Problems
The inability of visually impaired individual access image information due to the lack of adherence to W3C web accessibility initiatives by websites. Currently, about 60% of websites lack meaningful alternate text for their images. Moreover, it is unfeasible to retroactively add descriptive text to all existing websites manually.
To address the issue, we created the GeProVis AI Screen Reader last year. This solution garnered significant positive feedback from the visually impaired community and earned our team several accolades, including being named one of the top 100 candidate projects in the Google Developer Student Clubs (GDSC) 2024 Solution Challenge.
However, the solution has received several pieces of feedback:
- Web Security: The server-side approval cannot read images after logging into the website, and JavaScript cannot send images to the server due to CORS issues.
- Privacy Concerns: Users feel unsafe sending web images to an unknown location.
- Cost: Someone must cover the expenses for Google Cloud Vertex AI Gemini.
- Deployment and Maintenance: Visually impaired users or NGOs find it challenging to handle.
- Limitations of Previous Generation Screen Readers: These rely on keyboard shortcuts to control the cursor and use text-to-speech for HTML element content. Users must navigate the web page iteratively to get answers or information.
Feedback
Hong Kong Media interview AI智慧應用|短片:AI工具助視障者瀏覽網頁圖片圖表可讀出聲https://news.mingpao.com/ins/%e7%86%b1%e9%bb%9e/article/20241016/s00024/1728626161042
https://medium.com/media/42b3a53815d0a76ce9933a27c0e5c00a/href
The interviewee Mr. Chow (Assistant Project Director, Hong Kong Blind Union — Digital Technology) highlights the core issues faced by visually impaired users with current screen readers. They constantly need to use shortcuts to navigate the web, listen to text-to-speech outputs, remember all the information, and guess their next steps to find the answers they seek. While the GeProVis AI screen reader now allows them to extract information from all images even if websites lack meaningful alternate text for their images, it still doesn’t provide a complete solution. These users are searching for answers or information, and traditional approaches fall short in meeting their needs.
New Solution & New Approach

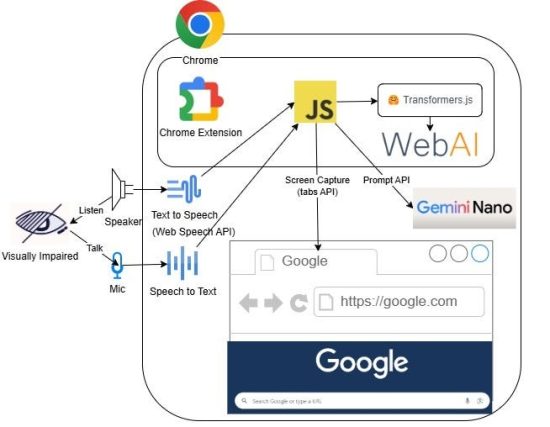
A-Eye Web Chat Assistant
We’ve developed a brand-new, 100% client-side Chrome extension that leverages the capabilities of Web AI (both by using built in AI capabilities in Chrome such as Gemini Nano, and by using our own models such as Moondream running within the webpage itself accelerated via WebGPU) to enable visually impaired or handicapped users to chat on the web. Features:
- Privacy-First: Ensures all processing is done locally on your device, safeguarding your data with built in AI on Chrome and Web AI.
- Comprehensive Content Chat: Offers detailed interpretations of web pages and image descriptions using Chrome’s built-in prompt API.
- Real-Time Image Descriptions: Provides real-time descriptions of images through Web AI and transformers.js.
- Voice Interaction: Allows users to control the screen reader with voice commands using the Web Speech API.
- Speech Synthesis: Reads out responses using advanced speech synthesis technology via the Web Speech API.
- Conversation Management: Keeps track of conversation history and state for seamless interactions.
- Dual AI Models: Utilizes both Gemini Nano and Moondream2 for superior accuracy.
- Cross-Platform Compatibility: Available on Windows, macOS, ChromeOS and Linux.
- Chrome Extension: Easily accessible as a Chrome extension.
Demo
https://medium.com/media/048db2ea3b96ab065b85a94e0f2f821a/href
How does it work?
Architecture
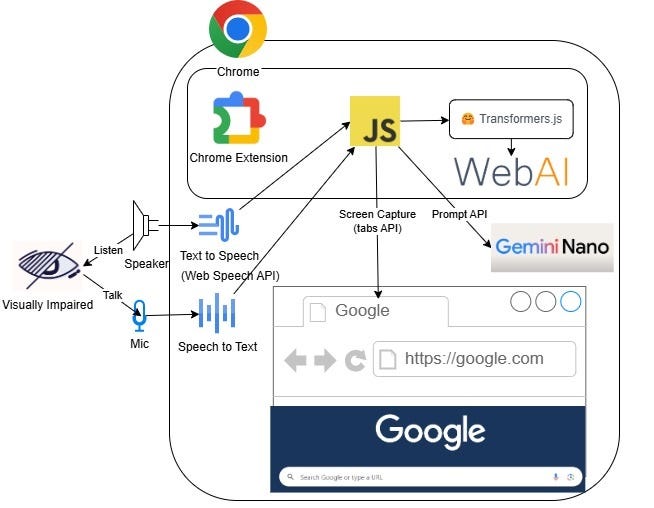
High Level Sequence Diagram

