute of Information Technology and he focuses on teaching public Cloud technologies. A passionate advocate for cloud tech adoption in media and events — AWS Machine Learning Hero, Microsoft MVP — Azure, and Google Developer Expert — Google Cloud Platform.

![]()
Using Google Cloud Vertex AI Code Chat to automate programming test scoring was originally published in Google Developer Experts on Medium, where people are continuing the conversation by highlighting and responding to this story.



