- NLP in Insurance Fraud Detection
- How NLP Detects Fraud?
- How Insurance Companies Detect Frauds Using NLP?
- 5 Benefits of NLP in Insurance Fraud Detection
- How Can Tx help with NLP Implementation?
- Summary
Insurance fraud is one of the biggest scams in the BFSI industry and poses a significant threat to policyholders and insurers. According to an estimate related to fraud, it costs around $300 billion in damage annually for Americans, which equals approximately $1000 per person in the country. This extremely strains industry profitability, dries up premiums for honest clients/customers and makes everyone a victim. This is why companies have started to leverage natural language processing (NLP) in insurance fraud detection and prevention.
Insurance fraud includes deceptive practices that exploit policies for financial profit. These practices include staging accidents, filling in misleading information during application, or false claims. NLP helps identify and remediate such fraudulent activities to maintain financial stability and service integrity.
NLP in Insurance Fraud Detection

According to McKinsey’s report, by 2030, AI integration will improve insurance processes’ productivity and reduce operational costs by 40%. Natural language processing, or NLP, a subset of artificial intelligence (AI), enables insurers to analyze and decode massive text data of insurance claims, customer communications, and policy documents. This allows insurers to uncover patterns, loopholes that could lead to potential fraud, and anomalies overlooked during the traditional/manual detection process.
NLP techniques can quickly analyze unstructured text data to uncover patterns and inconsistencies indicating fraudulent behavior. It leverages techniques like named entity recognition, semantic analysis, and sentiment analysis, which are very useful for extracting relevant data from text-based documents. With early fraud detection capabilities, insurers can prevent significant losses for themselves and policyholders. Additionally, the OCR (optical character recognition) feature automates the data extraction process from scanned documents, thus reducing errors and minimizing manual mistakes.
Also, as NLP has advanced steadily in recent years, it will become cheaper to develop and easily transferable within an organization. Insurance employees spend a lot of time analyzing and classifying data, so investing in NLP solutions will save them several hours. They can utilize that time in other productive areas, improving their and the organization’s efficiency.
An Example of NLP Usage in Fraud Detection
To understand how NLP works in insurance fraud detection, let’s consider a scenario:
Maria filed for a medical insurance claim for hospitalization fees due to her knee surgery on May 10, 2024, at a XYZ hospital. She claims that she suffered a severe knee injury following an accident at a park, due to which she needed knee surgery.
In her claim, Maria now provides all the necessary documents, such as a hospital discharge summary, medical bills, doctor’s reports, and medicine bills. According to documents, the injury occurred due to a fall while jogging in the park, causing a ligament tear to her knee, which needed immediate surgery. There were also some images of her knee in the cast and the medical prescriptions to strengthen her claim. But there’s a twist. All the details provided by Maria were fake, even the photos.
But how will NLP and the insurer know that? Let’s find out!
How NLP Detects Fraud?
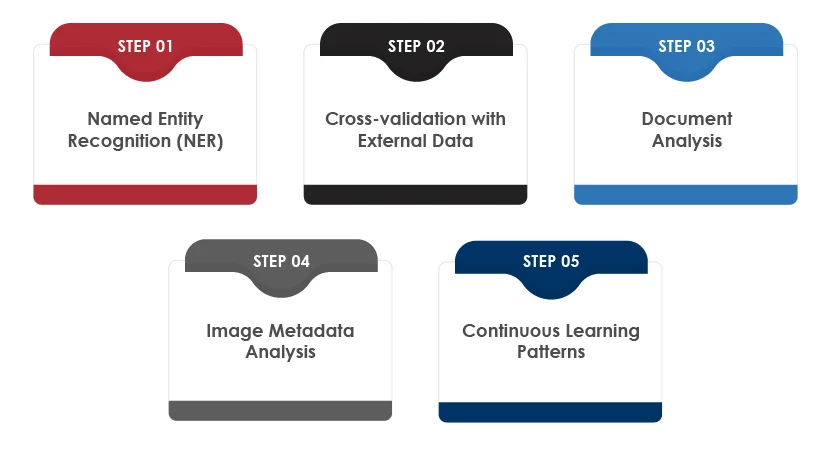
Step-1 Named Entity Recognition (NER):
NLP will identify and extract entities from the claim. In this case, it will include the following:
- Surgery date: May 10, 2024
- Hospital name: XYZ Hospital
- Doctor’s name
Step-2 Cross-validation with External Data:
NLP will analyze public healthcare databases or hospital records to cross-check the claim’s details. In this case, it will flag Maria’s claim because, according to hospital records, no surgery was performed on her knee on May 10 at XYZ Hospital.
Step-3 Document Analysis:
NLP will analyze the medical documents submitted by Maria to compare the language style of the discharge summary with other genuine summaries. It will identify inconsistencies like the phrasing and terminology used by Maria in her documents, as they do not match the standard format used by doctors at XYZ hospital.
Step-4 Image Metadata Analysis:
NLP-powered systems can extract metadata from the injury and cast images attached by Maria. After analyzing those images, the NLP system found that the images were taken months before the claimed accident date, highlighting potential fraud.
Step-5 Continuous Learning Patterns:
Continuously trained NLP systems, leveraging past fraudulent data, recognized that Maria’s case matches a common fraud pattern in which patients falsify accident dates and seek reimbursement for non-insured medical expenses.
This example defines how NLP leverages multiple techniques to detect fraudulent claims. Insurance companies can prevent false claims by combining external data sources and advanced analytics.
How Insurance Companies Detect Frauds Using NLP?

