Mining Turkish social media text with spaCy Turkish models
We all like to mine a good social media corpus. Whether long or short, social media text contains different types of information such as entities, sentiment value, and much more.
In this article, we’ll mine a brand new Turkish social media corpus called Corona-mini. As the name suggests, Corona-mini is a mini-dataset, it contains 180 instances — yet it’s packed with surprises 😉. The dataset is crawled from the popular Turkish social media website Ekşi Sözlük and contains experiences of authors with Corona symptoms. Most of the reviews were made during the initial Corona breakout, where everyone was dazed and clueless about the symptoms, as well as the short and long-term effects of Corona. The reviews aimed to share information, authors gave information about their experiences, as well as asking others for their experiences with the symptoms. The language is quite informal and reviews are packed with medical entities including symptom, disease, and drug names, hence this corpus lies somewhere between the social media text and medical text.

We’re going to mine this dataset with our brand new spaCy Turkish models [0]. The models are quite fresh 😉 and available on their HuggingFace repo. If you’re interested in training and packaging process of the packages, you can visit the blog post in [1] or even better watch the video tutorial in [2] in the references!!!

In this article, we’ll dive into corpus semantics. When it comes to extracting information from a corpus, semantics comes in layers. First layer of semantics comes with vocabulary statistics i.e. which vocabulary word appeared how many times. Vocabulary words can be further grouped by syntactic categories i.e. verbs, nouns, and adjectives (and possibly more, but I like to examine these three categories mainly). The next layer of the semantics is offered by the corpus entities. Entity statistics always provide valuable information about the corpus. Medical corpora are usually quite interesting, packed with drug, disease, body part names, as well as symptom names. The rest is looking for even finer details about the symptoms. If you’re ready, let’s get started by getting to know our corpus.
The corpus
As mentioned before, this corpus is crawled from the social media website Eksisozluk.com. A total of 180 reviews are compiled from two headlines:
https://eksisozluk.com/covid-19-belirtileri--6416646
https://eksisozluk.com/gun-gun-koronavirus-belirtileri--6757665
You can download this corpus from its dedicated Github repo or as a Huggingface dataset like this:
from datasets import load_dataset
dataset = load_dataset("turkish-nlp-suite/Corona-mini")
The corpus includes both short and long reviews, some instances of the corpus look like this:
"ön bilgi: çin'in hubei eyaleti, wuhan şehrinde, 31 aralık 2019'da etiyolojisi bilinmeyen pnömoni vakaları bildirilmiştir. wuhan'ın güneyindeki wuhan güney çin deniz ürünleri şehri pazarı çalışanlarında kümelenme olduğu belirtilmiştir. vakalarda ateş, dispne ve radyolojik olarak bilateral akciğer pnömonik infiltrasyonu ile uyumlu bulgular tespit edilmiştir. şu ana kadar bildirilen ölüm vakaları genellikle ileri yaştaki bireyler olmuştur. enfeksiyonun yaygın belirtileri: solunum semptomları, ateş, öksürük ve dispnedir. daha ciddi vakalarda, pnömoni ağır akut solunum yolu enfeksiyonu, böbrek yetmezliği ve hatta ölüm gelişebilir. kaynak: t.c. sağlık bakanlığı"
"öksürük, boğaz ağrısı, yüksek ateş, kas ve eklem ağrısı, baş ağrısı, halsizlik, bitkinlik ve solunum yetmezliği gibi "normal grip" semptomlarıyla benzerdir."
"coronavirüsten gerçekten korunmak istiyorsanız takip edeceğiniz tek düzgün kaynak var. o da aşağıdaki linkte yer alıyor. yok sıcak su için yok sıcakta ölüyor falan ilk entryi giren resmen ortaya bir yerinden sallamış... inanmayın böyle her canı sıkılanın kafadan attığı şeylere."
"eldiven, en az maske kadar önemli."
"kuru öksürük başladı boğazımda gıcıklanma var ama ateşim yok ve kendimi dinç hissediyorum. umarım bulaşmamıştır."
Looks good so far! What’s inside this tiny yet mighty corpus then? We dive into first part of corpus statistics: vocabulary word counts.
