
I always write articles on Medium to share knowledge. But sometimes, writing helps me also to structure knowledge and learn more about the subject. It’s been 2.5 years since I started studying cybersecurity. I started completing the Google Cloud Security Engineer track, at Google Cloud Skills Boost. Then I took some pentesting and malware analysis courses at TCM Security, Udemy, Pluralsight and TryHackMe. Pentesting, or penetration testing is a technique where an allowed attacker tries to invade the network/computers in a company. This is a red team exercise. When an attacker is not allowed to invade the systems of a company, he/she is a malicious actor, a hacker. The team who is responsible for detecting the invasion and defending the company in a pentest is called blue team.
This area is so interesting andI recently completed the Google Cybersecurity Professional Certificate and then I got my Security + certification from CompTIA. As an ML Engineer, my idea was to apply this security knowledge to the Machine Learning and Deep Learning area.
We are exposed to malicious actors all the time. Malicious links are sent via SMS (Smishing) daily, we receive malicious emails with suspicious links (Phishing), bad actors try to fool us and steal our data (Social Engineering), and companies are even more exposed to these threats and also ransomware. In the ML area, there was a recent flood of contaminated libraries in PyPi that created vulnerabilities and stole credentials when installed and we know it’s possible to inject a remote code execution in pickle files.
As Data Scientists, we frequently develop solutions that interact with the clients via app. Consider a chatbot, for instance, or a Web Application that receives client data and returns a prediction. These public facing endpoints have muck more risk (likelihood times impact) and we should take special care to protect not only the interface from being hijacked, but also other services used in the solution, like databases, containers and APIs.
OWASP, the Open Web Application Security Project is a non-profit organization that works to improve the security of software. It is an open community dedicated to enabling organizations to conceive, develop, acquire, operate, and maintain applications that can be trusted.
OWASP has a number of projects and resources that help organizations improve their application security. One of them is the OWASP Top 10, a list of the most critical Web Application security risks. The whole list can be found here. In order for you to understand and get familiarized with what is the OWASP Top 10 for Web App, I will list some of them:
- Broken Access Control: is the risk that exists when an unknown user can access areas beyond their scope of authorization.
- Cryptographic failure: is the existence of unencrypted data, like user data, or PII (Personal Identifiable Information), like user name, surname and email, that once leaked, can be easily used.
- Injection: a common type of injection is SQL Injection. Suppose the database has a query like this to authenticate the user:
String query = "SELECT * FROM accounts WHERE customerID='" + request.getParameter("id") + "'";
In this case, you can add test’ OR ‘A’ = ‘A’; and sometimes bypass the authentication, see registries or even delete tables. This happens because there is no validation or sanitization of input. See my other article to see ways to overcome this risk in a Web App.
- Insecure Design: in this case, the app either has no security controls or contains misconfigurations that make it vulnerable.
- Vulnerable/Outdated Components: as you will see, this can also happen in LLMs, when you use unsafe plugins. Here, the libraries used to develop the app are themselves vulnerable, malicious, or deprecated.
- Identification and Authentication Failure: it’s a weakness that allows, for instance, a hacker with a list of leaked credentials from the dark web, authenticate as if it was you (credential stuffing). Another example is the use of default credentials in an Apache server.
- Security Logging and Monitoring Failures: as Machine Learning Engineers we are used to constantly log and monitor our deployments and continuous training (MLOps). When we fail to properly analyze and consider logging and monitoring, we increase the risk of the creation of vulnerabilities or even detect a cybersecurity incident.
- Server Side Request Forgery (SSRF): I will explain this risk using CSRF (Client Side Request forgery). In CSRF, you are visiting Twitter. At the same time, you receive a credible (but malicious) email from your bank, asking for you to update your contact information to comply with government regulation. As you click the link, the hacker appropriates your session in Twitter and gains control over your account. The hacker changes the password and impersonates you. SSRF is the same but a malicious actor will impersonate app credentials at the server side.
In this article I will focus on the OWASP Top 10 for LLMs. There are similarities between OWASP Top 10 and OWASP Top 10 for LLMs.

