By Aashi Dutt and Sayak Paul(AI GDEs)

If you’re using LLMs to evaluate other LLMs for tasks like ranking answers, scoring outputs, and choosing a winner, you immediately run into uncomfortable questions:
- Does a judge favor its own vendor?
- Does it prefer “thinking” tiers over “fast” tiers?
- Does revealing model identity (hinting) change outcomes?
- Are results stable across domains like writing, coding, and reasoning?
We took the MT-Bench benchmark and ran experiments to answer those questions with a reproducible pipeline. You can check out the complete code on GitHub here.
GitHub – AashiDutt/LLM-Eval: Testing LLMs on various experiments
Problem Setup
A judge model can be biased, sensitive to metadata (hinting), prompting, and several other hyperparameters like temperature.
Therefore, we set out to answer:
How to build an evaluation pipeline where model answers are generated consistently, judged under controlled conditions, and analyzed statistically , while being robust to structured-output failures?
Models Used
To keep the evaluation comparable across vendors and our findings meaningful, we tested two tiers per model family, i.e., a “fast” tier and a “thinking” tier. Each vendor contributes one model per tier, so every prompt is answered by six generators total (2 per vendor × 3 vendors).

This setup lets us analyze not just which vendor wins, but also how the fast vs. thinking tier affects win rates and judge bias.
Evaluation Pipeline
At a high level, each experiment follows a three-step loop:
- Generate answers from a fixed set of candidate models, including Claude, GPT, and Gemini, with both fast and thinking tiers.
- Judge the answers using LLM judges, either blind (no identity shown) or with hinting modes.
- Analyze bias breakdowns by judge, vendor, tier, and domain/category.
Pipeline Overview
Our repo is split into two layers: an evaluation framework and self-contained experiment folders. The framework provides the building blocks for answer generation, judging, and analysis, while the experiments folder holds the configs, prompts, notebooks, and outputs for each study.
Core Framework
The src folder contains the code that generates answers from multiple model families, packages anonymized answers for judging, runs LLM-as-a-judge comparisons, and aggregates results for bias analysis. It includes:
- models.py: It provides wrappers for Claude, GPT, and Gemini for centralized calls.
- generate_answers.py: It runs each prompt through every configured answer model and writes answer artifacts to disk.
- judge_answers.py: This file implements the judging loop, which builds judge packets (including prompts and anonymized answers, optionally with hint text depending on the experiment), collects rankings, and saves judgment artifacts.
- analysis.py: It loads answers, judgments, and computes the summary statistics, including win rates, self-preference rates, and other bias breakdowns.
- utils.py: This file contains utilities that are used across generation, judging, and analysis.
Experiments
Each experiment resides in its own folder within the experiments/ directory, making it easy to run controlled comparisons without modifying the core framework. The repo includes:
- exp1_blind_judge/: Blind-judging baseline
This is the sanity check experiment, which we used to validate the evaluation setup end-to-end with blind (anonymized) answer packets. It helped establish the initial signal whether judges show self-preference before scaling to MT-Bench. - exp2_mt_bench/: MT-Bench domain analysis
We next experimented on the official MT-Bench first-turn prompts. The goal was to measure how bias changes by task type (writing, roleplay, math, reasoning, etc.) and analyze cross-judge patterns. - exp3_hinting/: Hinting study
This experiment isolated identity effects, such that it reuses the same MT-Bench answers and reruns judging under controlled hinting modes (self-only, competitors-only, full, none). So, any change in outcomes can be attributed to identity cues rather than answer regeneration noise.
MT Bench: MT-Bench is an 80-question, multi-turn benchmark by LMSYS to evaluate chat assistants on open-ended instruction following and conversation quality. It is organized into 8 prompt categories: writing, roleplay, extraction, reasoning, math, coding, STEM, and humanities, with 10 questions per category.
Recovery Utilities
In addition to the core framework, we also added two utility scripts within utils.py:
- regenerate_dubious_answers.py: This script helps to regenerate flagged answers or those that were truncated due to model limits.
- regenerate_failed_judgements.py: This script retries judgments that failed due to issues like errors or timeouts.
