Back in March, I was still struggling with how fast everything was moving with AI: RAG, MCP, agents, tools, evals, prompt engineering. It was a lot.
Don’t get me wrong. I was using ChatGPT and Claude in the web browser every day. But I was struggling to keep up with how fast everything was moving.
Then I broke my ankle. After surgery, I was sent home with a pair of crutches, some heavy-duty pain meds, and told to stay off my feet for at least three months. Suddenly, I was facing countless weeks with my leg propped up on the couch and nothing to do.
So I thought to myself, “What better time to catch up on AI?” Boy, did I jump down a rabbit hole. As I shared previously, I am particularly interested in how I can use AI to help people build discovery skills. I know, big surprise. So I started experimenting.
Along the way, I learned. I had to:
- Recognize which problems were best suited for an AI-shaped solution
- Figure out how to prototype and who to test with
- Choose the right architecture pattern and UX (spoiler: it wasn’t chat)
- Get it to work consistently across many types of user input
- Acknowledge that this investment would be continuous (Oh, the irony!)
- Understand the ethical responsibility that comes with the requisite data collection
Looking back on the journey so far, I realize that I’ll probably go through this again and again for every AI feature/product that I build. And then I realized, it might help you as well.
So let’s dive in.
Recognizing AI-Shaped Problems

Everybody is rushing to add AI features to their roadmaps as if it’s the gold rush. And it might be the next gold rush.
Call me old-fashioned, but I always want to work in the context of a real customer need, pain point, or desire. I want to build something that helps people. But oddly enough, this wasn’t where I started.
I started by asking, “What does generative AI make just now possible?” The key, however, is I didn’t jump straight to solutions. Instead, I asked, “What opportunities am I seeing where AI might help?”
I revisited my interviews and my opportunity solution tree (yes, I really do use these). I looked for opportunities that were previously hard to solve, where our current solutions were inadequate, or where people were putting in a lot of work to make the solutions feasible.
There were two that jumped off the page:
- It takes too much time to create interview snapshots.
- Is my customer interview any good?
I knew these were evergreen opportunities that I had heard countless times. I had been chipping away at them—writing blog articles, hosting webinars, and teaching our Continuous Interviewing course (which covers both topics)—for years.
I also liked that I had a lot of domain expertise to start from. I knew to get an AI to do something reliably well, I’d have to give it the right context. And I thought our course content would be a great place to start.
But would an AI solution work well enough? I didn’t want to risk a mediocre solution. We’ll explore how I answered that question shortly.
First, let’s recap how to recognize AI-shaped problems:
- Start with customer needs, pain points, and desires (AKA opportunities).
- Look for opportunities that were previously hard to solve, where current solutions are falling short, or where human involvement makes it hard to scale.
- Also, look for opportunities where you have some unique domain expertise. This helps you avoid me-too features and helps to build a moat between you and your competitors. It also sets you up to provide the right context to your AI helper (more on that in a bit).
Finally, it can help to use generative AI tools regularly to get a sense for what they are good at and what they are not good at. These tools have both strengths and weaknesses. The best way I’ve found to identify which are which is to play at the edges. And, of course, to experiment.
2. How to Prototype and Who to Test With
Now that I had identified a couple of potential target opportunities, I needed somewhere to experiment.
I started in a ChatGPT project and a Claude project right in the web browser. These are the same tools that you have access to for $20 a month each.
What are Claude Projects and ChatGPT Projects?
Projects in both of these LLM tools are available via their web interfaces (claude.ai and chatgpt.com). They allow you to define custom instructions/system prompts that are used across all chats that are started inside that project. They also allow you to upload files that can be referenced from any chat in the project. They are a good way to set up shared context across multiple chats.
I wanted to see what each could do. I started with a simple prompt that covered both opportunities. This wasn’t fine-tuned. I just wanted to see what I was working with.
This was the exact prompt that I used:
You are an expert in Teresa Torres' method of story-based customer interviews, identifying opportunities, and generating interview snapshots.
You can learn about each of these concepts here:
Story-based customer interviews: https://www.producttalk.org/2024/04/story-based-customer-interviews/
Identifying opportunities: https://www.producttalk.org/2023/02/sourcing-opportunities/
Interview snapshots: https://www.producttalk.org/2024/02/interview-snapshot/
If I ask you to help me identify opportunities:
- Ask me to upload a transcript of the interview
- Go through the interview and identify opportunities.
- Opportunities are unmet customer needs, pain points, and desires
- If a customer has solved a need, pain point, or desire, you can still include it in the opportunity list, but highlight what their existing solution is
- Opportunities should be specific: they occur in a specific moment in time and are unique to each customer, they occur in a specific context.
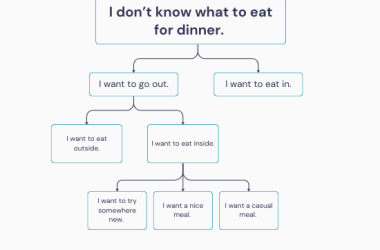
- Frame opportunities from the customer's point of view: "I'm hungry", "I don't know what to eat for dinner."
- Go step by step and review your work.
If I ask you to evaluate how well the interviewer collected a story:
- Ask me to upload a transcript if you don't already have one
- Evaluate how the interviewer did using the Eliciting a Story rubric and the Active Listening rubric (in the project files)
- Provide feedback on what the interviewer did well and what they should keep practicing.
