
A fine collection of brand new Turkish NLP datasets
Despite being a widely spoken language across Asia and Europe with over 80 million speakers, Turkish doesn’t have as many linguistics resources. As a result, in my New Year campaign, I decided to compile a collection of brand new Turkish corpora, packages, pre-trained models, and tutorials. This article gives a taste of what sort of datasets are included in my New Year’s campaign, “Turkish NLP with Duygu”. spaCy Turkish models will come in a separate article.

The datasets
One cannot make a linguistic resources campaign without including any datasets 😊. Datasets of this campaign come in two categories: sentiment analysis datasets and NER datasets.
For sentiment analysis, available datasets are:
- Vitamins and Supplements Customer Reviews
- BeyazPerde Movie Reviews — Top 300 Movies
- BeyazPerde Movie Reviews — All Movies
The first dataset offers customer reviews about supplement and vitamin products. It’s scraped from an e-commerce website, Vitaminler.com. Each dataset instance contains the product name, product brand, some cumulative rating information, and a list of customer reviews where each review contains a review text and a star rating. Just like this:
{
"name": "Microfer Şurup 250 ml",
"brand": "Ocean",
"reviews": [
{
"review_id": 2,
"star": 5,
"review": "Ben kendim için aldım ama çocuklara içirmek zor olur
gibi geldi, demir tadı ağza yayılıyor kötü hissettiriyor.
Belki portakal suyuna karıştırılarak kullanılabilir.
Yetişkinlerde 2,5 ml günlük ihtiyacı tam karşılamıyor bu arada."
},
{
"review_id": 3,
"star": 5,
"review": "boyu baya buyuk tadida guzel"
},
{
"review_id": 5,
"star": 5,
"review": "doktorumuz tavsiye etti 3 uncu şişemiz
oğlum severek iciyo faydasını gördük"
}
........
]
}
The customer reviews include health complaints, symptoms, active ingredients, medical terms, as well as reviews about the drug and its effects. As a result, the dataset vocab contains medical terms as well as “ordinary” written language words. As a result, it makes Vitamins-Supplements Reviews quite an interesting, yet challenging dataset. As you see this fine NLU dataset lies somewhere between sentiment analysis and medical NLP. If you want to process this dataset, get ready for a semantic challenge!




The second and third datasets are scraped from popular movie reviews website Beyazperde.com. Each dataset instance contains quite a bit of information such the movie name, movie’s URL, movie genre with some metadata such as director, creator, music producer, and actor/actress info along with a list of review JSONs. Each review JSON contains a review text and a rating star, just like Vitamins-Supplements Reviews dataset. Here’s an example dataset instance:
{
"url": "https://www.beyazperde.com/filmler/film-178014",
"name": "Avatar: Suyun Yolu",
"genre": [
"Bilimkurgu",
"Macera",
"Fantastik",
"Aksiyon"
],
"desc": "Avatar serisinin 2009 yılında küresel bir fenomen haline gelen devam halkası; bu defa James Cameron'un yaratmış olduğu öykü evreninin hem kökenlerine iniyor hem de sınırlarını genişletmeyi hedefliyor. Avatar'da yaşanan olaylardan birkaç yıl sonra Jake ve Neytiri Pandora'da kendi ailelerini kurmuştur. Ancak onlar evlerini terk etmek zorunda kalır. Bu yüzden Jake ve Neytiri, suyun yüzeri ve altı dahil olmak üzere Pandora'nın dışındaki yerleri keşfetmeye başlar.",