Note: All experiments assume 33.33% as the baseline, which assumes equal odds across 3 vendors. While real baselines can differ with answer quality and prompt mix.
Observations
Experiment 1: Blind Judge Evaluation
Goal: Does a judge show self-preference when answers are anonymous?
Setup:
- Answers: Anonymized (A, B, C, D, E, F)
- Prompts: 10 mixed prompts across 6 categories
- Hinting: None (blind evaluation)
- Output: Win-rate matrix (judge vendor × answer vendor (Top-1 selections))
Note: This experiment is a preliminary study that helped us gain insight and inform the next steps of the project.
Key findings:
In this experiment, we ran blind judging where judges ranked anonymized answers (A–F) with no model identity cues. We then measured each judge’s Top-1 selection rate (Figure 1) by answer vendor and self-preference, defined as the frequency with which a judge selects their own vendor’s answers as Top-1 compared to other vendors.
*We opted for thinking-tier models as judges only.
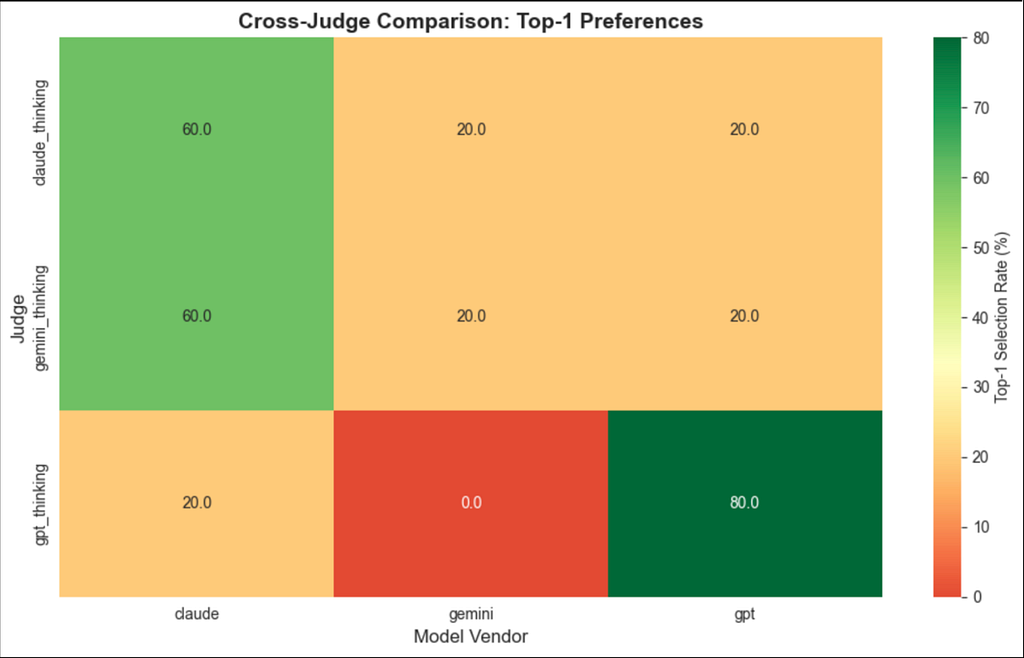
From the above heatmap:
- GPT shows strong self-preference bias (80% vs 20% from other judges)
- Gemini is impartial as it only ranked itself #1 at 20%, which is below baseline.
- Claude and Gemini judges agree that Claude wins most often, while the GPT judge heavily tilts toward GPT.
Experiment 2 : Cross-Judge Preference Analysis
Goal: Does judge bias vary across different domains/task types?
Setup:
- Answers: Anonymized (A, B, C, D, E, F)
- Prompts: 80 MT-Bench style prompts
- Hinting: None (blind evaluation)
- Judgments: 480 (80 prompts × 6 judges)
- Output: Self-preference by category
Temperature settings: We used two different temperature regimes: one for answer generation and another for judging.
- Answer generation (all vendors): For answer generation, we use a temperature of 0.7 to keep outputs diverse enough that the benchmark isn’t dominated by overly conservative, safe completions. Claude and Gemini apply this setting as expected, while the GPT-5 family does not expose temperature in this setup, so the value is effectively ignored for those models.
