I just finished an all-out engineering sprint. That sounds weird to me.
I’ve been writing code on and off for several years. But I wouldn’t call myself an engineer. I’m a product manager. And I used to be a designer. It’s been a long time since I’ve written code for a living.
But AI is changing what’s just now possible. Not just for the products we build. But also for us. We can do more than we might have ever imagined. That’s certainly been my experience.
Today, I want to share an engineering story with you. There will be some technical bits. Some of it might feel foreign to you. But I want you to know I had no idea how to do any of this a year ago. I learned it with the help of AI. My goal in sharing my engineering stories is to show you what’s just now possible.
Creating AI-Generated Opportunity Solution Trees
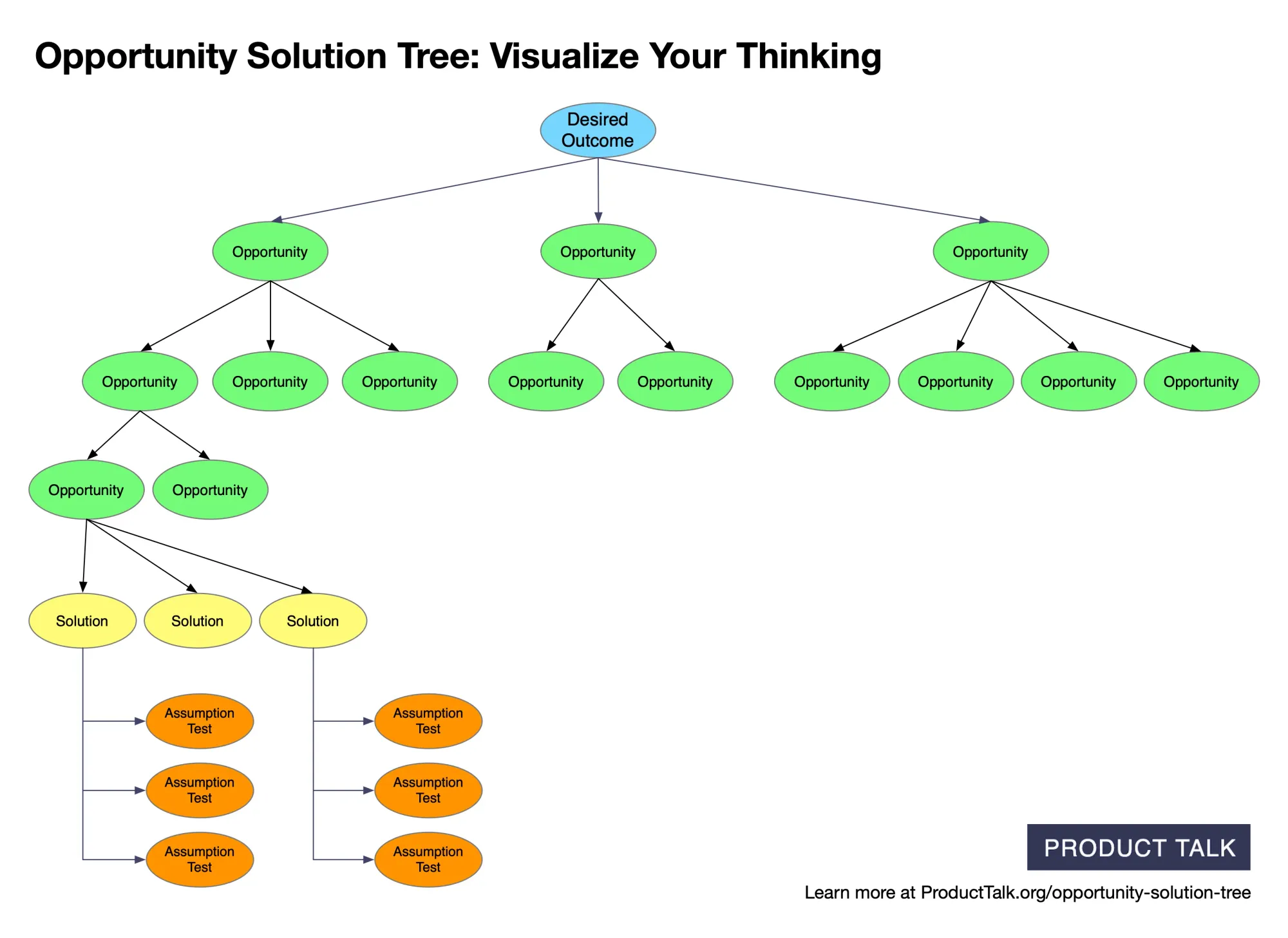
In mid-February, I announced that I was building two services for Vistaly—AI-generated interview snapshots and AI-generated opportunity solution trees. We both made a call for alpha partners. We got over 100 applicants before we closed the round. We selected eight to be our initial design partners.