"directors": "James Cameron",
"actors": "Sam Worthington, Zoe Saldana, Sigourney Weaver, Stephen Lang",
"creators": "James Cameron, Rick Jaffa, Amanda Silver, Amanda Silver, James Cameron, Rick Jaffa, Josh Friedman, Shane Salerno",
"musicBy": "Simon Franglen, The Weeknd",
"reviews": [
{
"rating": "4,0",
"review": "Filmi bugün Nişanlımla birlikte izleme şansım oldu. Avatarı ilk izlediğimde nedense çokta etkisinde kalmamıştım. bu filme de gittiğimde ilk filmi unutmuştum bile. Avatar 2 yi izleyince Avatar evreni ilgimi çekmeyi başardı. üçüncü filmi beklemiyorum desem yalan olur. Üçüncü Filmde fantastik ögelerden çok bilim kurgu yönünün ağır basması filmi daha anlamlı kılacağını düşünüyorum. Umarım üçüncü filmde yönetmen bu konuya önem verir. Onun dışında Film son zamanlarda izlediğim en naif en ahlaklı yapım diyebilirim. Ailecek gönül rahatlığıyla gidip izleyebilirsiniz. Günümüz yapımları gibi saçma sapan cinsel içerikli konuşmalardan, hareketlerden ibaret değildi. Filmde iki önemli mesaj vardı bunlardan biri aile diğeri küresel iklim değişikliği yani Doğa. Hep doğaya hemde aile yaşantısına karşı çokça mesaj çokça replik barındıran anlamlı bir filmdi. (Aile olmak hem en büyük zaafımız hemde en büyük gücümüz.) Üç saat olmasına rağmen hiçbir sıkılmadım. Aksiyon ve Trajediyi harmanlayıp izleyiciye çok iyi aktarıldığını düşünüyorum. Görsel efekt çekim teknikleri karakterler ve mekanlar harikulade diyebilirim. Tek kusur gördüğüm şey keşke iyi ve kötünün savaşını sadece bir aile sorununa indirgemeyip bu sorunu gezegenin tüm sorunu olarak göstermesi daha ihtişamlı olabilirdi. Sonuçta düşmanlar gezegene sadece Jake için gelmiyordu gezegeni tümüyle işgal edip, sömürmek için geliyordu. Ayrıca çocuk karakterler filmin yarısından sonra biraz fazla filme dahil olmaya başladı, bu bazı seyircileri sıkmış olabilir. Neyse sonuçta James Cameron müthiş bir evren oluşturmuş, izlemeye değer."
},
{
"rating": "5,0",
"review": "Film gerçekten hakkını veriyor. Saatin nasıl geçtiğini anlamıyorsunuz. Filmin geri kalan serisini sabırsızlıkla bekliyoruz."
},
{
"rating": "3,5",
"review": "Açıkçası film beklentilerimi karşılayamadı. Tabi her şeyin ilki güzel ama son seride iyi olabilirdi. Filmde görsel olarak her şey güzeldi kendimi filmi izledikten sonra ıslanmış gibi hissettim :D Puan kırdığım noktalar filmin bilim kurgudan fantastiğe doğru kayması. Ardından sır kapısına döndürüp iyilik yapan iyilik bulur moduna girmesi. Çoğu sahnelerin çocuklara hitap etmesi. Neyse serinin üçüncü filmi sağlam olucak gibi..."
}
....
]
...
}
Movie reviews come in different shapes and semantics; some reviews are long, some are short. Some reviews contain quite many vocab words about the sentiment including the reviewer’s feelings about the movie, comparison to similar movies, praise/dislike statements about the actresses/actors/director, etc. Humans are complicated creatures with complicated feelings; hence extracting text sentiment has always been a challenging task and this dataset is no different.