- Judging: For judging, we used model-specific temperatures to prioritize stable, repeatable rankings (where supported).

Key findings:
Self-Preference Detection
We measure self-preference as the percentage of times a vendor’s judges rank their own vendor as Top-1(Table 3) when answers are anonymized. The results are compared against a naive, unbiased baseline of 33.33%.
Note: Values below are aggregated across fast and thinking tiers within each vendor.
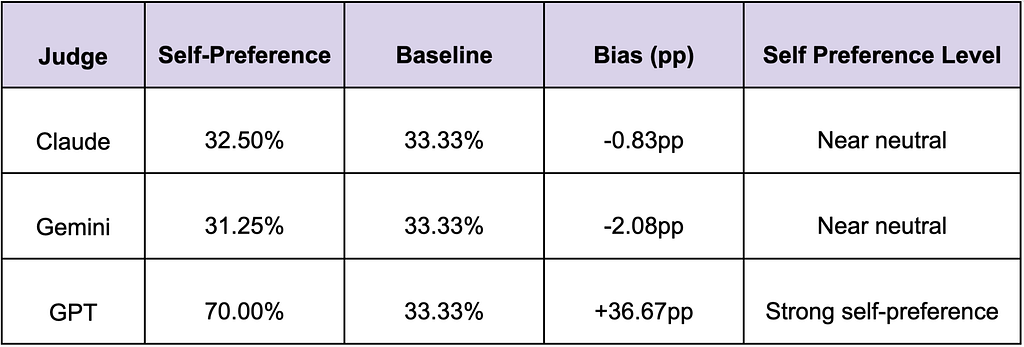
*Bias (pp): Difference from expected in percentage points (pp = percentage points (arithmetic difference between percentages))
Cross-Judge Comparison
Next, we looked at who each judge family selects as Top-1 overall (columns are vendor-level aggregates across tiers).
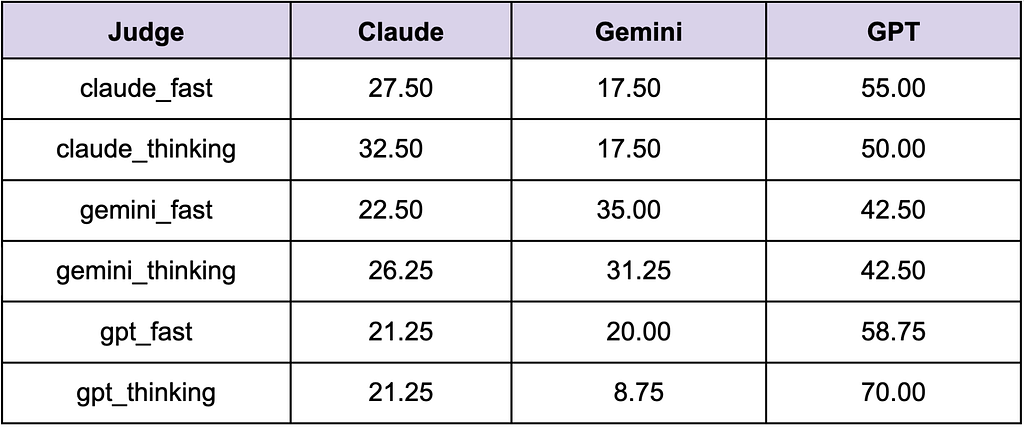
From the above table, we learnt that:
- GPT is the most frequent Top-1 winner across every judge family, not just GPT judges.
- GPT judges amplify GPT wins relative to non-GPT judges, compared to 70% for gpt_thinking vs ~50% average GPT selection by non-GPT judges from this table.
Tier Effects via Score Distributions
To check whether “thinking” tiers systematically score higher, we compare mean ± std scores (0–10) assigned by a single judge (Gemini Thinking) to each vendor’s fast vs thinking models across 80 prompts.

Thinking tiers score higher for all vendors (≈ +0.7 to +1.5 points here), but variance remains non-trivial across prompts.