Each team uploaded three customer interviews. We identified key moments and opportunities from each, then generated an opportunity solution tree from those three snapshots. I’m providing the AI services. Vistaly is building the snazzy UI and workflows around it.
Our initial feedback was strong. Teams started to ask us to let them upload more interviews. But we both had work to do to support this.
Integrating New Interviews into an AI-Generated Opportunity Solution Tree
Updating an opportunity solution tree with new interview content is a much harder challenge than generating a new opportunity solution tree from scratch. I initially underestimated the complexity.
Vistaly and I both have a shared goal. We don’t want to produce AI-generated opportunity solution trees and have you take them as fact. We want you to engage with them, correct them, collaborate with the AI. We want to scaffold cross-interview synthesis, not do it for you.
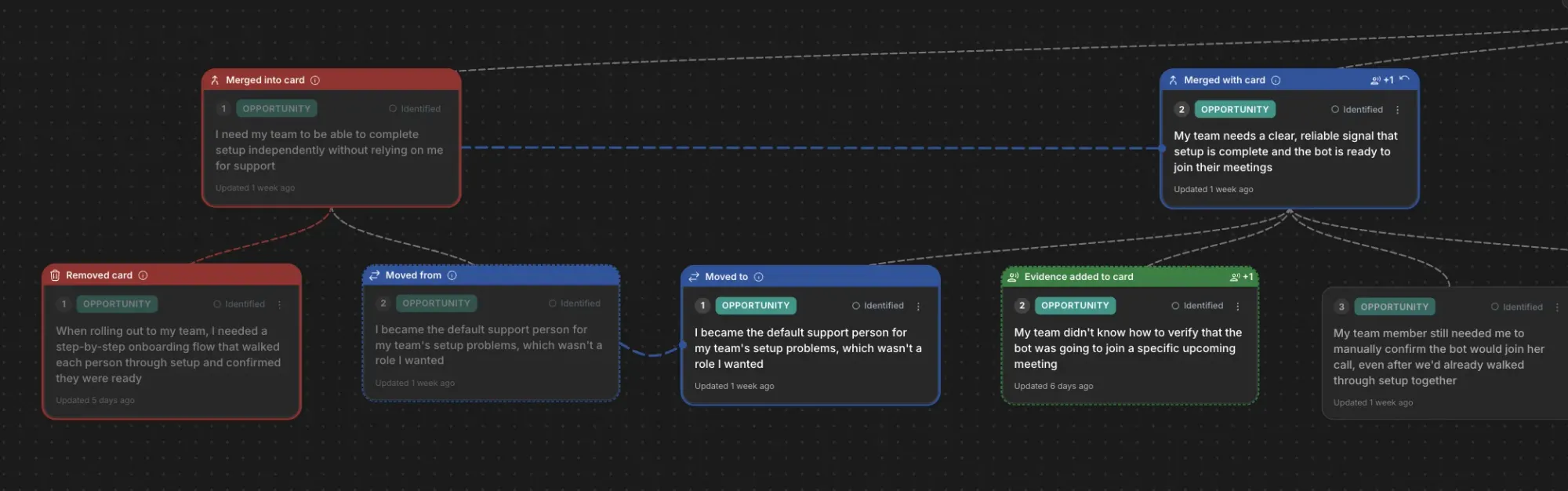
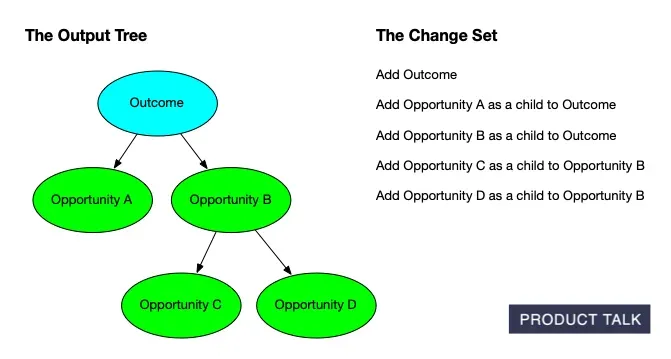
To support this, we needed a way to communicate how your tree would change after you uploaded new interviews. We took inspiration from git diff and decided we needed the equivalent for opportunity solution trees. If you aren’t familiar with git diff, it’s how git—the most common version control software for coding—shows you what has changed in a file. It walks you through each change one step at a time.