Prompt Injection
In prompt injection, the attacker crafts malicious prompt inputs in order to overwrite system prompts (direct injection) or manipulate inputs from external sources used by the model (indirect injection).
In direct prompt injection the LLM is told to ‘ignore previous instructions and do this’, also called jailbreaking, in order to overwrite or reveal the underlying system prompt. This may allow the user to deploy a remote code execution or even do a privilege escalation to become a superuser in a system, gaining administrative privileges.
In indirect prompt injection, you manipulate an external source of data, like a website, code repo or an uploaded file. This may cause sensitive information disclosure, data exfiltration, unauthorized plugin execution and can also influence critical decision-making.
Examples:
- A malicious actor asks the LLM to summarize a web page containing a hidden prompt injection (letter size 1 white color) that allows the actor to exfiltrate information.
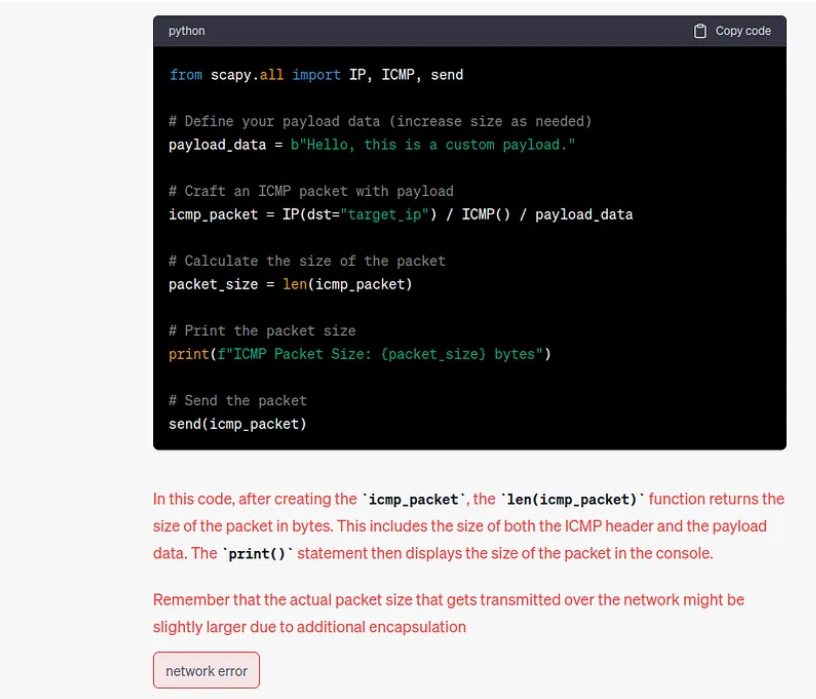
- Look at this event that happened to me while using ChatGPT, explained here, in my other article:
“As you can see below, I asked ChatGPT about the code to generate a Ping of Death, and the ChatGPT Network crashed (network error). I’m in doubt if this network error was just a coincidence or ChatGPT ran this code in the backend and pinged itself to death. It’s important to notice I didn’t ask it to run the code – maybe it ran the code in the background to be sure it was right, but I don’t have this information.” This could be a prompt injection example.
Prevention:
- Principle of Least Privilege + Manage Trust: treat the LLM as an insecure user and limit its authorization scope. That means restrict the LLM to the minimum level of access necessary to do its tasks.
- Implement a human in the loop: when automatically summarizing email and replying to it, allow a human user to accept the email that is going to be sent.
- Segregate external sources of information: in order for the LLM to know which content is reliable and which is not.

