
We have some csv/xls files as the following shows:


SQL is suitable for handling those data, but the language depends on databases to work. We need to install a database and import the data into it to process. This results in bloated application system. Yet such a small task is not worth the effort. Is there a technology that can treat these files as data tables and use SQL to directly query them?
esProc SPL is just what you expect.
esProc SPL is an open-source software, which is offered in https://github.com/SPLWare/esProc.
It provides standard JDBC driver. By importing it in a Java application, we can perform SQL queries directly on files.
Class.forName("com.esproc.jdbc.InternalDriver");
Connection conn =DriverManager.getConnection("jdbc:esproc:local://");
PrepareStatement st = conn.prepareStatement("$select * from employee.txt where SALARY >=? and SALARY);
st.setObject(1, 3000);
st.setObject(2, 5000);
ResultSet result=st.execute();
We can also query a file in SQL from the command line:
esprocx.exe -R select Client,sum(Amount) from d:/Orders.csv group by Client
esProc supports SQL syntax similar to SQL92 standard:
select * from orders.xls where Amount>100 and Area='West' order by OrderDate desc
select Area, sum(Amount) from orders.xls having sum(Amount)>1000
select distinct Company from orders.xls where OrderDate>date('2012-7-1')
Joins:
select o.OrderId,o.Client,e.Name e.Dept from d:/Orders.csv o ,d:/Employees.csv e where o.SellerId=e.Eid
select o.OrderId,o.Client,e.Name e.Dept,e.EId from Orders.txt o left join Employees.txt e on o.SellerId=e.Eid
And subqueries and with statement:
select t.Client, t.s, ct.Name, ct.address from
(select Client ,sum(amount) s from Orders.csv group by Client)
left join ClientTable ct on t.Client=ct.Client
select * from d:/Orders.txt o where o.sellerid in (select eid from Employees.txt)
with t as (select Client ,sum(amount) s from Orders.csv group by Client)
select t.Client, t.s, ct.Name, ct.address from t left join ClientTable ct on t.Client=ct.Client
In fact, esProc does not aim specifically to provide SQL syntax. It has its own SPL syntax and supports the database language based on SPL passingly. This explains its ability to execute SQL without databases.
With the support of SPL, SQL gets a broader range of application scenarios, including those with irregular-format files:
Text files separated by |:
select * from {file("Orders.txt").import@t(;"|")} where Amount>=100 and Client like 'bro' or OrderDate is null
Text files without the title row, where SPL uses ordinal numbers to represent field names:
select * from {file("Orders.txt").import()} where _4>=100 and _2 like 'bro' or _5 is null
Reading a certain sheet from an Excel file:
select * from {file("Orders.xlsx").xlsimport@t(;"sheet3")} where Amount>=100 and Client like 'bro' or OrderDate is null
Querying a JSON file:
select * from {json(file("data.json").read())} where Amount>=100 and Client like 'bro' or OrderDate is null
And handling JSON data downloaded from the web:
select * from {json(httpfile("http://127.0.0.1:6868/api/getData").read())} where Amount>=100 and Client like 'bro' or OrderDate is null
Besides relational databases, SPL can also directly access data coming from MongoDB, Kafka, etc. This forms its mixed computing ability over diverse sources.
Yet, SPL has more abilities than these. From the beginning, the software aims to provide more powerful and more convenient computational capability. SQL syntax has limits in phrasing logics and is more fit for simple scenarios.
Here is an example. To find the largest number of consecutively rising days for a stock, SQL needs a nested query, which is lengthy and hard to read:
select max(ContinuousDays) from (
select count(*) ContinuousDays from (
select sum(UpDownTag) over (order by TradeDate) NoRisingDays from (
select TradeDate,case when Price>lag(price) over ( order by TradeDate)then 0 else 1 end UpDownTag from Stock ))
group by NoRisingDays )
It is much simpler and easier to write the logic in SPL:
Stock.sort(TradeDate).group@i(Price<Price[-1]).max(~.len())
Apart from all these, esProc provides a WYSIWYG IDE, which enables much more conveniently debugging than SQL:
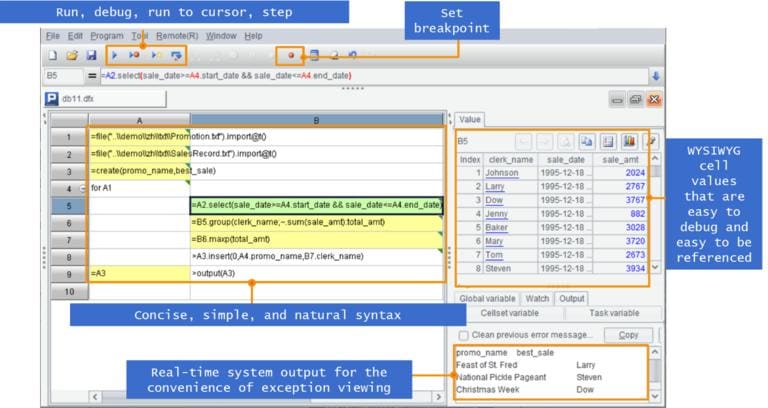
Read A programming language coding in a grid and get deeper understanding about SPL. The language can replace almost all database computing abilities with yet more powerful performance.
Check GitHub Repo
Don’t forget to give us a star ⭐ on the repo
![should-marketers-optimize-for-bing?-[data-+-expert-tips]](https://prodsens.live/wp-content/uploads/2023/12/17793-should-marketers-optimize-for-bing-data-expert-tips-110x110.png-23keepprotocol)