The rubrics referenced in that last section were rubrics I had already designed to help our students give each other feedback on their own customer interviews. This is why domain expertise matters so much. I had spent years refining these rubrics based on what actually helped students improve. That domain knowledge became the foundation for teaching the AI.
Can Claude and ChatGPT identify opportunities?

Next, I uploaded an interview transcript and asked it to identify opportunities. ChatGPT hallucinated interview quotes and didn’t follow any of my guidelines on what an opportunity was or how to frame one. Claude, on the other hand, was surprisingly good. At first glance.
And here’s where I reached the first critical turning point in this story. I was 30 minutes into this adventure and I already started to ask myself, “How do I know if this is any good?” And that’s when I set up my first experiment.
I took 15 interviews that I had previously conducted where I also had interview snapshots and I ran them through Claude. I asked Claude to identify opportunities and I compared Claude’s results to mine.
Here’s how the first transcript went:
- I identified 15 opportunities
- Claude identified 18 opportunities
- Claude identified eight opportunities that I missed!
- One was the same as mine, but Claude framed it better. So I took Claude’s framing.
- Two of Claude’s opportunities were solutions. I dropped these.
- There were seven opportunities on my list that Claude missed.
Okay, wow! That got me to sit up. Claude missed some important opportunities. But so did I.
And here’s what happened with the second transcript:
- I identified 19 opportunities.
- Claude identified 20 opportunities
- Claude found two opportunities that I missed.
- Several of Claude’s opportunities were duplicates of each other.
- Claude missed seven of the opportunities that I found
I won’t bore you with the results from all 15 of my transcripts. But I will share my conclusion.
Claude was an amazing thought partner when it came to helping me synthesize my interviews. It found opportunities that I missed. It helped me reframe other opportunities. I was impressed. But there is one giant caveat: Claude missed a lot of important opportunities.
My takeaway: At this point, Claude is a very helpful thought partner. Claude is not ready to replace me when it comes to synthesizing interviews.
Can Claude evaluate how well an interviewer conducted a story-based interview?
I then asked Claude and ChatGPT to evaluate how well I did as an interviewer. Again, Claude did well. ChatGPT did not.
(Quick note: These were point-in-time experiment results. These tools—and their strengths and weaknesses—are always evolving. I encourage you to run your own experiments and not just take my word for it.)
With two simple rubrics, Claude did a remarkably good job. It could identify when an interview was a story-based interview and when it was not. And it provided great feedback on both what I could have done better and what I did well.
I was hooked. This one clearly had potential. So I started refining my prompt.
But I quickly ran into a problem. All of my interview transcripts were story-based interviews conducted by me or one of my instructors. They didn’t represent the type of transcripts I would get from my students. I needed some real customer interview transcripts to test with.
Who could be a good test audience?

I didn’t want to test with my current students. I worried if the feedback wasn’t good enough, it would interfere with their learning journey. That felt too risky.
So instead, I decided to test with our recent alumni. These are folks who are familiar with story-based customer interviews—so the rubric and the feedback would make sense to them. But they also were new to the skill, so I figured we’d see a lot of variation in their transcripts.
So I asked for volunteers in our alumni community and I got plenty. That was a good sign.
Getting real customer transcripts changed everything. I discovered my simple prompt was about to fall apart.
But before we get to that, let’s do a quick recap for how to start prototyping and how to select who to test with:
- Start with the tools that you already have. Any of the web-based LLM tools are a perfectly fine place to start. Try to write a prompt that gives consistently good output.
- Try more than one model. They each excel in different areas.
- Find a small, engaged, safe user pool to test with. The key word here is “safe.” They need to opt in and know that it’s a beta. It won’t all go well at the beginning, no matter how good it looks on your test trials.
Now let’s get back to why real customer transcripts changed everything.
3. Choosing an Architecture Pattern and the Right User Experience
Before I could test with real alumni transcripts, I needed a way to deploy the Interview Coach. Remember, I was working out of a Claude Project.
You can’t share a Claude Project with someone else. Nor did I want to. I wanted to build something that I could integrate into my course platform.
It took several iterations to get the architecture right and I suspect it will continue to evolve.