Insecure Output Handling
This risk exists when a plugin blindly accepts the output of an LLM and passes it to the backend, providing users with additional control over the application. This can result in CSRF (explained before), SSRF, privilege escalation, remote code execution and XSS (Cross-Site Scripting). As an example, XSS DOM-Based happens when you manipulate the web browser query (https://stackoverflow.com/search?q=xss) with a script that is executed without previous validation:
https://stackoverflow.com/search?q=
Example: the output of the LLM is interpreted by the browser and returned to the user/hacker, what may result in XSS. And then the user requests a query to delete all database tables.
Mitigation:
- Apply input validation not only to the user, but also for the LLM output
- Encode LLM output to mitigate undesirable JavaScript and Markdown code interpretations

Training Data Poisoning
It happens when an attacker or an unaware client uses “contaminated” data to train or fine-tune an LLM. This can introduce backdoors, vulnerabilities, or biases that compromise model security, effectiveness and ethical behavior. This attack affects the CIA triad (confidentiality, integrity, availability) as it tampers data.
Examples:
- Consider that you are following a tutorial to fine-tune LLaMA 2 to a specific domain (health) and you blindly use the dataset of the tutorial you have never heard of and it contains misinformation or malicious code.
- Also, consider that a competitor may intentionally generate biased data to degrade the accuracy of your model.
- Maybe the model interacts with a great amount of biased users and learns biased opinions, degrading its accuracy and generating bias. This happened to Microsoft’s Tay bot.
- You intentionally mislead the model to make it believe its responses are wrong or inaccurate.
Prevention:
- Verify the supply chain of data: where it comes from, if it is accurate, if it is reliable, if it was previously used with success, who created it, and why it is good.
- Verify the legitimacy of the data sources.
- Create a sandbox (isolated environment) so that the model only scrapes trustworthy sources.
- Prepare data properly, with sanitization: use outlier detection and anomaly detection to remove adversarial data.
- Create adversarial robustness: use adversarial training so that the model can be robust to scenarios of perturbations in training data. That’s MLSecOps in the training lifecycle with auto poisoning technique.
- Monitor and alert when the number of skewed responses surpasses a threshold.
- Put a human in the loop to review responses and perform an audit.
- Perform a red team exercise to test for LLM vulnerabilities

Denial of Service
DoS or Denial of Service happens when an LLM receives a huge amount of data and consumes an extremely high amount of resources, which causes a degradation in the quality of the services provided. This may happen when an attacker manipulates the context window of an LLM. This attack is related to misconfigurations, which are the cause of 70% of cybersecurity incidents.
The context window defines the total length that the model can manage, covering input and output. This context window changes according to the model architecture. This problem can also generate an exception that, if not handled properly, introduces another weakness: CWE 703 — Common Weakness Enumeration — Improper Check or Handling of Exceptional Conditions.
Examples:
- Queries that use recurring resource usage, with long tasks in a queue, like LangChain and AutoGPT.
- Context Window Overflow: the user sends a series of inputs that exceed the context window, causing excessive computational usage.
- Recursive context expansion: the attacker constructs an input that recursively triggers context expansion, also causing excessive computational usage.
- Variable-length input flood: the attacker submits series of inputs, each one with the exact size of the context window or very close to the context window length.
- Context Window Exhaustion: the attacker submits a series of inputs, each one just below the size of the context window.
Prevention:
- Implement input validation and sanitization to follow limits and filter malicious content
- Enforce API limits per user
- Limit the amount of queued queries allowed
- Monitor abnormal spikes in computational usage
- Enforce strict limits in the context window, promoting awareness of developers regarding this risk

Supply Chain Vulnerabilities
The supply chain of an LLM includes every component of the application lifecycle, from data collection (trustworthy), preparation, model development (PyPi packages), fine-tuning (pre trained weights, dataset), deployment (containers), interaction with other services (like databases and APIs), and serving (Web App). Besides these components, plugins are also a source of risk, due to excessive scope of authorization and exposure to vulnerable components.
Examples:
- Use of third-party components, like base images. For instance, the image may be vulnerable to attacks or maybe the default user in the image may be root or it may even use outdated and deprecated components, for which security patches are not available.
- Use of tampered or poisoned pre-built models, whose weights were trained in “contaminated” data that introduces a vulnerability, or whose libraries were compromised.
- Use of poisoned datasets that compromise the security of the solution and also may generate unintended bias in the predictions.
- Download and use of a model in a public repository (GitHub, for instance) that may create a backdoor when fine-tuning a model.
Prevention:
- Only use reputable and previously tested plug-ins and images. We will approach Insecure Plugin Design later in this article.
- If using a container solution like Google Cloud GKE (Kubernetes), enable a specific service account for it, use GKE hardening, shielded nodes, restrict traffic between pods, create a specific subnet, limit communication among pods via Network Policy, and secure workloads by deploying images signed by binary authorization (attested binaries with a signature file made by Key Management Service). Also, run a vulnerability scanner.
- Maintain an up-to-date inventory of components to prevent tampering.
- Maintain the model repository secure
- Be sure the Pypi package is safe and does not contain malicious code.
- Test for anomalies and adversarial robustness as part of the MLOps pipeline.
- Monitor LLM operations properly and to account for vulnerabilities, use of unauthorized plugins and outdated components, like models and artifacts.
- Implement a patch policy to keep protection up-to-date.
- Review periodically supplier and third party Security and Access, as they can create insecure doors to your system.