While this was absolutely the right decision to make, I had no idea how much work it would create for me. It wasn’t enough for my service to generate an updated opportunity solution tree with the content from the new interviews. It also had to provide a step-by-step walkthrough of what changed.
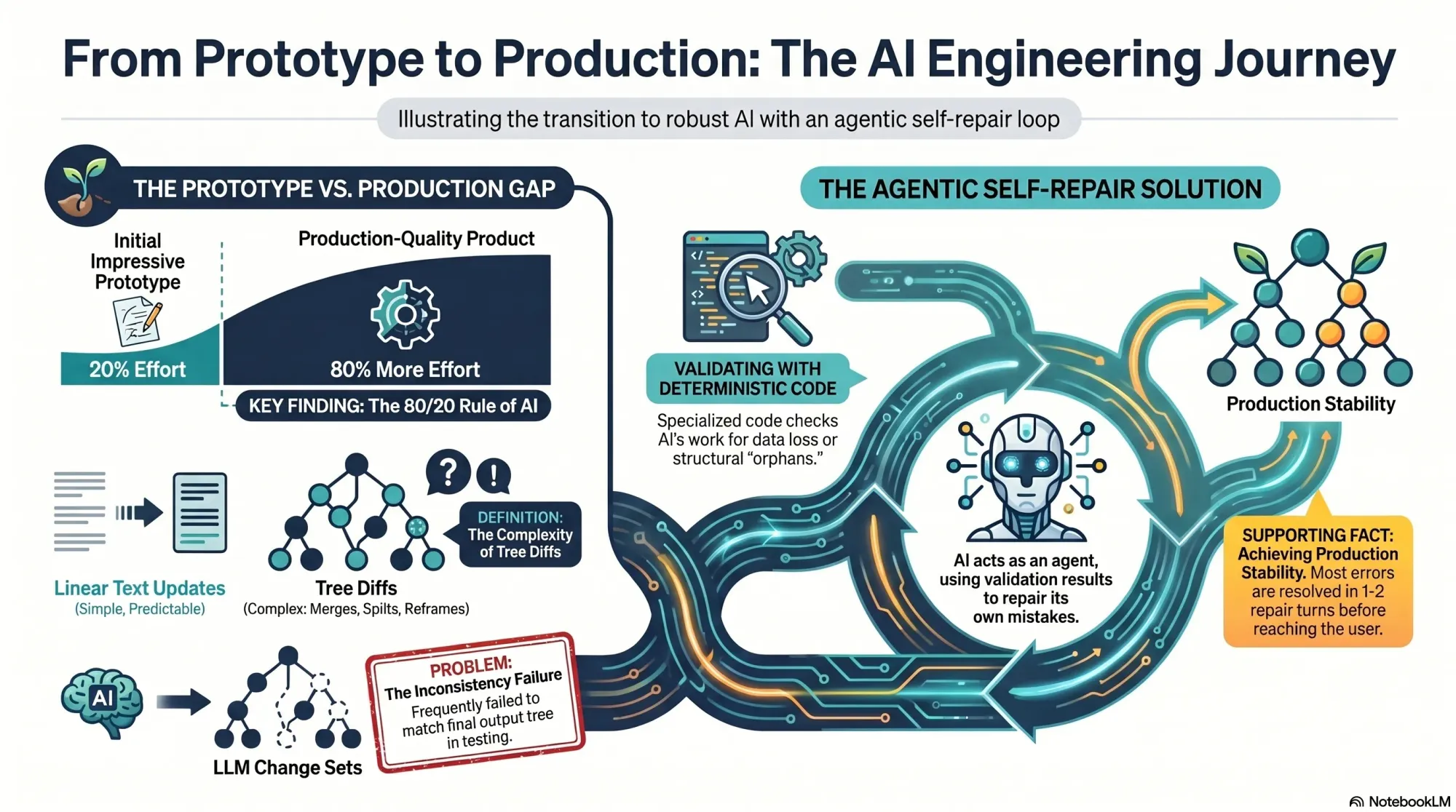
The Prototype Only Represents 20% of the Work
One of the themes that I hear often on my podcast Just Now Possible is that it’s fairly easy to get to an impressive prototype with AI, but that it’s much harder to get to a real production-quality product. This was exactly my experience.