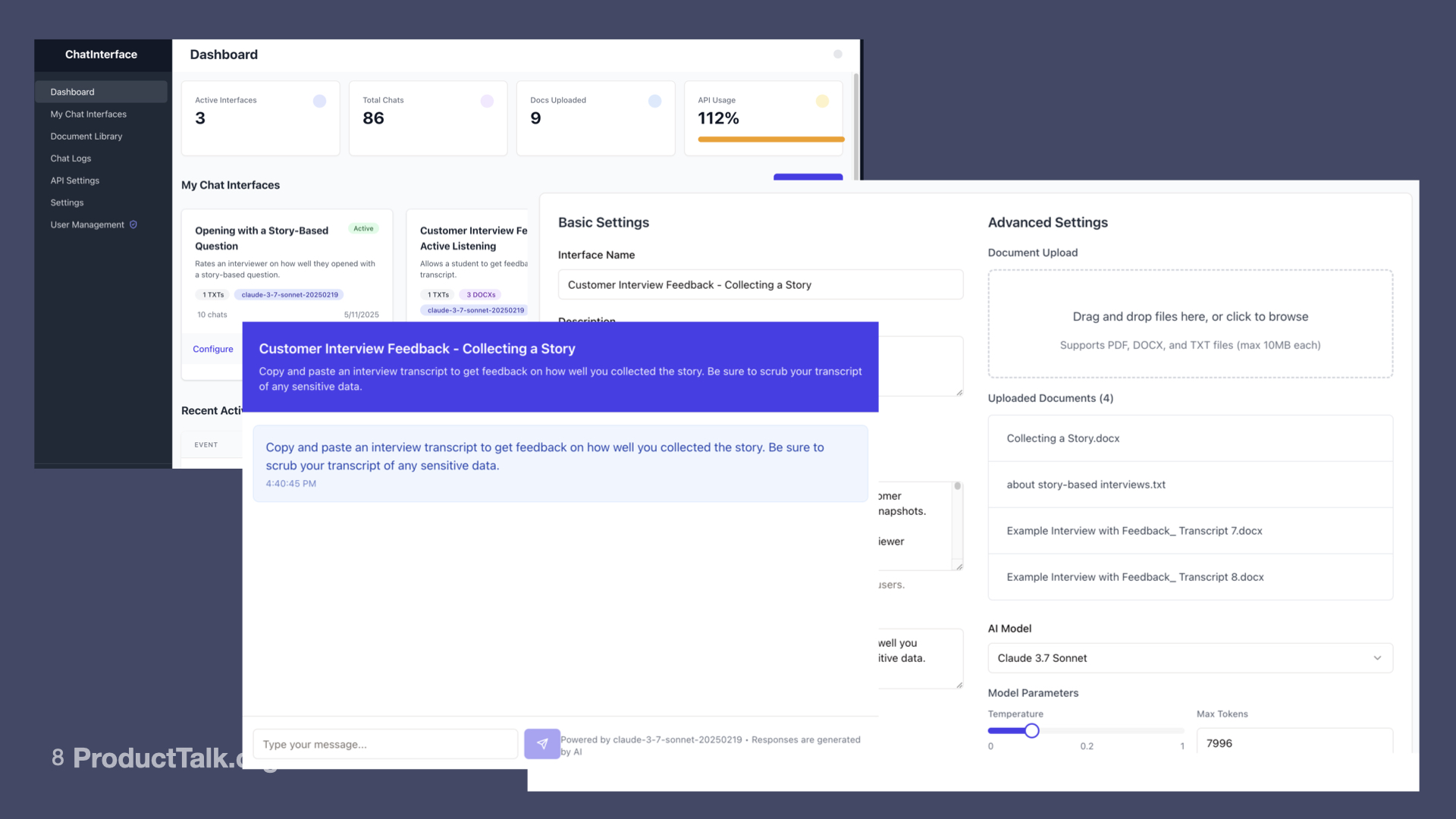
I started by building a tool in Replit that allowed me to build custom chat interfaces. I could write a prompt, upload some supporting files, and then it generated a chat interface that used that prompt and supporting files in the context window. It then let me embed that chat interface into my course platform.
What is Replit?
Replit is an AI prototyping tool that allows you to build web-based apps by describing what you want to an agent. The agent then builds the app. For more on AI Prototyping, see:
AI Prototyping: How 11 Real-World Teams are Transforming Their Work with Lovable
This was a perfectly adequate working prototype. It allowed my first few beta testers to submit their own transcripts. But I quickly encountered two problems:
First, I learned a chat interface wasn’t the right UX for the Interview Coach. People would submit their transcript for feedback, the Interview Coach would respond with its analysis, and then students would keep chatting with the Coach—asking the Coach questions about the feedback.
The Coach wasn’t built for this follow-on dialogue and it meant that students blew through their rate limits by asking questions rather than submitting additional transcripts.
Second, with real student transcripts, I started to uncover some new problems with the Coach’s response. It was evaluating the transcript on four dimensions. But it would often misapply criteria from one dimension to another dimension. In other words, I was asking the Coach to do too much in a single task.
To solve these problems, I decided to make two key changes:
- I decided to move away from a chat interface. Instead of submitting their transcripts via chat, students would submit their transcripts through a homework assignment tool that was already included as part of my course platform. They would then get their feedback via email. If they had questions or feedback on the Coach’s feedback, they could reply to the email and it would go to their instructor.
- I decided to split up my single prompt that evaluated all four dimensions into a series of prompts. Basically, I moved to an AI workflow.
What’s an AI workflow?
An AI workflow is a series of AI tasks orchestrated to accomplish a larger task. Unlike agents, workflows are deterministic—the AI tasks are always sequenced the same way.
For example, for the Interview Coach, instead of using one prompt to evaluate the four dimensions in my rubric, I changed to a workflow where each dimension was its own AI task. The workflow then aggregated the responses.
What’s an AI agent?
Unlike workflows, AI agents have more autonomy to decide which tools to use and in which order when deciding how to respond to a user’s input.
For example, if the Interview Coach was an agent, the agent could decide whether it should evaluate the transcript on all four dimensions in the rubric or if it should only run one or two based on the transcript and/or the student’s learning goals. I suspect the Interview Coach will become an agent in time.
There was just one problem. The Replit tool that I built didn’t support either of these options. So I needed a new way to deploy.