Background Script
A service worker is a background script that acts as the extension’s main event handler.
const SYSTEM_PROMPT = `You are a clear and concise web content summarizer. Your task is to present the core message in simple, plain text format suitable for text-to-speech.`;
const ERROR_MESSAGES = {
GEMINI_UNAVAILABLE: "Gemini Nano is not available.",
NO_RESPONSE: "No response from Gemini",
SESSION_FAILED: "Failed to create Gemini session"
};
chrome.sidePanel.setPanelBehavior({ openPanelOnActionClick: true });
let currentGeminiSession = null;
chrome.commands.onCommand.addListener((command) => {
console.log('Command received:', command);
if (command === 'toggle-voice-control') {
chrome.runtime.sendMessage({
type: 'toggleVoiceControl'
});
}
if (command === 'toggle-voice-input') {
chrome.runtime.sendMessage({
type: 'toggleVoiceInput'
});
}
});
chrome.runtime.onMessage.addListener((request, sender, sendResponse) => {
const handlers = {
'initGemini': () => initializeGemini(sendResponse),
'analyze': () => initializeAndAnalyze(request.text, sendResponse),
'chat': () => handleChat(request.text, sendResponse),
'startRollingScreenshot': async () => {
try {
const [tab] = await chrome.tabs.query({ active: true, currentWindow: true });
const results = await chrome.scripting.executeScript({
target: { tabId: tab.id },
function: () => ({
scrollHeight: document.documentElement.scrollHeight,
clientHeight: document.documentElement.clientHeight,
scrollWidth: document.documentElement.scrollWidth,
clientWidth: document.documentElement.clientWidth
})
});
sendResponse(results[0].result);
} catch (error) {
console.error('Failed to get page dimensions:', error);
sendResponse(null);
}
return true;
}
};
if (handlers[request.type]) {
handlers[request.type]();
return true;
}
});
async function createGeminiSession() {
try {
const capabilities = await ai.languageModel.capabilities();
if (capabilities.available === "no") {
throw new Error(ERROR_MESSAGES.GEMINI_UNAVAILABLE);
}
const session = await ai.languageModel.create({
systemPrompt: SYSTEM_PROMPT
});
if (!session) {
throw new Error(ERROR_MESSAGES.SESSION_FAILED);
}
return { success: true, session };
} catch (error) {
console.error('Gemini Session Creation Error:', error);
return { success: false, error: error.message };
}
}
async function ensureGeminiSession() {
if (!currentGeminiSession) {
const { success, session, error } = await createGeminiSession();
if (!success) {
return false;
}
currentGeminiSession = session;
}
return true;
}
function handleGeminiResponse(result, sendResponse) {
if (!result) {
sendResponse({ error: ERROR_MESSAGES.NO_RESPONSE });
return;
}
sendResponse({ content: result });
}
async function initializeGemini(sendResponse) {
try {
const { success, error } = await createGeminiSession();
sendResponse({ success, error });
} catch (error) {
console.error('Initialize Error:', error);
sendResponse({ error: error.toString() });
}
}
async function initializeAndAnalyze(text, sendResponse) {
try {
if (!await ensureGeminiSession()) {
sendResponse({ error: ERROR_MESSAGES.GEMINI_UNAVAILABLE });
return;
}
const prompt = `Summarize this web page about 300 words. Web Page Content:
"${text}"`;
const result = await currentGeminiSession.prompt(prompt);
handleGeminiResponse(result, sendResponse);
} catch (error) {
console.error('Analysis Error:', error);
sendResponse({ error: error.toString() });
}
}
async function handleChat(text, sendResponse) {
try {
if (!await ensureGeminiSession()) {
sendResponse({ error: ERROR_MESSAGES.GEMINI_UNAVAILABLE });
return;
}
const result = await currentGeminiSession.prompt(text);
handleGeminiResponse(result, sendResponse);
} catch (error) {
console.error('Chat Error:', error);
sendResponse({ error: error.toString() });
}
}
Logic
Please check out our GitHub repository for the source code.
Voice Interaction
- handleResponse(response): Handles responses and speaks text.
- speakText(response): Uses speech synthesis to read out responses.
- handleClear(): Clears the conversation and stops speech synthesis if active.