My opportunity solution tree service is comprised of two sub-services: 1) generate a new tree from scratch and 2) update an existing tree based on new interviews.
The first service was part of our initial alpha and was working well. The second service had to be built from scratch before any of our design partners could add a fourth interview.
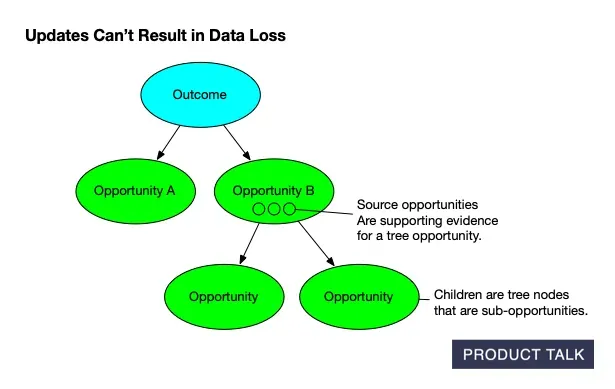
On the surface, these don’t seem that different, but they are. When you are updating a tree, you want to preserve as much of the existing structure as you can—unless the new content really warrants a structural change. You have to account for compound operations like merges, splits, and deletes. And you need to make sure you don’t lose any data. On the data front, each node in the tree has both source opportunities—interview opportunities that provide supporting evidence for the tree opportunity—and children—tree sub-opportunities.
But like with many AI products, I was pleasantly surprised when I got something working reasonably well in just a few days. I shipped it and our design partners started playing with it.
One design partner hit our beta limits quickly and asked if they could convert to a paid subscription so that they could get full access. We were thrilled. They showed a willingness to pay, converted, and immediately started uploading more interviews.
However, once they hit the 14th, 15th, and 16th uploads, my initial service design started to show some cracks. We started to see some odd behavior.
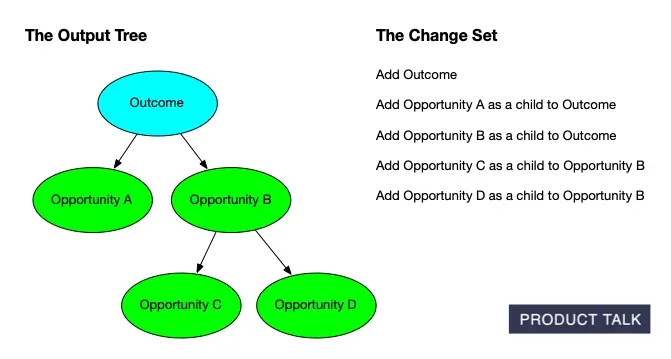
The Vistaly team noticed that the change sets—the step-by-step instructions emitted by my service—weren’t always generating the final tree emitted by my service. Remember, we wanted to be able to walk the customer step-by-step through what changed. So my service returned both the step-by-step instructions (the change sets) and the final tree.
The intent was that Vistaly could start with the current version of the team’s tree, apply the change set in the order I provided, and end up with the updated tree that my service emitted. But sometimes the tree that the change set generated was different from the tree that the service outputted.
Vistaly flagged this as a bug on the day I was flying to New Orleans for Jazz Fest. Looking back, I’m glad I had no idea what was waiting for me when I got home. I had about 80% of the work still left to do to make updating an opportunity solution tree a truly rock-solid product. Thankfully, I got to enjoy Jazz Fest first.