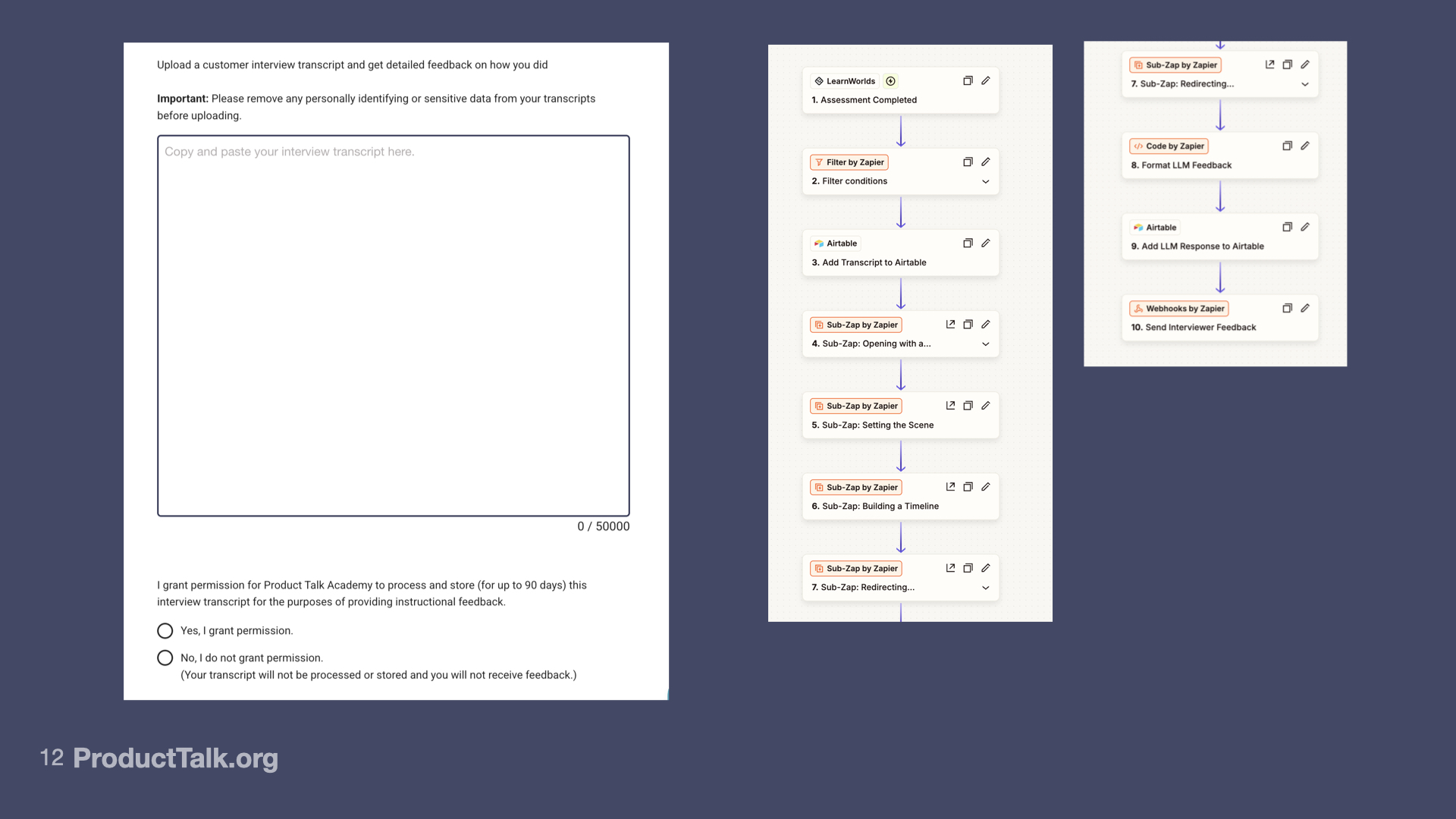
So I moved to a zap (from Zapier). When a student submitted a transcript via the homework tool in my course platform, it triggered a zap that orchestrated the four LLM calls. It aggregated the responses, constructed the email, and sent the email to the student.
What’s a zap?
A zap is a no-code automation in Zapier that is triggered by an action and then initiates one or more subsequent actions. The triggering action occurs in one application, but the subsequent actions can take place across many different applications.
For example, in the Interview Coach, my zap is triggered when a student submits their transcript in my course platform. The subsequent actions are AI tasks (using the Anthropic API), custom code that aggregates the responses across the AI tasks, and AWS SES (an email sending service).
This worked great for a little while. The primary challenge that I ran into with this setup was error handling. If something went wrong in the zap, Zapier put it on hold for up to eight hours. That left my students wondering where their feedback was.
So I rebuilt the Interview Coach again. This time I used an AWS Step Function to orchestrate the multiple LLM calls. I chose this technology because I was already using it to manage my course cohorts.
What’s an AWS Step Function?
Step Functions are AWS workflow diagrams that allow you to orchestrate serverless code. You describe the workflow in Amazon States Language—a JSON schema used to describe how you want to orchestrate the states in your diagram.
For example, the Interview Coach Step Function orchestrates four AI tasks, has a custom code task to aggregate the results, and has an AWS Simple Email Service (SES) state to send the student an email.
With this new setup, I still needed my zap to trigger when a student submitted their transcript. But instead of the LLM calls being embedded right in the zap, the zap executed my new Step Function. This was a far more reliable setup because it allowed me to move all the error handling to the Step Function. This is still the setup that I use today and it has been very reliable.
I can foresee some more architectural decisions down the road. I’d love to get to the point where the Interview Coach evaluates a transcript based on what the student has submitted in the past. To support this, I might make two changes:
- Introduce a Retrieval-Augmented Generation (RAG) step to my workflow to pull in a student’s learning history.
- Move from a workflow architecture to an agentic architecture where the Interview Coach can decide which part of the interviewing rubric to apply based on the student’s past learning journey.
What is RAG?