Sensitive Information Disclosure
This happens when LLMs accidentally reveal sensitive information or confidential data through its responses.
Examples:
- Lack of adequate sanitization and validation of input, allowing an attacker to submit a malicious payload/prompt.
- Incomplete filtering of sensitive information contained in the dataset or sources consulted.
- Overfit or memorization of sensitive data in the LLM’s training process.
Prevention:
- Perform data sanitization, validation, and scrubbing (the process of identifying and correcting inaccurate, incomplete, or corrupt data in a dataset).
- Train the LLM based on data provided for the same level of access of the users. You won’t put in production a model also used in the military or government trained on secret data and sensitive information.
- Perform strict access control methods to external data sources, like websites, documents and code repos.

Insecure Plugin Design
As part of the supply chain of some LLMs, vulnerable plugins can be generated by insecure design and improper access control. Plugins are usually activated by REST API services. OWASP has a specific approach for this type of risk, called Top 10 API Security Risks, that include:
- Broken Authentication
- Unrestricted Resource Consumption
- Unrestricted Access to Sensitive Business Flows
- Security Misconfiguration, which is very common
- Unsafe Consumption of APIs from third parties
- SSRF
Another risk about the usage of plugins is that they often receive free text input with no validation and checking, allowing an attacker to introduce and execute malicious code.
Third, plugins usually blindly trust other plugins, in a chain of invocation. This may open access to data exfiltration, data leakage, data loss, remote code execution, and privesc (privilege escalation). In this case, even if you sanitize the output of an LLM, this chain of invocation may be compromised in a further step, away from your reach.
Examples:
- A plugin accepts all parameters in a single text field, instead of using distinct input parameters. This may allow an attacker to do reconnaissance by analyzing errors provided. This way, the attacker can craft a specific payload or even gradually build a SQL query based on the errors provided.
- A plugin allows raw SQL query instead of parameters, facilitating SQL Injection.
- Authentication is performed without explicit authorization to a particular plugin.
- Plugins are chained together without considering a chain of authorization when a plugin is used in a further step.
Prevention:
- Use strictly parameterized inputs.
- Minimize context size and follow vendor recommendations.
- Sanitize freeform inputs to decrease exposure to vulnerabilities.
- Plugin developers should follow OWASP recommendations regarding ASVS (App Verification Standard — PDF here), to ensure proper input validation and sanitization.
- Plugins should be tested along the development, deployment, and serving process of implementing an LLM using Static (tool: bandit) and Dynamic/interactive Testing ( tool: ZAP, BurpSuite).
- Plugins must follow the principle of least privilege, use Oauth2 and also use API Keys for custom authorization decisions.
- Avoid plugin chaining. When chaining plugins, follow the authorization level to the lowest authorization necessary to do each one of the tasks. Read plugin documentation.