speakText(text) {
if (!this.state.voice.synthesis.instance) return;
if (this.state.voice.synthesis.isSpeaking) {
this.state.voice.synthesis.instance.cancel();
}
const utterance = new SpeechSynthesisUtterance(text);
utterance.voice = this.state.voice.synthesis.selectedVoice;
utterance.lang = 'en-US';
utterance.rate = 1.5;
utterance.pitch = 1.0;
utterance.volume = 1.0;
this.state.voice.synthesis.isSpeaking = true;
utterance.onend = () => this.state.voice.synthesis.isSpeaking = false;
this.state.voice.synthesis.instance.speak(utterance);
}
async handleSendMessage() {
const input = this.elements.userInput.value.trim();
if (!input || this.state.isProcessing) return;
this.state.isProcessing = true;
this.disableInterface();
try {
this.appendMessage('user', input);
if (this.state.currentModel === 'moondream') {
await this.generateMoondreamResponse(input);
} else if (this.state.currentModel === 'gemini') {
const response = await chrome.runtime.sendMessage({
type: 'chat',
text: input
});
this.handleResponse(response.content);
} else {
throw new Error('Please select a model first');
}
this.elements.userInput.value = '';
} catch (error) {
this.handleError('Error sending message', error);
} finally {
this.state.isProcessing = false;
this.enableInterface();
}
}
Content Analysis
- _postProcessContent(articleContent): Processes article content, fixes relative URIs, simplifies nested elements, and cleans classes.
- _removeNodes(nodeList, filterFn): Removes nodes from a NodeList based on a filter function.
- _replaceNodeTags(nodeList, newTagName): Replaces tags of nodes in a NodeList.

Image Descriptions
Uses AI models like Moondream1ForConditionalGeneration and RawImage from Transformers.js 3.0 for image processing and description.