Retrieval-Augmented Generation (RAG) is a technique where you dynamically add related information to the user input before asking the AI to generate a response.
For example, when a student submits an interview transcript for feedback, the workflow might include a step that retrieves the student’s feedback history before submitting both to the Coach. This would allow the Interview Coach to tailor the feedback based on the student’s history.
But I’m getting a little ahead of myself. Moving from a single prompt to a workflow that included several smaller AI tasks dramatically improved the quality of the Interview Coach’s responses. But it also introduced some new problems. When I split the prompts, the Interview Coach started giving contradictory feedback across dimensions.
Before we get to that, let’s do a quick recap on architectural decisions:
- Think through the right user experience. Almost everyone is rushing to add chatbots to their products. But AI can be integrated in many forms. Don’t assume chat is where you have to start.
- Understand the differences between workflows and agents. Workflows are great when the process is deterministic (e.g. can be defined up front), even if some of the sub-tasks are AI-driven. Agents are great when the AI needs more decision-making power to respond well to the input.
- Deconstruct complex tasks into smaller tasks. LLMs are better at doing one thing at a time.
- Consider how you might add dynamic context to the conversation through RAG, local tools, or even remote tools.
- Start simple and add complexity only as you find a need for it.
- You can get really far with no-code tools. Don’t be afraid to just start.
- Expect to outgrow your tools. Each architecture choice will reveal new constraints that push you to the next level.
What are tools?
Tools extend an agent’s abilities beyond just text generation. They allow the agent to request specific actions—like executing code, calling APIs, or accessing databases—and in turn that action can return a response to the agent. When defining an agent, we can define which tools they can call.
For example, if the Interview Coach was an agent, I could equip it with the following tools:
- Student Course Lookup: Retrieve student’s course history.
- Student Transcript Lookup: Retrieve student’s transcript and coaching response history.
- Update Student Transcript History: Add the latest response to the student’s history.
I would need to implement each of these tools and make them available to the agent. The agent could then decide to look up the student’s course history and transcript history before providing feedback. It could also update the student’s transcript history whenever it gave feedback.
What is MCP?
The Model Context Protocol (MCP) is an open standard defined by Anthropic and rapidly adopted by the other LLM labs for connecting agents to tools. The standard makes it easy for agents to discover what tools are available, how to authenticate to use those tools, and how to call the tools.
If we continue with the Interview Coach example, if I launched an MCP server, my agent (the Interview Coach) could query the server and get back a list of available tools. This means my tools can be developed and augmented separately from the Interview Coach. Each time the Interview Coach connects to the MCP server, it gets the latest list of tools.
MCP can be a hard concept to understand. If you still don’t get it, stay tuned. I’ll be doing a deeper dive on MCP soon.
Okay, let’s get back to that contradictory feedback problem.
4. Getting Consistent Results Across User Inputs
When I split my prompt into multiple prompts, the Coach was much better at evaluating each dimension. It no longer confused criteria for one dimension with another dimension.
But I created a new problem. Now each dimension had no context for the other dimensions and I started to see contradictory feedback across the dimensions.
In other words, I took two steps forward and one step back. This was frustrating. I started to ask, “How do I know if my Interview Coach is any good?”
I was looking at specific transcripts and evaluating how well the Interview Coach responded. Sometimes it did a great job. Sometimes it made mistakes. I started to feel the weight of non-deterministic output. How was I going to shape this thing into something that was consistently good?
That’s when I learned about evals (short for evaluations).
What are evals?
Evals are how you evaluate if your AI product or feature is any good. They are often analogous to unit testing and integration testing for deterministic code. They give us confidence that our AI apps are doing what we expect them to do.
There are three common eval strategies:
- Creating “golden” datasets. A dataset consisting of a wide range of expected user input with the desired output clearly defined. To evaluate your product or feature, you run the inputs against the product or feature and compare the AI output to the desired output.
- Code-based assertions. A strategy where you use traditional deterministic code to evaluate the quality of the LLM response. An example of a common code-based assertion is checking to see if the LLM is returning valid JSON. This is particularly important in workflows where a subsequent step might need to parse the output.
- LLM-as-Judge evals. A strategy where you have a second LLM evaluate the output of the first LLM. I use an LLM-as-Judge to evaluate if the Interview Coach suggested any leading questions in its coaching response.
In all three cases, you want to use human graders to evaluate how well your evals performed.
When I first learned about evals, I only learned about golden datasets. I wasn’t sure how to create a dataset before my product was in the market. This felt like a chicken-and-egg problem. I didn’t feel comfortable releasing until I knew it was good. I couldn’t evaluate if it was good until I could collect more traces.
What’s a trace?
A trace is a detailed record of an AI interaction. It includes the user input, system prompts, tool calls, intermediate steps, and final LLM responses. In multi-turn conversations, it typically includes all of the back and forth between the user and the LLM.
For the Interview Coach, a trace is the system prompts, the interview transcript, and the Interview Coach’s feedback on that transcript. Later, if I add tools, the trace would also include tool calls and their results.
I know many teams use synthetic data to solve this problem, but I really struggled with generating realistic synthetic transcripts.
Thankfully, I stumbled upon the AI Evals for Engineers and PMs course on Maven and I joined the first cohort.
In that course, I learned how to build code-based and LLM-as-Judge evals based on a rigorous error analysis process that was rooted in grounded theory. As a qualitative research wonk, I was hooked.
What is grounded theory?
Grounded theory is a research method where you build theories from the ground up by looking at real data, rather than starting with a hypothesis to test. You collect data, look for patterns, and let the theory emerge from what you find.