Uncovering the Full Scope of the Problem
When I got home, I started to diagnose the problem and I was quickly overwhelmed. My service was a pipeline that combined LLM steps with deterministic code.
At a high level, here’s how it worked: I had deconstructed updating an opportunity into a series of steps that could be done by an LLM. After those steps completed, deterministic code compared the output tree to the input tree and generated the change sets.
As I started to dig into the bugs, I realized this was not a good approach. Tree diffs, unlike linear document diffs, are ambiguous.
If I’m editing a document and I add a sentence, the diff is simple. It shows that a sentence was added. If I delete a paragraph and rewrite it, the diff shows the removal of the old paragraph and the addition of a new paragraph.
But if I split an opportunity A into two opportunities, A and B, and then later I merge B with C, the first move is hidden from the diff.
Let me walk you through why.
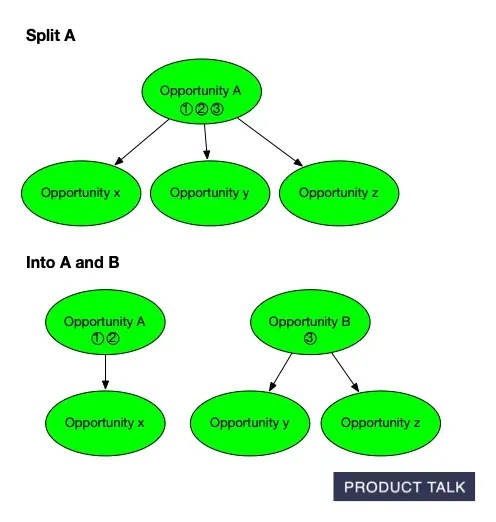
If the model decides to split an opportunity into two different opportunities, it has to figure out how to divide the original opportunity’s source opportunities (the supporting evidence) and its children (the sub-opportunities) across the two resulting opportunities.
For example, if we have opportunity A and we want to split it into A and B, we have to figure out which source opportunities and children belong on A and which belong on B.
Suppose A has source opportunities 1, 2, 3 and children x, y, z. After the split, we might end up with A having source opportunities 1 and 2 and child x and B having source opportunity 3 and children y and z. When the model decides to split an opportunity it has to distribute the source opportunities and children appropriately.
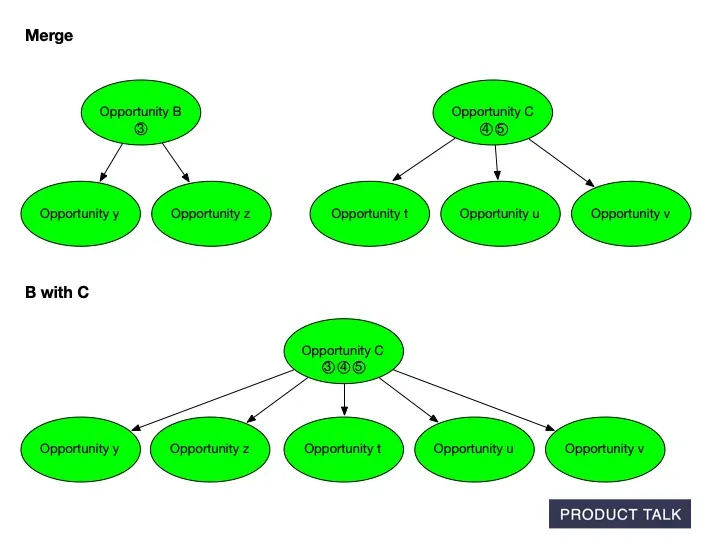
Now suppose the model decides to merge B with C. When two opportunities are merged, we have to combine all of the source opportunities and children. Remember, B has source opportunity 3 and children y and z. If C has source opportunities 4 and 5 and children t, u, and v, then after the merge C will have source opportunities 3, 4, and 5 and children t, u, v, y, and z.