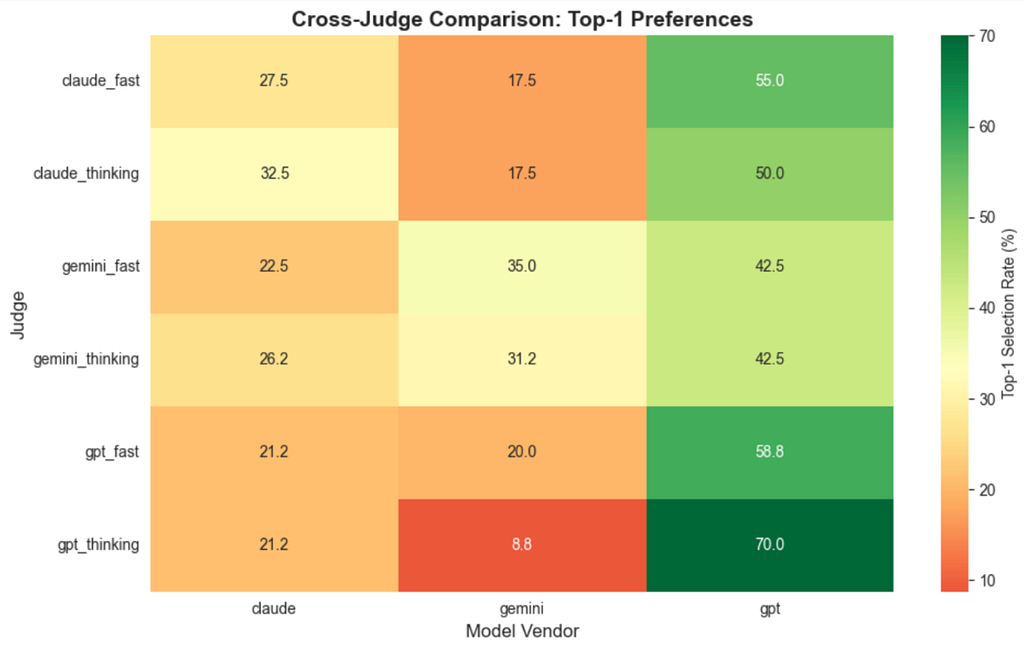
Overall, this experiment led to the following results:
- Judge choice: Depending on the judge vendor, the “best model” changes dramatically across domains. Figure 2 shows that GPT has strong self-preference bias (70% vs 33% expected), but GPT answers are also frequently selected by non-GPT judges. This shows genuine quality advantages of GPT.
- Self-preference varies by domain: GPT’s self-preference is strongest in creative domains (Writing: 90%, Roleplay: 85%), while Gemini shows strong self-preference in its core strengths (Math: 80%, Reasoning: 60%). Claude maintains a relatively impartial judgment across all domains.
- Cross-judge agreement: When multiple judges agree on a winner (like GPT in Writing, Gemini in Math), it suggests genuine domain-specific strengths rather than just judge favoritism.
Experiment 3 : Hinting Effect
Goal: Does revealing identities change judge behavior?
Setup:
- Answers: Anonymized (A, B, C, D, E, F) — 6 models (2 per vendor × 3 vendors)
- Prompts: 80 MT-Bench style prompts
- Hinting: 4 modes (self, competitors, full, none)
- We reuse the same answers from Experiment 2 (to avoid answer-generation noise) and re-run only the judging under different identity-hint conditions.
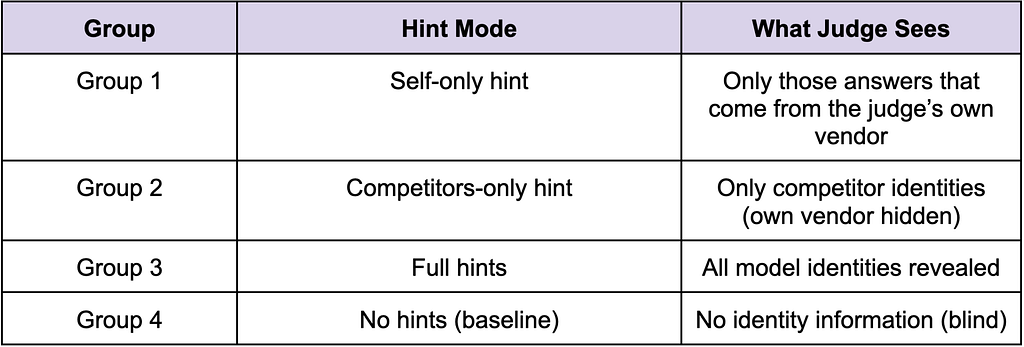
Hinting Modes
For the hinting experiment, the same judging pipeline is re-run under different identity visibility settings to test whether exposing model names changes judge behavior or not.