Think of it like detective work: Instead of starting with a suspect and looking for evidence, you gather all the clues first and see what story they tell.
I started by annotating the traces that I did have. I identified my most common error categories and I set out to design code-based and LLM-as-Judge evals for each.
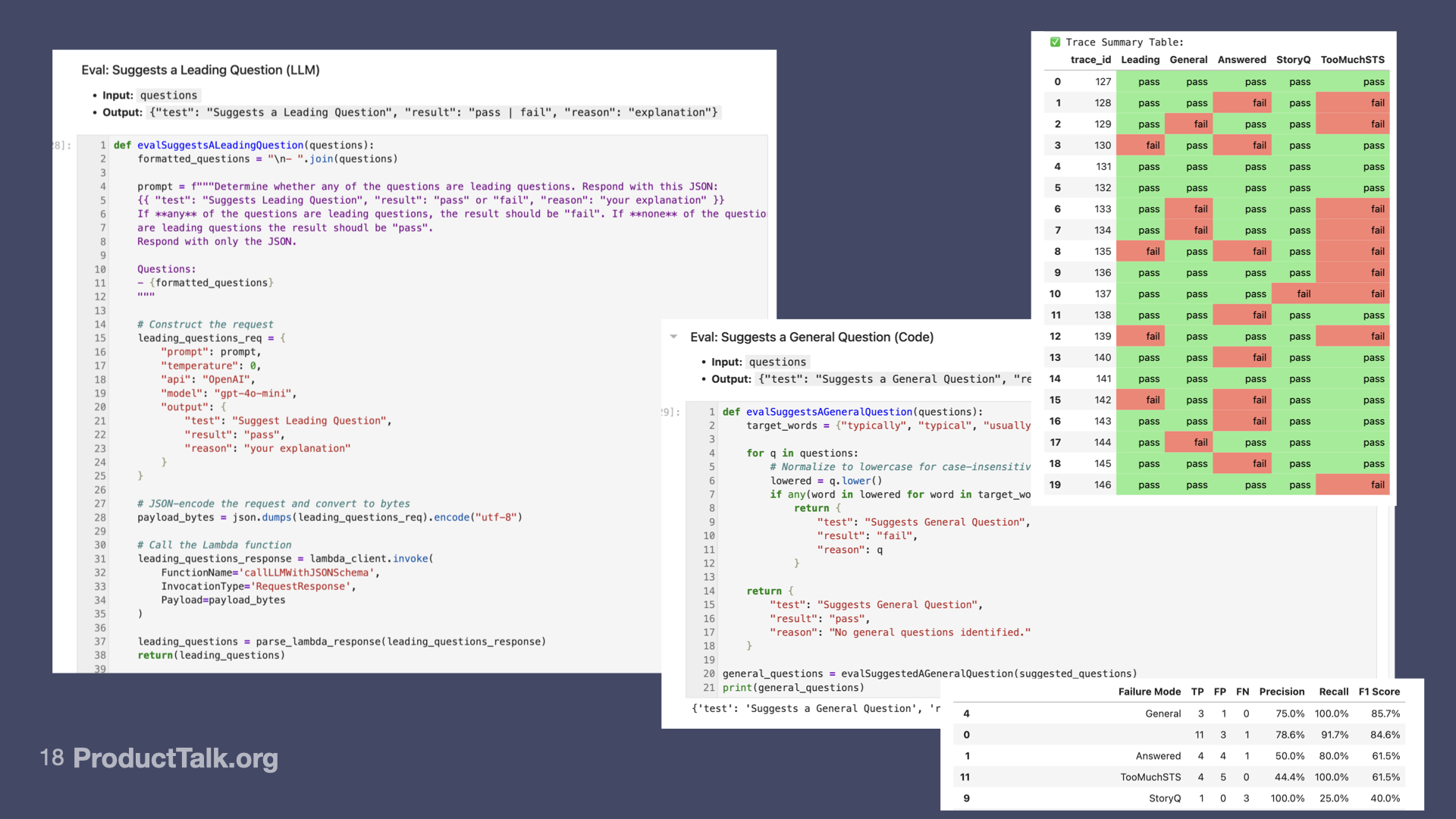
I wrote my first set of evals in a Jupyter Notebook. This allowed me to write code, test ideas, document my results, and look at my data, all in the same file. Jupyter Notebooks were new to me, but they were surprisingly easy to learn (with the help of ChatGPT) and they ended up being a perfect fit for my experiments.
As my evals grew in number and the code base grew, I moved into VS Code and used Claude Code as my guide. I now have a consistent cadence of annotating traces, updating my failure modes, choosing which ones need evals, and updating my arsenal of evals.
I also have a consistent cadence of running experiments to improve my Coach based on what I’m learning from annotating my traces and running evals.
But before we get into that, let’s do a quick recap of how we get to consistently good results:
- If you care about quality, your AI product or feature needs evals. Just like unit tests and integration tests, evals are not optional.
- Ground your evals in error analysis. Identify the most important failure modes that matter for your product and build evals for the ones that persist.
- Continuously run evals so that you can get a real-time view of how your product is performing.
- You don’t need to start with eval software. You can use the tools that you already know. Start simple. Make sure you understand the process before you let a vendor inform your perspective.
- Evals are how you know if your product is any good. If you care about quality, spend time on your evals.
I’ll be doing a deep dive on how I built my evals soon. So stay tuned for more on this very important topic.