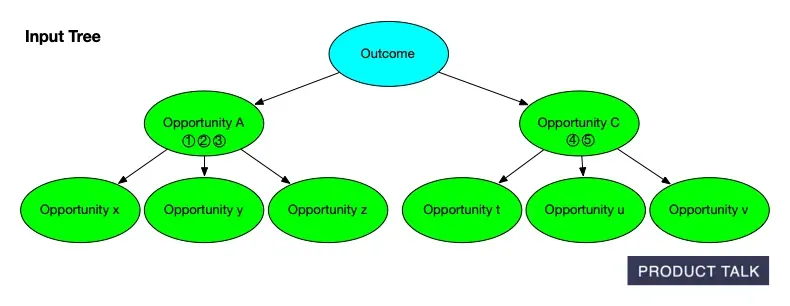
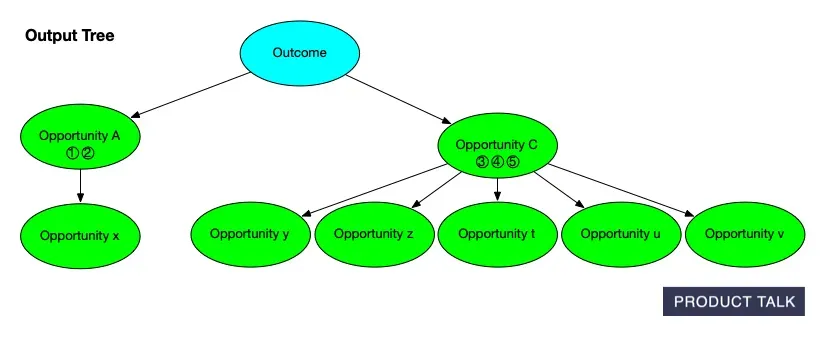
When we compare the input tree to the output tree, it looks like some of A’s source opportunities and children move to C, but we don’t know why. The split and the merge aren’t visible to the diff.
At the end, when we do a diff between our input tree and our output tree, we can’t see both the split and the merge. Our input tree had A with source opportunities 1, 2, 3 and children x, y, and z and C with opportunities 4 and 5 with children t, u, and v.
Our output tree has A with source opportunities 1 and 2 and child x and C with source opportunities 3, 4, and 5 and children t, u, v, y, and z. It looks to our diff like some of A’s sources and children moved from A to C. But we don’t know why. The split and the merge conceptually explain what happened, but those moves are invisible to the diff.
This is when I realized tree diffs were much harder than linear text diffs. We weren’t just trying to show the user what changed. We wanted to show the user why it changed so they could weigh in. I needed a way to reconstruct each move—step by step.
That meant I had to get the model to show its work. And that opened a whole new can of worms.
Asking the Model to Show Its Work
I decided to refactor all of my prompts to have the model generate both the final output and the step-by-step moves it took to get there.
My prompts already told the model what actions were possible: add, delete, reframe, merge, split, etc. But these were just guidelines. The model could do whatever it wanted to produce the final tree.
But now, I needed it to show its work. And I needed it to show its work in the language of our change sets—specific moves that we predefined that make sense to our end user. In other words, split A into A and B and then merge B into C has much more semantic meaning than simply saying move some of A’s sources and children to C arbitrarily.
For each LLM step, the model had to output its recommendation and the change set it used to generate the output. This worked fairly well. But, of course, the model made mistakes.
After a lot of testing and error analysis, I uncovered two categories of errors:
- The model tried to make a move that was not valid.
- The model had a discrepancy between the change set and the recommendation. (In other words, the change set didn’t generate the recommendation.)
Category 1 was interesting. It felt like I was designing a game and the model was a very creative player. It kept finding ways to break my game. For each of these errors, I had to decide if this move should be allowed and if so, how the model should represent that move using our actions. If the move shouldn’t be allowed, I had to let the model know.
