
A deep dive into a real-world pilot study that’s proving how Gemini can turn raw environmental audio into actionable, financial-grade conservation insights.
There’s a language hidden in the rustle of leaves, the chorus of birdsong, and the distant rumble of thunder. For a nature finance firm, decoding this language isn’t just a matter of curiosity — it’s essential for verifying the health of an ecosystem and the success of a conservation project.

As a developer passionate about conservation technology, I embarked on a groundbreaking collaboration with Darukaa.Earth, a pioneering nature finance firm. The goal was to test a powerful hypothesis: could Google’s Gemini 2.5 Flash process complex, real-world bioacoustics data and provide the high-quality insights needed for their work?
Darukaa.Earth provided the perfect test case: a rich dataset of acoustic recordings collected from one of their mangrove restoration projects in the Sundarbans with South Asian forum for Environment. This project was a true team effort, and I want to extend a special thanks to Harsh Kumar from the Darukaa.Earth team, whose expertise was instrumental in making this pilot a success.
The preliminary results have been incredibly encouraging. We’ve proven that Gemini can effectively classify the soundscape, identify critical threats, and lay the groundwork for biodiversity monitoring. Based on this success, Darukaa.Earth is now set to explore the integration of Google’s Gemini stack at a production scale. This is the story of how we did it.
The Backbone: Site-Specific Fine tuned Model
At the core of our system is a deep learning model built for bird sound recognition, fine-tuned specifically for the geolocation of our audio data. This site-specific approach allows us to more accurately identify the birds found in that local habitat. Before diving into the components, here is a high-level look at how raw audio data becomes an actionable conservation insight.

Step 1: Capturing Natural Audio with AudioMoth
Our pipeline begins in the wild. We use AudioMoth devices — low-cost, full-spectrum acoustic loggers — to perform field-collected audio recordings. Deployed in forests, wetlands, and other habitats, these devices are our ears on the ground, capturing the complete soundscape.

Step 2: Preprocessing the Audio with Librosa
With the raw audio data collected, the next step is standardization. This is a crucial preprocessing step to ensure compatibility with both Gemini and our fine-tuned BirdNET model. We use Librosa, a powerful Python library for audio analysis, to standardize all recordings to mono 48kHz.
Here’s the simple yet effective Python snippet for this process:
import librosa
import soundfile as sf
# Load audio at a 48kHz sample rate, and convert to mono
y, sr = librosa.load("input.wav", sr=48000, mono=True)
# Save the cleaned audio file
sf.write("cleaned.wav", y, sr)
Step 3: The Gemini 2.5 Flash Breakthrough
This is where the game changes. Instead of building complex, rule-based classifiers, we leveraged Gemini 2.5 Flash’s native audio processing and natural language understanding. Using LangChain to structure the interaction, we can analyze environmental audio directly.
Here’s the heart of our integration — the LangChain prompt template that instructs Gemini:
from langchain.prompts import PromptTemplate
from langchain_google_genai import ChatGoogleGenerativeAI
# Gemini 2.5 Flash for audio classification
gemini_model = ChatGoogleGenerativeAI(
model="gemini-2.5-flash",
temperature=0.1
)
prompt = PromptTemplate(
template="""
Analyze this environmental audio and classify each
segment:
- Split audio into 15-second chunks
- Classify as: Anthrophony, Biophony, or Geophony
- Flag dangerous sounds (chainsaws, gunshots)
- Return structured JSON with timestamps and summaries
"""
)
Gemini automatically segments the audio and returns a structured JSON analysis. This output is clean, immediately usable, and packed with insight.
Here’s an actual example of the JSON returned by Gemini:
{
"chunks": [
{
"start_time": "00:00",
"end_time": "00:15",
"classification": "Biophony",
"sub_classification": "Bird",
"summary": "Bird calls detected in the early morning.",
"alert": false
}
],
"total_chunks": 1,
"class_counts": {
"Anthropophony": 0,
"Biophony": 1,
"Geophony": 0
},
"alert_present": false
}
Step 4: The Gemini-to-BirdNET Pipeline for Species Identification
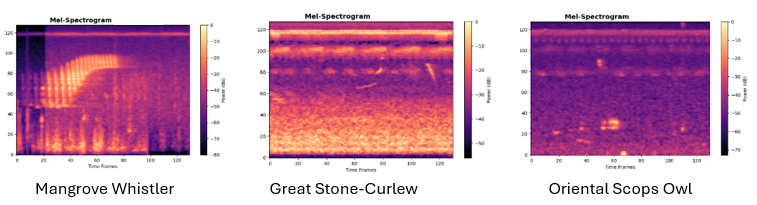
When Gemini detects bird sounds (“Biophony”), the audio is intelligently routed to our site-specific BirdNET model. BirdNET converts audio into mel spectrograms — visual representations of sound frequency — and uses deep neural networks to identify species. Because our BirdNET model is trained on local species data, it achieves far higher accuracy for regional bird populations than generic models.
Step 5 & 6: AI-Generated Summaries and Threat Detection
The final, and perhaps most crucial, steps are turning this analysis into action. Whether it’s a bird identification or a broader sound classification, Gemini automatically generates a summary of the event.
Examples of Gemini-generated summaries:
- “A chainsaw was heard, indicating possible forest disturbance.”
- “Bird songs dominate the audio, suggesting a healthy dawn chorus.”
- “Heavy rainfall masks most biological sounds in this segment.”
If Gemini classifies a sound as anthrophony and identifies it as a potentially harmful category — such as a chainsaw, motor boat, generator, vehicle engine, or gunshot — the system generates an immediate alert for conservationists.

The Technical Stack Powering Conservation
The EcoChirp.AI project is a testament to the power of a well-integrated technical stack:
- AI/ML: Gemini 2.5 Flash, BirdNET, LangChain
- Audio Processing: Librosa, AudioMoth hardware
- Backend: Python, FastAPI
- Frontend: React
The Future of Conservation Finance is Here
The intersection of artificial intelligence and environmental monitoring is opening up incredible new possibilities not just for conservation, but for the financial mechanisms that support it. Our pilot project with Darukaa.Earth demonstrates the practical, scalable applications of cutting-edge AI like Gemini 2.5 Flash in translating the complex language of nature into verifiable, actionable intelligence.
By empowering organizations with the tools to listen and understand, we can build more trust and transparency into nature-based investments and accelerate the protection of our planet’s precious biodiversity.
This work is just beginning. To follow the journey of Darukaa.Earth and see how this technology gets deployed at scale, connect with them here:
- Website: https://www.darukaa.earth
- LinkedIn: Darukaa
![]()
Gemini Listens: Decoding the Soundscape of the Sundarbans was originally published in Google Developer Experts on Medium, where people are continuing the conversation by highlighting and responding to this story.