Okay, let’s talk about experiments. This is where some of the same guiding principles from continuous discovery are going to come into play.
5. The Continuous Investment Reality
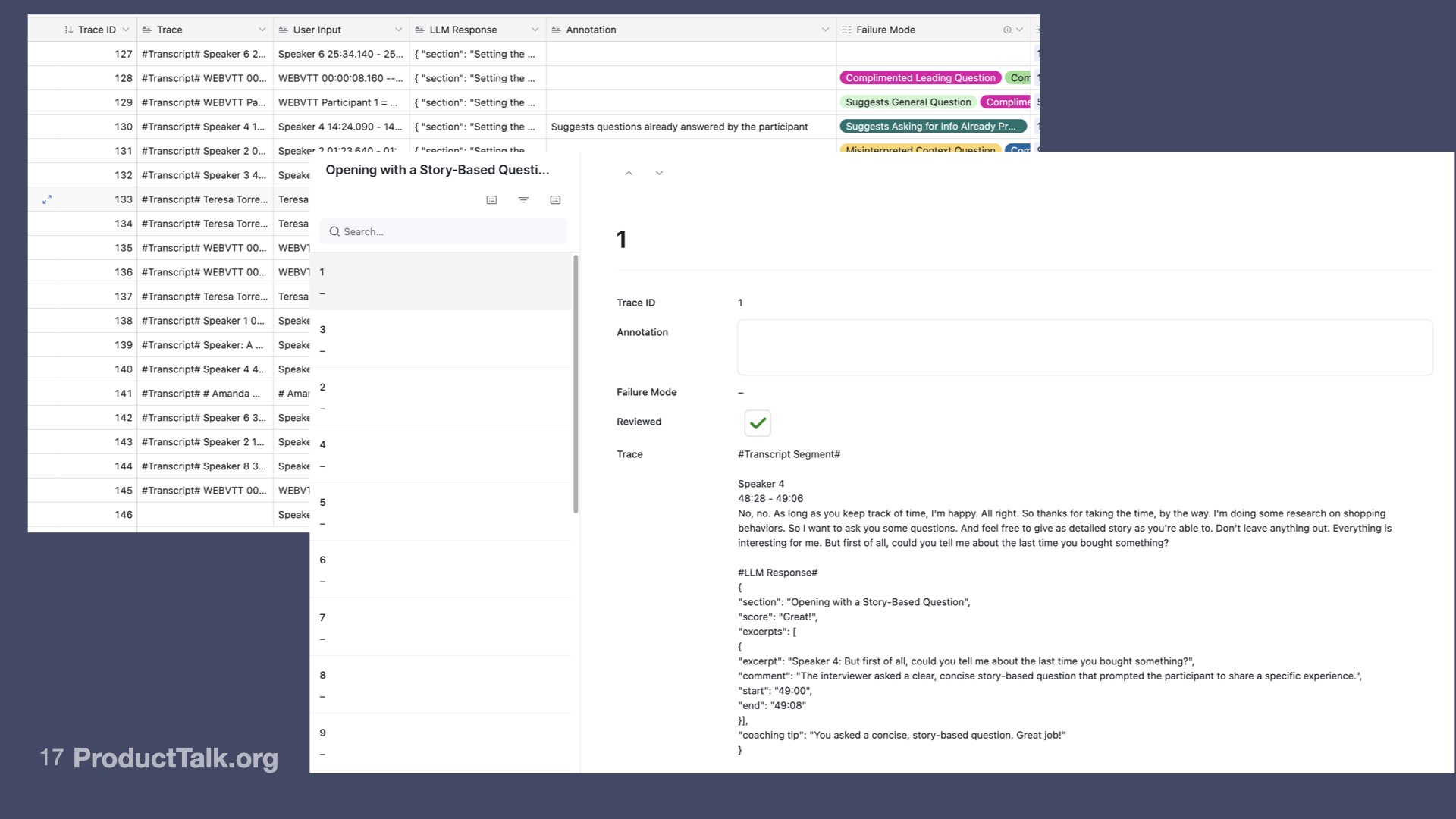
Once I had a comprehensive (and growing) set of evals, a funny thing happened. It’s a lot like when you instrument a product for the first time. You start to see all the places your product falls short. It’s an uncomfortable truth. But if you care about quality, it’s a truth you want to see.
And so with evals in place, I started to see all the warts in my Interview Coach. And that led to rapid cycles of experimentation.
I wanted to reduce the errors. So here’s what I find myself doing week over week.
- I look at ~60 full traces every week or two. I annotate the traces and I revise my failure mode taxonomy as needed.
- If there’s a new error, I decide if it needs an eval. If it does, I write it.
- I re-score my LLM-as-Judges against my new batch of human labels. I’ll dig into this more in my eval deep dive. But it basically means I’m just making sure my judges continue to work as expected.
- If I have time, I choose a more persistent error and I design an experiment to try to fix it.
It’s this last step that I’ll dig into now. And I’ll illustrate it with an example.
A few weeks ago, I identified a new error. My Interview Coach includes excerpts from the interview transcript in its feedback. The goal of the excerpts is to show the interviewer what they did well or what they could have done better. So the excerpts are always accompanied by coaching tips.
One of the side effects of splitting my prompt into several smaller prompts is often the same excerpt will be used in multiple sections of the feedback. Sometimes this is appropriate. Sometimes it leads to conflicting feedback.