NER datasets comes with some variety too 😄😄. Two datasets comes from two different genres, a general/Wiki NER dataset and a more medical-flavored NER dataset with entity and span annotations. The first dataset is called Turkish Wiki NER Dataset, a general purpose NER dataset with a diverse set of labels including :
CARDINAL
DATE
EVENT
FAC
GPE
LANGUAGE
LAW
LOC
MONEY
NORP
ORDINAL
ORG
PERCENT
PERSON
PRODUCT
QUANTITY
TIME
TITLE
WORK_OF_ART
This dataset comes in conll format, here’s a sample annotation for you:
Joel B-PERSON
ve O
Benji B-PERSON
Madden'ın I-PERSON
" O
Dead B-WORK_OF_ART
Executives I-WORK_OF_ART
" O
adlı O
bir O
projeleri O
daha O
vardır O
. O
or even better:

The second dataset, Vitamins-Supplements NER Dataset comes with two flavors, a mixture of customer likes, dislikes, criticism, praise, and medical text. From the NLU side, this dataset offers an interesting type of annotation, which happens to be spans. First, an example:

Here, you’ll see some expressions and even clauses annotated (aka word spans). That’s a bit out of ordinary and normally we annotate entities that happen to be either proper nouns or tokens with a specific meaning or shape (such as numbers or money amounts). Here, instead we potentially capture a long chunk of word. Spans are based on semantics and we’d like to capture sequence of words that refer to certain feelings.
This dataset has labels for both spans and entities (you’ll need to visit the dataset’s page for more details 😉). Here’s an example annotation in JSON format:
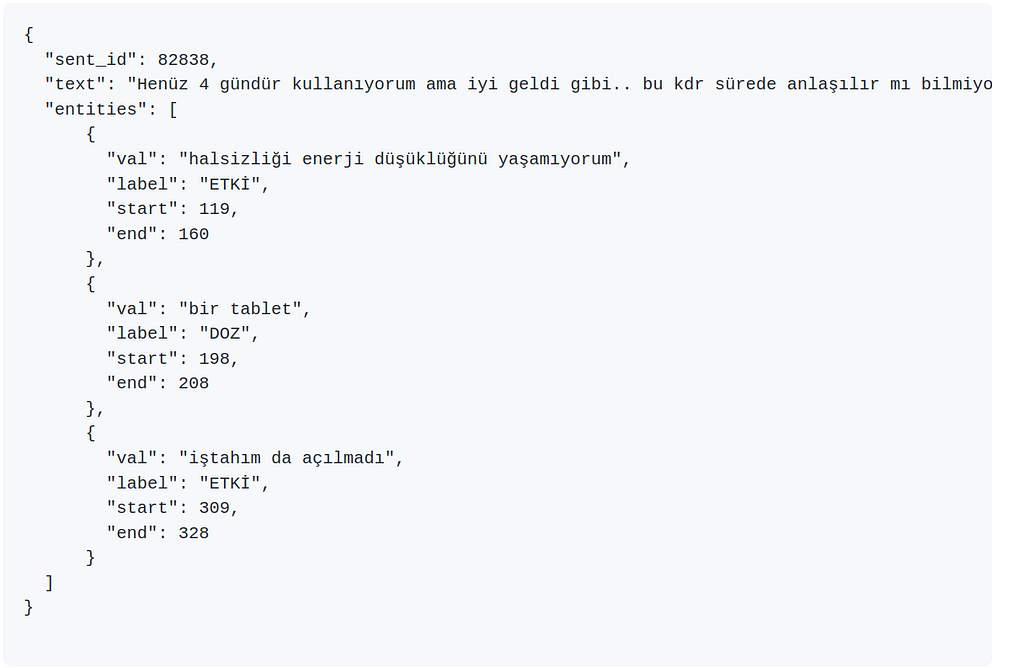
Spans are quite a challenge for NLU, since there’s no fixed sequence length or any clues indicating span start and end (span start and end can be word of any syntactic category). NER is just usual NER 😆, but one should be creaful with the medical terms anyway.
Dear readers, we reached the end of this article. All datasets can be found under my campaign’s Github, called Turkish NLP Suite. More information is available on the campaign website as well. For more content and even more Turkish NLP resources please visit my campaign website and join my Youtube channel. Until next time please stay happy and stay tuned 🎉🎉🎉🎉
![]()
A collection of brand new datasets for Turkish NLP was originally published in Google Developer Experts on Medium, where people are continuing the conversation by highlighting and responding to this story.