The logic goes as follows(refer Table 6):
- none: No hints at all (fully blind)
- self: Judge is told which answers are from its own vendor
- competitors: Judge sees competitor vendor tags, but its own answers are redacted
- full: Judge sees all vendor labels
Note: Hints are appended after the answers list, so the judge still sees the full content first.
Key findings:
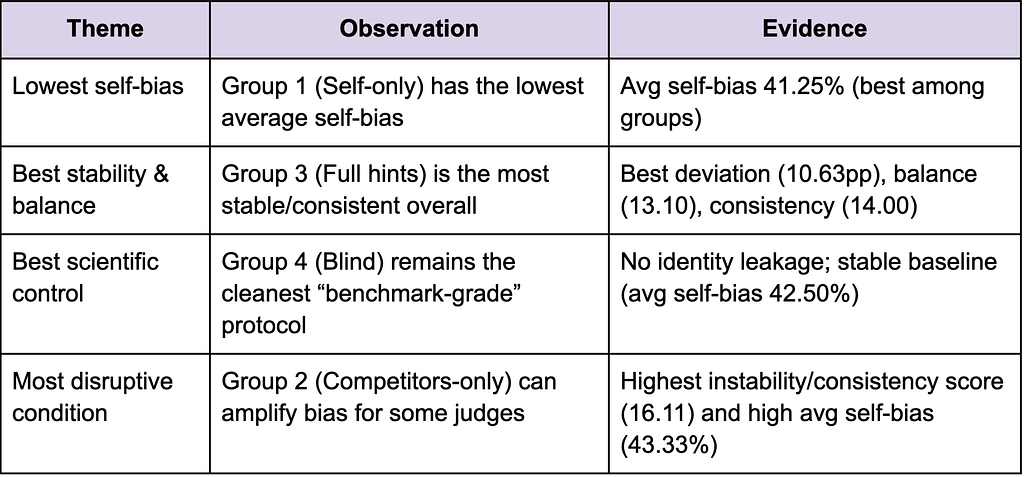
Hints do change judge behavior, but there isn’t a single best setting for every goal. Self-only hints reduce average self-bias the most, while full hints produce the most stable and balanced vendor-level outcomes.
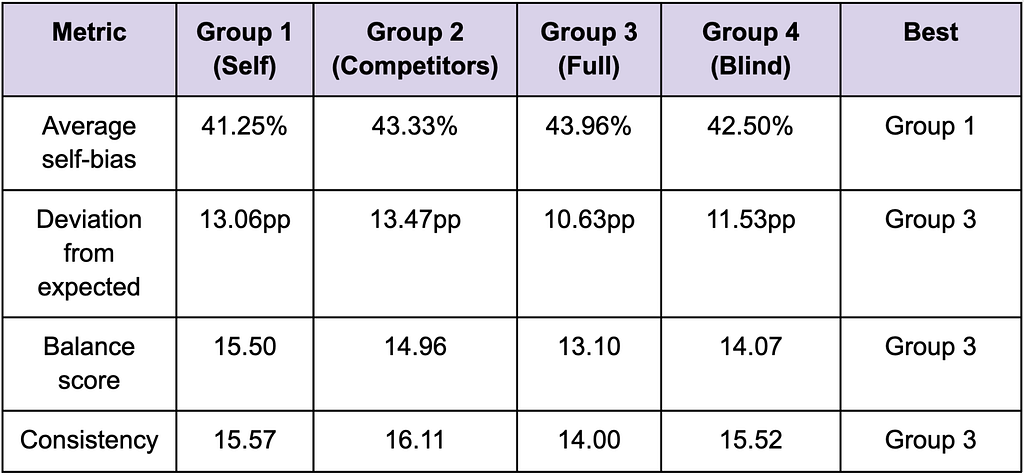
Main Metrics Comparison
We compared the four hinting groups across key metrics. Lower values are better for all metrics as evident from Table 8. A low Balance Score is about “evenness,” not necessarily “fairness.” It can improve simply because judges spread wins more evenly.