Just count
When I dissect a corpus, I always first look at vocab word counts. Though it sounds simple, vocab words are the gate to the semantics — after all, text are composed of words, right? 😉
We’re going to gather all word lemmas from all reviews and capture them in a Counter object. As the first task, we make the imports and load the spaCy model:
# you can install the model by https://huggingface.co/turkish-nlp-suite/tr_core_news_trf/resolve/main/tr_core_news_trf-any-py3-none-any.whl
import spacy
import datasets
from collections import Counter, defaultdict
nlp = spacy.load("tr_core_news_trf")
dataset = datasets.load_dataset("turkish-nlp-suite/Corona-mini", split="train")
Before starting the count, there’s a technical detail with Turkish word forms. Turkish words are composed of many morphemes, a root word (the lemma) and a sequence of suffixes. Hence while doing the vocab count, we accumulate the word lemmas; otherwise all the inflected forms from the same word will appear as different words; hence distribute the lemma weight across different inflected forms. That would be quite non-optimal. As a result, we use spaCy’s lemma_ attribute on tokens and we also skip the punctuation tokens. We iterate over all reviews in the corpus, lemmatize each word in the review and accumulate them into a counter. The resulting code looks like this:
all_lemmas = Counter()
for sentence in all_texts:
doc = nlp(sentence)
lemmas = [token.lemma_ for token in doc if not token.is_punct]
all_lemmas.update(lemmas)
After collecting all lemma counts into a Counter object, we can examine the most common lemmas:
>>> all_lemmas.most_common(40)
[('ve', 677),
('gün', 604),
('ol', 570),
('bir', 483),
('ağrı', 383),
('bu', 256),
('koku', 249),
('var', 240),
('de', 236),
('et', 217),
('al', 211),
('çok', 208),
('öksürük', 206),
('gibi', 202),
('ama', 198),
('test', 188),
('hafif', 182),
('gel', 179),
('başla', 176),
('tat', 174),
('da', 172),
('ara', 170),
('ateş', 167),
('ben', 166),
('devam', 153),
('yok', 150),
('sonra', 148),
('git', 147),
('iç', 147),
('çık', 146),
('belirti', 145),
('daha', 127),
('boğaz', 122),
('yap', 121),
('baş', 118),
('sabah', 118),
('için', 117),
('pozitif', 114),
('o', 107)
]
The most common vocab words is a mix of the most commonly used words of the spoken language such as ve, bir, et(mek), al(mak) and corona related words such as ağrı, koku, öksürük, test, ateş, belirti . Let’s see the vocab as a word cloud:

The vocab looks as expected, packed with corona related terms; the vocab speaks for this corpus. How about the entities? What is the story they’re telling us? We find that out next.
Hunting down the entities
In this section we’ll be hunting down corpus entities, group them by their labels and count each group. First of all, we get to know the spaCy Turkish model’s NER quickly, it’s trained on Turkish Wiki NER dataset [4]. It’s a brand new corpus as well, and as the name suggests, it’s a general purpose NER dataset for Turkish. It contains 19 labels total and you can see the details either on its Github repo as well as on the HuggingFace repo.

Again, we’re going to go over all the corpus and collect the entities by doc.ents . Indeed, we’ll collect a tuple of the form (LABEL, TEXT) for each entity, accumulate them in a dictionary of lists where keys are the labels and values are the all entity values that are labelled as the key value. The code looks like this:
ent_counter = defaultdict(list)
for sentence in all_texts:
doc = nlp(sentence)
ents = [(ent.label_, ent.text) for ent in doc.ents]