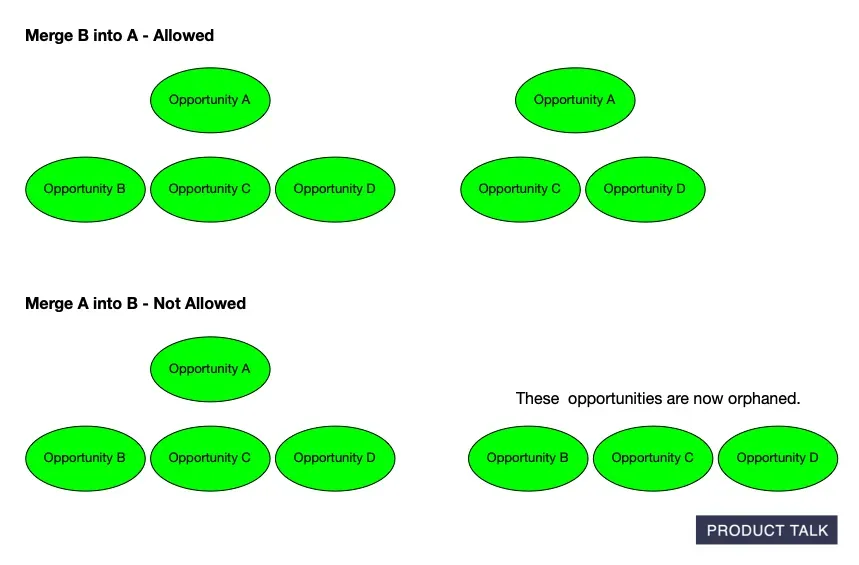
For example, the model tried to merge a parent with a child. This was a problem. Suppose opportunity A has children B, C, and D. If the model tries to merge A with B, what should happen?
A merge is directional. The model has to define which of the two to keep and which to delete.
If it defines the merge as keep A and delete B, the merge is allowed.
But if it defines the merge as keep B and delete A, what happens to B, C, and D? They no longer have a parent and are now orphaned.
These were fun errors to resolve. It was like solving little puzzles.
Category 2 was much harder. I had to go through several iterations of prompt design to nudge the model toward better output.
I was able to reduce these errors to about 1 in 40 instances. But each service run has 10–20 LLM calls, so that meant I was hitting this error in about 50% of service runs. Clearly, not good enough for a production product.
At some point, I hit a wall and couldn’t reduce this error rate any further. I felt stuck. And worried. We had a paying customer waiting for my fix. And several more design partners eager to try it out.
Trying to Correct the Model’s Mistakes in Code
I initially tried to correct the model’s mistakes with deterministic code. I had committed to Vistaly that my change sets would generate the output tree, so I needed code that verified this.
After the model generated a change set, I ran a number of quality checks on it. Were there any conflicts in the change set? A conflict might be the model deleted a tree node in one step and then later tried to use it in a merge in a subsequent step. Was there any potential data loss—were all of the source opportunities and children accounted for? Did the model orphan any tree nodes? And so on.
I thought, if I can detect these problems, maybe I can correct them. But to do that, I had to guess at what the model intended.
If the model had the following sequence in its change set—delete A, then merge A with B—what did it mean? Should I delete A or should I merge its source opportunities and children with B?
There were dozens of cases like this with no easy answers.
At this point, I was 11 days into working on this full time from the moment I woke up to the moment I went to sleep (including weekends). I don’t say that as a humble brag. I hate hustle culture and this is not how I designed my life. I share this because I want you to understand the context. I was stuck and I was exhausted. And then I had an insight.
Let the Model Correct Its Own Mistakes
I was walking my dog with my husband. He is also an engineer and he had been hearing about my ups and downs over the past several days. As I explained my stubborn failure mode to him, I had an insight. I realized I could have the LLM repair its own mistakes.
My data contract with Vistaly requires that my change set generates the output tree. This was the core bug. This wasn’t happening 100% of the time. Over the previous week, I had written a lot of code to validate change sets.
I now knew exactly when a change set generated the wrong tree. But no matter how much prompt engineering I did, I couldn’t reduce the error rate.
My core insight was that I could use this same validation code as a tool for the agent. The agent could generate the change set, call the tool, and then get the results. If the change set was invalid, the agent would get instructions on what needed to be fixed. The agent would continue to work until the validation passed.
This was a simple idea. But could I get it to work? And more importantly, could I get it to work without blowing through a ton of compute?
I started by prototyping a solution. I wrote a simple Node.js script that made one LLM call, got the result, ran it through my verifier, and then sent the feedback to the LLM for corrections.
Initially, it didn’t work at all. The model just kept introducing more mistakes. The loop never converged to a valid solution. It just racked up compute.
But I kept trying. I experimented with how to communicate the errors to the LLM. I experimented with how much context to give it about the larger problem. And eventually, I got it to work. The model was fixing its own mistakes and returning a valid change set after one or two repairs.
