Finetuning the FunctionGemma model is made fast and easy using the lightweight JAX-based Tunix library on Google TPUs, a process demonstrated here using LoRA for supervised finetuning. This approach delivers significant accuracy improvements with high TPU efficiency, culminating in a model ready for deployment.
Easy FunctionGemma finetuning with Tunix on Google TPUs
Related Posts

How has the software dev job gotten worse in the last few years?
I’m wondering in which was you feel like the job has gotten worse over the last 3-4 years…

#51 - Get Rankings of Excel Rows in Each Group While Retaining the Existing Order
Problem description & analysis: We have an unordered Excel table, where the 1st column is the grouping column…
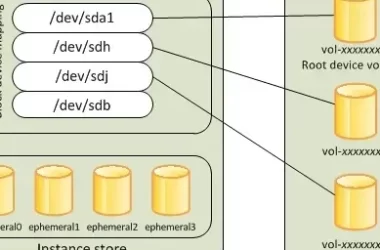
How I Attached and Mounted an EBS Volume to My Ubuntu EC2 Instance
Introduction: What Is Amazon EBS and Why Does It Matter? Amazon Elastic Block Store (EBS) is AWS’s scalable,…