for label, text in ents:
ent_counter[label].append(text)
After accumulating the entities and labels, we can do a bit of label statistics and count the labels. The label counts are as follows:
>>> for ent_type, ent_list in ent_counter.items():
print(ent_type, len(ent_list))
GPE 10
DATE 270
ORG 63
CARDINAL 405
NORP 5
TIME 125
TITLE 4
QUANTITY 17
PERCENT 56
ORDINAL 458
PERSON 8
LANGUAGE 1
EVENT 2
PRODUCT 41
WORK_OF_ART 4
LOC 4
MONEY 1
We can make a quick histogram to see the label counts better on the paper:
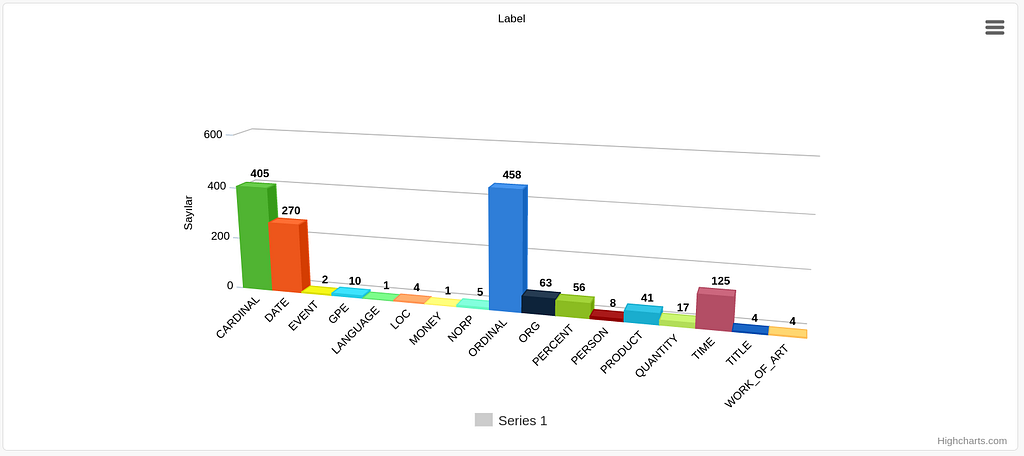
Looking at the label counts we see that lion’s share is taken by the numerical type entities; CARDINAL, ORDINAL , DATE , TIME , and PERCENT . Cardinal and ordinal numbers occur regularly in almost all types of corpora (so they may or may not be related to Corona symptoms directly); however, dates, times, and percents certainly provide clues about this corpus. Medical corpora (such as doctor notes or medical reports) usually contains a good amount of dates and times; the concept of time is crucial in medicine in general. Doctor notes contain patient health history expressions (either narrated by the patient or the doctor) such as abdominal pain for one week , the patient has already visited the ER 2 days ago with a high fever ; patient health history, disease symptoms and complaints almost all the time appear with a time frame reference.
Organizations and product type entities come as the second winners. We can guess that organization type entities refer to either hospitals, the Ministry of Health, or related government organizations. On the other hand, product type entities most probably contains drug names, hence contains quite valuable information. After this small guessing game, let’s dive into the entity values of each of the labels. Remember that we collected the values into a dictionary already 😉 . I made a pprint to the dictionary and collected some highlights for us. First, some values that fall under CARDINAL type:
'bir',
'bir',
'bir',
'39',
'38',
'37.8',
'3',
'2',
'bir',
'üç',
'üç',
'1000’lik',
'iki milyondan',
'bir',
'1000',
'1',
'birer',
'10',
'1',
'14',
'iki',
'iki',
'2',
'2',
'38.2',
'37.4',
'37.5-38.5'
The values 39, 38 , 37.8, 38.2 , 37.4 and 37.5-38.5look like fever values and this label indeed contains quite many of them! Another numeric type DATE is also popular in this corpus and some values are:
"31 aralık 2019'da",
'12 ayı',
'bir haftanın sonunda',
'3 ay sonraya',
'ocak ayı ortasında',
'1 hafta',
'iki gündür',
'27 haziran',
'28 haziran',
'1 hafta sonra',
'pazartesi',
'cumartesi sabahı',
'iki gün önce',
'pazar',
'pazartesi',
'salı',
'15 mart 2020',
'nisanın ortasında',
'12.11.20',
'15.11.20 10:00',
'11: 29.11.20',
'pazartesi',
'cuma',
'12: 02.12.20 akşam üstü',
'cuma günü',
'cumartesi günü',
'20 kasimda',
'bir aydan',
'20 gün',
'üç günde bir',
'1 hafta sonra',
'2 haftada',
'1-2 gun',
'3 gün önce',
'iki gündür',
'3 gün sonra',
'6 ay önce',
'3 gün once',
'iki gündür',
'bir buçuk yıl',
DATE strings comes with a great variety, from exact dates to time intervals, from days to months and years; we told you medical corpora always has a good amount and variety of dates 😉. TIME values offer some solid variety as well, both exact times and time intervals:
'16:32',
'saat 11:48',
'20:13',
'6 saat',
'7',
'yarim saat',
'bir saat',
'36 saat',
'bir iki',
'saat 11',
'12:00',
'13:00',
'9',
'10',
'2',
'08:30 gibi',
'22:00',
'16:00’da',
'20:00',
'22:30',
'11:00',
'2ye'
Some other entity types have interesting offerings too:
'GPE': ["çin'in hubei eyaleti",
'wuhan',