A screenshot captures the visual part of the webpage description, while a rolling screenshot covers the entire webpage description.
async handleScreenshot() {
if (this.state.isProcessing) return;
try {
this.elements.screenshotButton.disabled = true;
this.speakText("Analyzing Screenshot");
this.appendMessage('system', 'Analyzing Screenshot.');
this.updateModel('moondream');
const screenshot = await chrome.tabs.captureVisibleTab();
this.showPreview('image', screenshot);
await this.handleImageAnalysis(screenshot);
} catch (error) {
this.handleError('Error taking screenshot', error);
} finally {
this.elements.screenshotButton.disabled = false;
}
}
async handleRollingScreenshot() {
if (this.state.isProcessing) return;
try {
this.elements.rollingScreenshotButton.disabled = true;
this.state.rollingScreenshotImages = [];
this.speakText("Analyzing scrolling screenshot.");
this.appendMessage('system', 'Analyzing scrolling screenshot.');
this.updateModel('moondream');
const [tab] = await chrome.tabs.query({ active: true, currentWindow: true });
if (!tab) throw new Error('No active tab found');
const pageInfo = await this.getPageInfo();
if (!this.validatePageInfo(pageInfo)) {
throw new Error('Invalid page dimensions');
}
await this.captureScreenshots(tab, pageInfo);
const mergedImage = await this.mergeScreenshots(this.state.rollingScreenshotImages);
this.showPreview('image', mergedImage);
await this.handleImageAnalysis(mergedImage);
} catch (error) {
this.handleError('Rolling screenshot failed', error);
} finally {
this.elements.rollingScreenshotButton.disabled = false;
}
}
async captureScreenshots(tab, pageInfo) {
const { scrollHeight, clientHeight } = pageInfo;
let currentScroll = 0;
await this.executeScroll(tab, 0);
while (currentScroll < scrollHeight) {
try {
const screenshot = await chrome.tabs.captureVisibleTab(null, { format: 'png' });
this.state.rollingScreenshotImages.push(screenshot);
} catch (error) {
if (error.message.includes('MAX_CAPTURE_VISIBLE_TAB_CALLS_PER_SECOND')) {
console.warn('Rate limit exceeded. Waiting before retrying...');
await new Promise(resolve => setTimeout(resolve, 1000));
continue;
} else {
throw error;
}
}
currentScroll += clientHeight;
await this.executeScroll(tab, currentScroll);
await new Promise(resolve => setTimeout(resolve, 600));
}
await this.executeScroll(tab, 0);
}
async executeScroll(tab, scrollPosition) {
await chrome.scripting.executeScript({
target: { tabId: tab.id },
function: (scroll) => window.scrollTo({ top: scroll, behavior: 'instant' }),
args: [scrollPosition]
});
}
async mergeScreenshots(screenshots) {
const canvas = document.createElement('canvas');
const ctx = canvas.getContext('2d');
const firstImage = await this.loadImage(screenshots[0]);
canvas.width = firstImage.width;
canvas.height = firstImage.height * screenshots.length;
for (let i = 0; i < screenshots.length; i++) {
const image = await this.loadImage(screenshots[i]);
ctx.drawImage(image, 0, i * firstImage.height);
}
return canvas.toDataURL('image/png');
}
async initializeModel() {
try {
const modelId = 'Xenova/moondream2';
const modelConfig = {
dtype: {
embed_tokens: 'fp16',
vision_encoder: 'fp16',
decoder_model_merged: 'q4',
},
device: 'webgpu',
};
[
this.state.tokenizer,
this.state.processor,
this.state.model
] = await Promise.all([
AutoTokenizer.from_pretrained(modelId),
AutoProcessor.from_pretrained(modelId),
Moondream1ForConditionalGeneration.from_pretrained(modelId, modelConfig)
]);
this.state.isInitialized = true;
this.elements.screenshotButton.disabled = false;
} catch (error) {
this.handleError('Error initializing model', error);
}
}
async handleImageAnalysis(imageUrl) {
if (!this.state.isInitialized || this.state.isProcessing) {
this.handleError('Model not ready', new Error('Please wait for model initialization'));
return;
}
this.state.isProcessing = true;
try {
this.state.messages = [];
const defaultPrompt = 'Describe the picture in about 100 words';
const response = await this.generateImageResponse(imageUrl, defaultPrompt);
this.handleResponse(response);
} catch (error) {
this.handleError('Error analyzing screenshot', error);
} finally {
this.state.isProcessing = false;
}
}
Further Development
We are eagerly anticipating the integration of PaliGemma support in Chrome. This update will empower visually impaired users to have more effective and powerful conversations through web-captured images.
Additionally, we hope this project will be integrated into Chrome by default, rather than as a browser extension. This would allow everyone to ‘Chat on any web with voice control,’ which would be highly beneficial for the visually impaired, elderly, and handicapped.
Non-English language support is available through the Translate API. During the Beta period, we successfully created a version that supported Hong Kong Cantonese for a time. However, it is currently not functioning. In the future, this extension will support multiple languages.
We are seeking an experienced developer to assist with a full refactoring of our extension. My students, who are majoring in Cloud, are not very strong in coding. To continue the development, we need guidance from seasoned developers or even a Googler. I am proud of Vincent for building it from scratch to a functional state despite having no prior knowledge! Please don’t criticize our coding skills and hire Vincent if you’re looking for a developer who brings passion to their work!
If you’re in Hong Kong, don’t miss his talk at DevFest Hong Kong 2024, hosted by the Google Developer Group Hong Kong!

GitHub Repo
https://github.com/vincentwun/A-Eye-Web-Chat-Assistant
Conclusion
The A-Eye Web Chat Assistant represents a significant advancement in web accessibility for visually impaired individuals. By leveraging cutting-edge Web AI both browser native APIs and by bringing our own models within a Chrome extension, it addresses the limitations of previous solutions and offers a comprehensive, privacy-first, and real-time approach to image and content analysis. This innovative tool not only enhances browsing experience but also empowers users with seamless voice interaction and superior accuracy through dual AI models. With its cross-platform compatibility and ease of use, the A-Eye Web Chat Assistant is poised to make a meaningful impact on the lives of visually impaired users, ensuring they can navigate the web with greater independence and confidence.
Thank you to the project contributors, Vincent Wun and Li Yuen Yuen, from the IT114115 Higher Diploma in Cloud and Data Centre Administration at Hong Kong Institute of Information Technology (HKIIT) at IVE (Lee Wai Lee). They are also core members of GDG on Campus at the Hong Kong Institute of Information Technology.

We also want to extend our gratitude to Jason Mayes, Web AI Lead at Google, for helping us review this tech blog. Since Web AI is a new field for us, we initially thought “WebAI” was a single word. However, it turns out it should be “Web AI,” with the former being used only as a hashtag.
About the Author
Cyrus Wong is the senior lecturer of Hong Kong Institute of Information Technology and he focuses on teaching public Cloud technologies. A passionate advocate for cloud tech adoption in media and events — AWS Machine Learning Hero, Microsoft MVP — Azure, and Google Developer Expert — Google Cloud Platform & AL/ML (GenAI).

![]()
A-Eye Web Chat Assistant: Voice and Vision Web AI Chrome Extension for Inclusive Browsing was originally published in Google Developer Experts on Medium, where people are continuing the conversation by highlighting and responding to this story.