I noticed the error by reviewing traces, but I wasn’t sure how pervasive it was. So I wrote a new eval to detect the error. This was a tricky one. It was my first eval that spanned multiple LLM calls and there was some ambiguity as to when it was an error and when it wasn’t. But I knew if I couldn’t detect it, I couldn’t evaluate my experiments. So I persisted. Thankfully, after a day and a half of some false starts, I finally landed on a simple code-based eval.
Next, I had to devise a solution to the problem. This also wasn’t trivial. I started on a path of classifying questions and only sending each dimension the segments of the interview that were most relevant to that dimension. But this turned out to be really hard. I was building LLM tasks on top of LLM tasks where each needed to be evaluated and judged.
I took a break. Over dinner, I was talking with my husband about what I was working on, and as I explained it to him, a much simpler solution came to mind. I was shocked at how simple it was. Instead of classifying questions, I simply keep track of which excerpts are already used and instruct the subsequent LLM steps not to use them again.
The next morning I worked with Claude Code to implement it. I set up an A/B test running a test dataset against production and against my new fix. I then ran my eval against both sets. I saw the error rate drop from 81% of transcripts to 3% of transcripts. Wow! That felt great.
This experiment took a few days to run, but it had a big impact.
I also run many small experiments. I’ve played with temperature changes, model changes, prompt changes, and even orchestration changes. And my evals allow me to determine if the changes improved things.
I now have a continuous feedback loop (exactly what we look for in product discovery). I can start with my traces, look for errors, detect those errors at scale with evals, design experiments, and evaluate if all my experiments are having an impact. When they do, I ship them.
Not bad for only being a few months into building my first AI product.
Here’s what I’ve learned along the way:
- You can’t predict at the outset how long it will take to build an AI product. Getting to good takes a lot of iteration.
- That iteration doesn’t stop even when your product is good enough.
- Annotating traces, adding new evals, and running experiments are continuous activities. I suspect the Interview Coach will never be done.
- Observability (being able to see your traces) is everything. But to do this ethically, we have to be transparent with our customers about this.
- This stuff is really fun. It’s a whole new world out there. Start playing. You won’t regret it.
Before we wrap up, I have one more lesson I want to share with you.
6. Understanding Our Data Responsibility
I’ve long been an advocate for ethical data practices. I believe users own their own data and we have an ethical responsibility to handle that data appropriately.
I had no idea what role traces played in AI development before I jumped down this rabbit hole. Most companies are not being transparent about what they are logging and who gets to see it. And for me, this raises significant ethical questions.
I ran into this unintentionally with the Interview Coach. I want to share my story so that you know to look out for these types of issues as you build out your AI products.
Here’s what happened: I built the Interview Coach for my Continuous Interviewing course. In that course, students conduct practice interviews with each other. I built the Coach to give feedback on those practice interviews. But as soon as I released the Interview Coach, students didn’t just submit their practice interviews. They also submitted their real customer interviews.
This worried me. I’m not set up to safely store real customer interviews. Some of these transcripts included sensitive customer data. I thought I was releasing a prototype that would be used in a very specific context—practice interviews from class. I was wrong. I had to pull back the Interview Coach until I investigated further.
I started to look into what it would take to give feedback on real customer interviews. I looked into the process and requirements for SOC 2 compliance. I looked into tools to scrub personally identifiable information (PII). And I got overwhelmed pretty quickly.
I decided this was not something that I (a company of one) could manage. So instead, I re-released the Interview Coach. But this time, I did several things differently.
- On the splash page (not buried in the Terms of Service), before students can submit their transcripts, I explain that this tool was designed for their practice interviews only. They are instructed to not submit any transcripts with proprietary customer data or sensitive PII.
- On the screen where they submit their transcript, they have to check a box that says, “I grant permission to store this transcript for up to 90 days for the purposes of improving the Interview Coach.” If they don’t check the box, we don’t process their transcript.
- I implemented a system that deletes traces that are 90 days old.
That helped. But I still wanted to give students feedback on their real customer interviews. Fortunately, around this time I became an advisor to Vistaly—a product discovery tool that allows you to build opportunity solution trees, track customer interviews, and much more.
We started talking about integrating the Interview Coach into Vistaly. Vistaly is SOC 2 compliant. They already store customer transcripts. They already solved all the data processing challenges I didn’t want to do. It was a perfect match for me.
We are currently in beta. But if you are a Vistaly customer and you want to get access to the Interview Coach, reach out. I’m very excited about this partnership. My little prototype has grown up into a full-fledged production product.
Before we wrap, let’s do our final recap. With AI products:
- Assume users will use your tool in unexpected ways.
- Be transparent about data collection upfront, not buried in your Terms of Service.
- Consider partnering rather than building compliance infrastructure.
- Delete what you don’t need—traces aren’t forever.
I am amazed at how this story has unfolded. I’ve learned more than I ever thought I could. And I have many more AI teaching tools in the works.
I know many of you are also working on AI products or are thinking about AI products. How can I help? What do you want to learn more about? If you are reading this in your inbox, reply and let me know. Otherwise, reach out on LinkedIn or X. I’d love to hear from you.
The post Building My First AI Product: 6 Lessons from My 90-Day Deep Dive appeared first on Product Talk.
Building My First AI Product: 6 Lessons from My 90-Day Deep Dive was first posted on August 20, 2025 at 6:00 am.
© 2024 Product Talk. Use of this feed is for personal, non-commercial use only. If you are reading this article anywhere other than your RSS feed reader or your email inbox, then this site is guilty of copyright infringement. Please let us know at support@producttalk.org.