"wuhan'ın",
'idlib',
'avrupa',
"türkiye'ye",
"türkiye'ye",
"ankara'dan",
"turkiye'de"],
'LANGUAGE': ['ingilizce'],
'LOC': ['güneş',
"üsye'ye",
],
'MONEY': ['370 tl'],
'NORP': ['çinli', 'ingiliz', 'ingiliz', 'ingiliz'],
'QUANTITY': ['1 metre',
'3 kg',
'1.5 kg',
'38 derece',
"5'er ml",
'2 km',
'1lt',
'2 ila 3 litre',
"40'lık",
'200 mg',
"10'lık",
'200 mg',
'2,5 -3 litre',
'3 litreye',
'beş kg',
'20km',
'81 mg',
'bir ton çay'],
'TITLE': ['sağlık bakanı',
"abd başkanı'nı",
'kbb uzmanı',
'kalp doktorum'],
Now comes two lion’s shareholders, ORG and PRODUCT types. The entities that are labelled as ORG as follows:
't.c. sağlık bakanlığı',
'facebook',
'112 acil yardım hattını',
"youtube'da",
'twitter’da',
'ilçe sağlıktan',
'devlet hastanesi',
'sağlık bakanlığından',
'katarin',
'özel hastaneye',
'bakanlıktan',
'ilçe sağlık müdürlüğünden',
'sağlık bakanlığından',
'kardiyolojiye',
'devlet hastanesine',
'devlet hastanesinde',
'sağlık bakanlığı',
'dahiliye',
'112',
'112',
'youtube',
'sağlık bakanlığından',
'devletin',
'sağlık bakanlığından',
"youtube'de",
'sağlık bakanlığı',
As expected, ORG entities of this corpus are hospitals, sections of a hospital (such as internal medicine and cardiology), health ministry, emergency hotline (112), online video sharing and social media platform Youtube, and more government organizations related to public health. Quite many organizations, both governments and international organizations, played great roles during pandemic, hence this result is no surprise.
The last but most juicy label type is PRODUCT. This label contains both drugs that are used for curing the symptoms and curing Corona itself:
'favira',
"cdc'ye",
'paracetamol',
'tylol hot',
'coronavirüs',
"covid-19'u",
'pleanaquili',
'parol',
'favicoviri',
"favimol'u",
'favimol',
'parol',
"byopecia multiplex'e",
'berazinc',
'devit3',
'covidten',
'corona',
'nosemix',
"covid'e",
"favicovir'i",
'favicovir',
'coraspin 100',
'favimolü',
'favimol',
'covid',
'favira',
'ferin',
"favimol'den",
'parol',
'parol',
'tylolhot',
'tylolhot',
'tylolhot',
'tylolhot',
'nurofen',
'otrivine',
'favimol',
'favimol',
'aferin',
'parol',
'parol'
What does this tableau tells us at all? When we add all the entity labels and values above to the table, we see that they indeed provide us the essence of this corpus; all entities that are involved during pandemics, health organizations offering help to community, dates and times for describing symptom durations, drugs that are used for curing the disease, and the disease itself…thanks to God, the Corona storm had ended, however it left an unforgettable experience to all humankind and as a result brought medical terminology to every day spoken language.
Dear readers, we reached the end of this article. Medical corpora always has interesting entities and is a pleasure to process. This mini Corona corpus was no exception. For more of Turkish NLP, more of semantics and, more of NLP please follow Turkish NLP Suite Github/webpage or my Youtube channel or connect me on Linkedin. Until then stay tuned and stay happy!
References:
[0] spaCy Turkish models HF and Github pages [1] Brand new spaCy models blog post on Google GDE Medium [2] How to train spaCy models on my Youtube channel NLP with Duygu [3] Turkish NLP Suite webpage and Github page [4] Turkish Wiki NER Dataset : Github and Huggingface![]()
Quick recipes with spaCy Turkish: How is your infection doing? was originally published in Google Developer Experts on Medium, where people are continuing the conversation by highlighting and responding to this story.