Vendor-Level Behavior Shifts
Self-bias rates for each vendor across different hinting groups, aggregated across fast and thinking tiers. The following Table 9 shows the percentage of times each vendor’s judges rank their own vendor’s answers as #1(aggregated across fast and thinking tiers).

We found that GPT judges show consistently high self-bias across all hinting groups, while Claude judges exhibit the lowest self-bias, particularly in Group 1 (Self-hint) at 25.6%. While Gemini judges show moderate self-bias with Group 2 (Competitors-hint) producing the lowest rate at 28.1%.
Domain-Wise Analysis
We calculated the average self-bias rates by category for each hinting group(Table 10), aggregated across all vendors and tiers. The best Group column below indicates which hinting mode produces the lowest self-bias for that category(aggregated across fast and thinking tiers).

Note: These category results are directional, so we treat them as pattern hints and not definitive rankings.
Competitors-Only Hinting
In the competitors-only condition(Figure 3), judges see only the competitor labels, and their own vendor’s identity is not revealed. Even with that constraint, most judges still select GPT answers as Top-1, and this effect is especially strong for GPT-thinking. While Claude and Gemini judges also tilt toward GPT under this framing.

A key takeaway from this was that competitor-aware labeling doesn’t neutralize bias. However, it can amplify skew and increase variance across judges, and in this run, it concentrated Top-1 wins toward GPT rather than distributing them more evenly.
Practical Recommendation
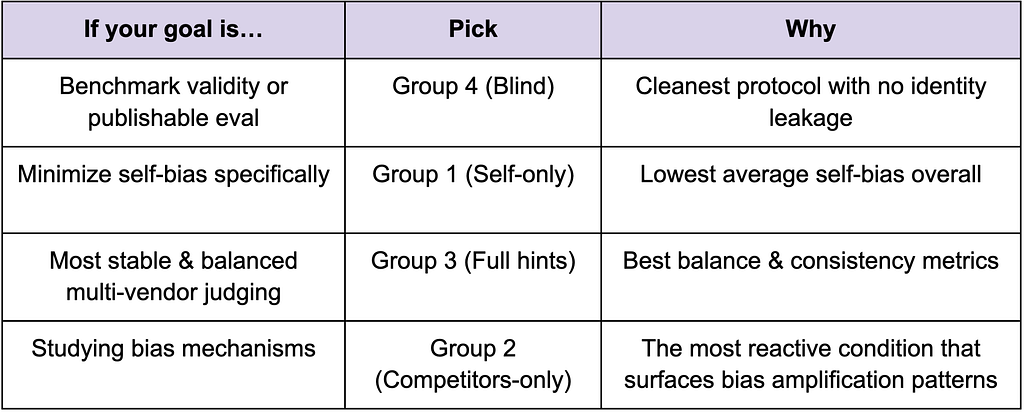
Conclusion
In this project, we studied various closed-source models on the MT-Bench benchmark and critically assessed their biases under different scenarios. There were some interesting revelations, such as GPT responses being favored highly even with non-GPT models as judges. We plan on extending this project to more benchmarks and also multimodal scenarios. We invite you to check out the code on GitHub if you want to extend some experiments yourself.
As future work, it would be interesting to see if the above trends would apply to other popular benchmarks, as well.
Acknowledgement:

Developed during Google Developers ML Developer Programs AI Sprint 2025 H2, this project benefited from generous GCP credits that facilitated its completion. We express our gratitude to the MLDP team for the support provided. Sayak Paul acknowledges the support he received from Hugging Face in terms of the API credits.
![]()
LLMs as Judges: Measuring Bias, Hinting Effects, and Tier Preferences was originally published in Google Developer Experts on Medium, where people are continuing the conversation by highlighting and responding to this story.