Insurance companies can leverage NLP-based scale and rating criteria to classify potential claim frauds. Let’s take a look at how it usually plays out:
Fraud Identification:
NLP analyzes textual data within claims of medical reports, witness statements, service billing, or adjuster notes. Insurers can spot phrases, patterns, keywords, and inconsistencies indicating fraud alerts. Behavioral pattern analysis in claims data includes noticing frequent changes of address, inconsistent incident description, or filing multiple claims within a short period.
Fraud Prioritization:
Insurers assign priority to frauds based on the credibility of the indicators identified. Priority scores are assigned numerically, indicating the seriousness of the fraudulent claim.
Threshold Value:
NLP allows insurers to set a threshold value for fraud prioritization score. When a claim exceeds that value, the special investigations unit (SIU) forwards that claim for further investigation. For this purpose, insurance companies use terms like High Suspicion, Moderate Suspicion, and Low Suspicion.
Fraud Investigation:
Investigators start their investigation with high-priority claims by leveraging insights from the fraud detection system. They also use their expertise, analytical methods, and evidence to confirm/deny fraud claims.
5 Benefits of NLP in Insurance Fraud Detection

Natural language processing in insurance fraud detection helps evaluate risk and make informed decisions. Companies can quickly analyze many policy documents, customer communications, and insurance applications. Additionally, leveraging NLP in insurance processes would offer the following benefits:
Accuracy Optimization:
Insurance companies can use NLP algorithms to analyze textual data with high accuracy. This would reduce false positives and negatives during fraud detection compared to traditional methods.
Claim Analysis Automation:
Businesses automate claim processing based on their risk or suspicion level by leveraging NLP-powered systems. These systems will analyze claim descriptions and relevant documents to assign claims with priority levels, allowing investigators to prioritize high-risk cases first.
Cost Effectiveness:
By automating fraud detection with NLP, insurers can streamline operations, optimize resource allocation, and reduce manual workload. This would result in long-term cost savings.
Real-time Alerts and Monitoring:
Insurers can continuously monitor their data streams in real time by leveraging NLP techniques for anomaly detection and text analysis. They can identify suspicious behaviors in the claim documents and trigger automated alerts to notify fraud prevention measures.
Data Extraction Automation:
Insurers can extract relevant details from unstructured data sources such as emails, customer communication, claim forms, etc. Unlike traditional methods, NLP models can quickly parse and extract key entities (descriptions, names, amounts, and dates), saving time and resources.
How Can Tx help with NLP Implementation?
The insurance industry must be digitally adept at understanding NLP guidance and what it can and can’t be used for. As NLP software relies on personal data, it must protect its clients’/customers’ data from unauthorized usage. This is why one must partner with a reliable insurance testing expert to ensure the proper implementation of NLP in insurance fraud detection. As a leading digital assurance and quality engineering service provider, Tx leverages next-gen QA tools and in-house AI-based accelerators Tx-Automate and Tx-SmarTest to deliver robust and scalable NLP-powered insurance solutions. At Tx, we focus on evolving insurance market trends across agile and DevOps projects, providing high-quality solutions, and ensuring regulatory compliance. Partnering with Tx will give you the following business benefits:
- 40% QA cost savings
- 90% reduction in man-hours
- 30% faster time-to-market
- 40% improved operational efficiency
Summary
Natural Language Processing (NLP) plays a crucial role in insurance fraud detection by analyzing unstructured text data and identifying fraudulent patterns. It helps insurers detect anomalies in claim submissions through techniques like named entity recognition and sentiment analysis, ensuring faster, more accurate fraud prevention.
By leveraging NLP solutions, insurers can automate data extraction and claim analysis, reducing manual effort and operational costs. Additionally, it enables real-time monitoring and alerts, allowing insurers to take timely action. By partnering with a digital assurance expert like Tx, insurance companies can implement scalable, NLP-powered fraud detection systems, enhancing efficiency, compliance, and cost savings. To know how Tx can help, contact our experts now.
The post The Role of NLP in Insurance Fraud Detection and Prevention first appeared on TestingXperts.