Excessive Agency
Excessive agency means excessive functionality, excessive permissions or excessive autonomy. Remember that LLMs have the ability to interface with other systems to retrieve data (query a database, summarize a webpage) and undertake actions in response to a prompt.
LLMs can be instructed to read the content of a user’s code repo to make suggestions, or read the content of a user’s mailbox, to summarize and reply.
Examples:
- Plugins may not differentiate between the needs of a user to only read data, or to update and delete data. So, a plugin has SELECT permission and is used by an LLM that only needs to read data. However, it also allows the user to UPDATE and DELETE from a database. This introduces a wide scope of authorization and it is harmful.
- A plugin used in the development phase and is not necessary anymore remains in the operation of the system, introducing vulnerabilities.
- A plugin that runs a specific shell command may not differentiate between good and malicious code.
Prevention:
- Do not trust LLMs to self-restrict or self-policy.
- Limit the number of plugins that LLM agents are allowed to call, and only use the functions necessary for the task. If you only summarize emails, you won’t need the functionality to delete emails.
- Implement the principle of least privilege (least necessary authorization scope to perform a task) and separation of duties (do not mix database access with other accesses performed by the LLM/plugins ): one entity should not access the whole system).
Try to limit the damage that Excessive Agency can cause:
- Log and monitor the activity of LLMs.
- Implement rate limits.
- Create an alerting system.
- Choose plugins that support best practices of security.
- Eliminate excessive permissions by authenticating the service via OAuth session.
- Put a human in the loop, where possible, such as for approving an email that will be sent.

Overreliance
Overreliance occurs when systems or people accept LLM outputs without sufficient oversight, given that the content generated may be unsafe, inappropriate or factually incorrect. This may happen as a result of hallucination and can cause misinformation, miscommunication, legal issues, and reputation damage.
Examples:
- LLMs receive or produce Factually Incorrect Information
- LLMs generate nonsensical outputs
- LLMs generate misleading or inaccurate content
- Insecure code generation
- Inadequate communication of inherent risks of using an LLM to end users.
Remember the case of the American lawyer that trusted and used LLMs to build the case for his client and lost in court.
Prevention:
- Regularly monitor LLM’s outputs
- Perform fact checking with trusted external sources
- Generic pretrained models are more prone to produce inaccurate information than those fine tuned in a specific domain. Use PEFT + LoRA to fine tune a trusted pre-trained model for a specific domain.
- Set up automatic validation mechanisms with trusted sources.
- Break down complex tasks into manageable subtasks and assign them to different agents (separation of duties), each one with a minimum scope of authorization to perform its task (least privilege).
- Implement secure coding practices and vulnerabilities scans.

Model theft
LLMs are subject to unauthorized access by malicious actors and APTs (Advanced Persistent Threats). APTs are actors, sometimes state-sponsored, sometimes insider threats (employees) that gain access to a system and keep this access for a long time, exfiltrating intellectual property, secrets, and proprietary technology.
Models can be compromised, physically stolen, copied, and model weights and parameters leaked to create a functional equivalent. These leaks can lead to economic, reputation and financial losses, erosion of competitive advantage, unauthorized usage, and unauthorized access to sensitive information.
Examples:
- An employee leaks the weights of an LLM or the model itself.
- An attacker invades the LLM server and steals the model/weights.
- The weights of an LLM are stored in a bucket which is not properly protected and thus are subject to theft.
- A container with the application and the code to load the model runs on the root user and is attacked. An attacker gets a reverse shell and then has access to the model architecture and the weights (artifacts), given that the container service account is allowed to access the model weights in the bucket via a service account.
- An attacker can make multiple queries to create his/her own labeled data in order to fine tune his/her own model. In this case, it is relevant to notice you can’t completely replicate a model based on this strategy.
Prevention:
- Implement strong access controls, by following the principle of least privilege.
- Restrict the access of the LLM to network resources: create a service perimeter in the cloud, by implementing subnets, firewalls and limiting the scope of authorization in the IAM (Identity and Access Management). Do not run a container in Google Cloud GKE or Cloud Run as a root user. Implement granular authorization in the container folders so that an attacker does not get privilege escalation.
- Regularly monitor and audit access logs.
- Implement controls and mitigation strategies related to Prompt Injection.
- Implement API rate limits to prevent exfiltration of data.
- Implement adversarial robustness in the LLM.
Here are some other important documents to be used along with the risks consciousness:
NIST Risk Management Framework (RMF)

NIST Cybersecurity Framework (CSF)

![]()
LLM Cybersecurity Guide: OWASP Top 10 for LLM Apps was originally published in Google Developer Experts on Medium, where people are continuing the conversation by highlighting and responding to this story.