I was thrilled. But I still had to turn it into something I could run in production. And that’s when I remembered: I had already built an agent loop utility to support my AI interviewer.
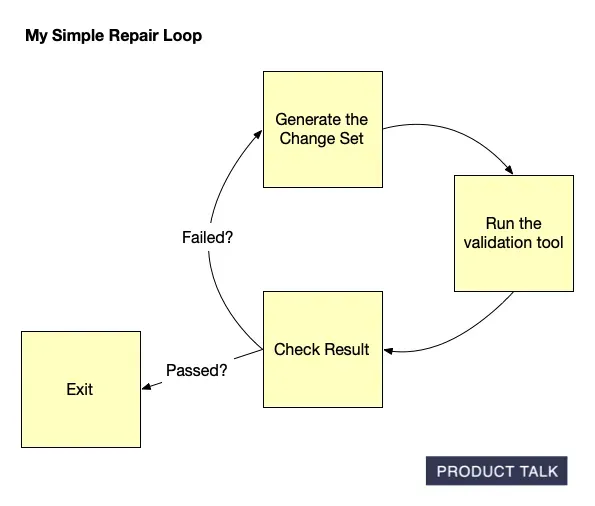
Here’s what my final production implementation looks like. I have a pretty standard agent loop. It starts with a model call. The model can output a tool request. The loop runs the tool and sends the tool result back to the agent. It iterates until the tool (my validation code) returns a success signal or until we hit the max turns that I set in my code.
The initial model call is the tree-building task. The tool call runs my validation code. If the change set passes validation, the tool emits a success signal and the loop exits. If the change set fails validation, the tool returns simple instructions for the model to fix the errors. The model attempts to fix the errors and calls the validation tool again. My insight led to a feasible solution.
Errors are still theoretically possible. The repair loop can fail and hit max turns. But I haven’t seen it in all of my testing. The agent typically fixes the bad change set in one to two turns.
I had that insight last Thursday. I worked through the weekend to prototype it, test it, and validate that it could work. I then built a production-quality version and integrated it into my pipeline. I shipped my completely revamped service to Vistaly on Monday at noon. They are working on integrating it and it will be available to our design partners shortly.
I was relieved. And ready for a day off.
Some Reflections on the Whole Process
The last two weeks were intense. But I learned a lot and I mostly enjoyed the process. I want to share some key reflections with you.
- I have a lot of limiting beliefs around being an engineer. I shed a lot of those beliefs over the last two weeks. To make this work well and to make it work reliably, I had to solve some legitimately hard problems. That feels good.
- This work was genuinely fun. I loved the puzzle part of designing an action set and then seeing how the model pushed that design beyond its intended limits. Models are incredibly creative and it was fun to see what it would do with a fixed toolset.
- I learned a lot about when I can and can’t trust Claude to write code for me. Since Opus 4.6 came out, I gave Claude a much longer leash. After the past two weeks, Claude is back on a short leash. I found a lot of gaps in my implementation in areas where I simply trusted that Claude got it right, when in fact it didn’t. I know the foundation labs are claiming that the models write most of their code, but I’m learning if you don’t have the right infrastructure in place, this can be disastrous. I’ll be investing much more in my planning, testing, and code-review tools over the next couple of weeks. And, of course, I’ll share here as I do.
- If this work was spread out over two months, it would have been thoroughly enjoyable. I’m learning I really enjoy being an AI engineer. I was ready for a new chapter and I am even more confident this is it. It’s fun to combine my past work—opportunity solution trees—with my new interests—AI engineering.
I’m really excited to share the work Vistaly and I are doing together with more people. We’ll be adding more design partners soon. You’ll be the first to know when we do. In the meantime, get on the waiting list.
And finally, it’s still surprising for me to look back at the last 15 months and see how much I’ve learned and progressed in a whole new field. I have fully embraced what is just now possible. I hope by sharing my story, I inspire you to take the first small step toward what’s just now possible for you.
Audio Version
The audio version is only available for paid subscribers.


![how-to-write-a-group-product-manager-resume-[+-examples]](https://prodsens.live/wp-content/uploads/2022/10/4509-how-to-write-a-group-product-manager-resume-examples-380x250.jpg)