
Brand new spaCy Turkish models are trained, packaged and waiting for to be used on your datasets. Let’s see them in action!
Despite being a widely spoken language across Asia and Europe with over 80M speakers, Turkish hasn’t enjoyed quite as many linguistics resources. Finding a state-of-art pretrained model hasn’t been easy at all and the synthetic nature of Turkish poses many challenges for the ones who are interested in preparing pretrained models for the community. Fortunately, my winter campaign “NLP with Duygu” comes with many resources including pretrained spaCy language models!

In this article, we’ll get to know the packages; first we’ll have a look at the development process by reviewing features of Turkish and how to embed these features into the development process. Then we can enjoy the packages by playing with the output and observe how morphosyntactic features of Turkish is reflected to the package outputs. We get started with the packages themselves:
The packages
Turkish spaCy models come in three flavors: tr_core_web_md , tr_core_web_lg and tr_core_web_trf . tr_core_web_lg is a CNN-based large sized model, which offers good accuracy and works at a decent speed. tr_core_web_md has the same architecture but the vectors are one size smaller (we’ll come to that). tr_core_web_trf is a Transformer based pipeline. It offers great accuracy and if you have good computing resources (even better some GPUs), this should be the weapon of your choice.
All pipelines contain a tokenizer, trainable lemmatizer, POS tagger, dependency parser, morphologizer and NER components. All models are available for download on their Hugging Face repo [1].
Pipeline components
We can start discovering the new packages by looking at the pipeline components. First let’s pip the transformer based model:
pip install https://huggingface.co/turkish-nlp-suite/tr_core_news_trf/resolve/main/tr_core_news_trf-any-py3-none-any.whl
pipe_names method will show us the available pipeline components:
>>> import spacy
>>> nlp = spacy.load("tr_core_news_trf")
>>> nlp.pipe_names
['transformer',
'tagger',
'morphologizer',
'trainable_lemmatizer',
'parser',
'ner']
The other two models have the same components except the transformer -they have tok2vec instead.
After examining the pipe components, we’re ready to run some sentences through our pipeline 😊. Let’s start easy with a short example sentence:
>>> sentence = "Ben de Ankara'ya gittim."
>>> doc = nlp(sentence)
>>> for token in doc:
print(token.text, token.pos_, token.dep_, token.lemma_, token.morph)
Ben PRON nsubj ben Case=Nom|Number=Sing|Person=1
de CCONJ advmod:emph de
Ankara'ya PROPN obl Ankara Case=Dat|Number=Sing|Person=3
gittim VERB ROOT git Aspect=Perf|Evident=Fh|Number=Sing|Person=1|Polarity=Pos|Tense=Past
. PUNCT punct .
We can see the results of each component 1-by-1. The second column show POS tags, generated by tagger component. The sentence contains a pronoun, a conjunction, a proper noun, and a verb. The third column shows the dependency labels, this roughly reads as the subject of the verb, adverb of the verb, oblique object of the verb, and the verb itself. The fourth and fifth columns are related to morphology, token.lemma_ method exhibits token’s lemma and token.morph offers full morphological analysis of the token, including all inflectional suffix types and more information (more onto morphology will come in another post). If you want to learn more about Turkish morphology and syntax, I’ll be writing a post on each. You can also visit my playlist, “All About Turkish Linguistics” [3]. We’re having only a peek here in this article – Turkish sentence structure and word forms takes a little bit effort to grasp fully 😄
As a result the dependency tree of this sentence looks like:

How about the NER component? NER tags the only entity of the sentence as GPE , a place type entity:

spaCy Turkish models are trained on Turkish Wiki NER Dataset, which has 19 tags. This is a general purpose NER dataset, hence tagset includes common entity types such as person, place, organization names, as well as numeric entity types. Full tagset can be found under the dataset’s Github and Hugging Face pages [4].
So far so good, how about more syntactically complicated sentences? Surely our models can tackle them too, check out this parse of the following example sentence which includes an adjectival clause and several entities:
>>> sentence = "Ankara Esenboğa Havaalanı'ndan ayrılan uçak 1 saat gecikmeyle saat 17:00 civarı İstanbul'a indi."
>>> doc = nlp(sentence)
>>>for token in doc:
print(token.text, token.pos_, token.dep_, token.lemma_, token.morph)
Ankara PROPN obl Ankara Case=Nom|Number=Sing|Person=3
Esenboğa PROPN flat Esenboğa Case=Nom|Number=Sing|Person=3
Havaalanı'ndan NOUN flat Havaalan Case=Abl|Number=Sing|Number[psor]=Sing|Person=3|Person[psor]=3
ayrılan VERB acl ayrıl Polarity=Pos|Tense=Pres|VerbForm=Part
uçak NOUN nsubj uçak Case=Nom|Number=Sing|Person=3
1 NUM nummod 1 NumType=Card
saat NOUN obl saat Case=Nom|Number=Sing|Person=3
gecikmeyle NOUN obl gecikme Case=Ins|Number=Sing|Person=3
saat NOUN obl saat Case=Nom|Number=Sing|Person=3
17:00 NUM obl 17:00 NumType=Card
civarı ADJ obl civar Case=Nom|Number=Sing|Number[psor]=Sing|Person=3|Person[psor]=3
İstanbul'a PROPN obl İstanbul Case=Dat|Number=Sing|Person=3
indi VERB ROOT in Aspect=Perf|Evident=Fh|Number=Sing|Person=3|Polarity=Pos|Tense=Past
. PUNCT punct .
Notice the participle form ayrılan that forms the clause “Ankara Esenboğa Havaalanı’ndan ayrılan” to modify the noun “uçak”. This clause looks like the following in the sentence’s parse tree:
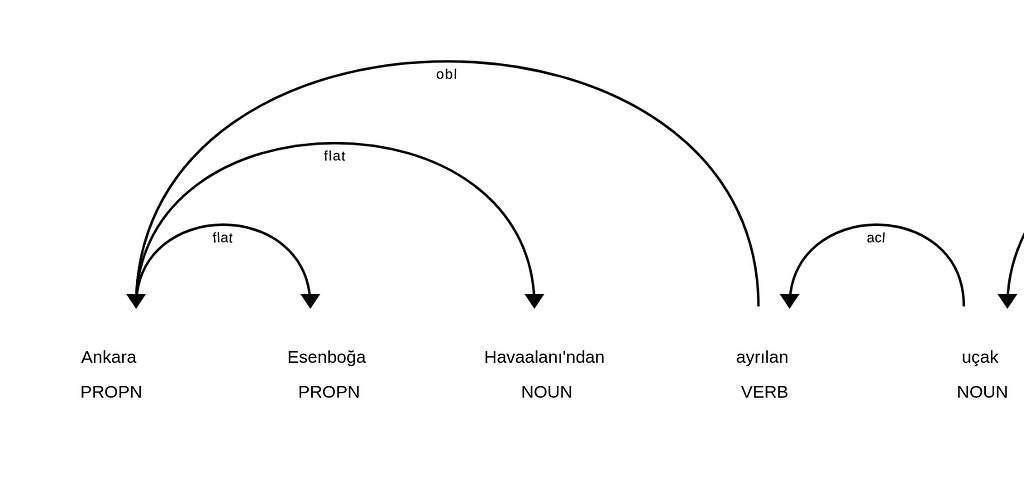
How about entities? This sentence includes four entities of three different types: two times, one famous building and one city:

Both parse trees and entity annotation look beautiful and handy, however beauty comes with some effort always. When it comes to processing, Turkish has its very own challenges.
Challenges with processing Turkish
In my experience, the first challenge of Turkish is finding a good treebank for training the parser, tagger, and morphologizer components. For our spaCy mission, I used Turkish BOUN Treebank [5]. This is a great treebank with a commercially permissive license.
The second challenge comes from the Turkish language itself, Turkish has a quite complex and reproductive morphology. We already saw some word form examples above, in a more detailed look we can notice the “long” morphology strings:
gittim VERB ROOT git Aspect=Perf|Evident=Fh|Number=Sing|Person=1|Polarity=Pos|Tense=Past7
Ankara'ya PROPN obl Ankara Case=Dat|Number=Sing|Person=3
Havaalanı'ndan NOUN flat Havaalan Case=Abl|Number=Sing|Number[psor]=Sing|Person=3|Person[psor]=3
Quality and the quantity of the treebank is crucial here, such morphological features are difficult to learn for even most powerful NNs. During the training, one needs to show enough examples of verbal forms, verbal suffixes as well as nominal forms and nominal suffixes. That adds up to a quite many training instances for Turkish 😄. Syntax goes hand-in-hand with morphology (just as in the adjectival clause example), putting it together morphosyntax is the main challenge of Turkish.
Subword representations, Floret vectors and Transformers
As we see above, an arbitrary number of suffixes can be added to a Turkish root. As a result, Turkish word forms are composed of many morphemes and can be quite long strings. In order to vectorize Turkish text correctly, one certainly needs subword strategies.
Transformers type tokenizers started a revolution by decomposing words into several part of words to represent even the rarest of the language, hence leaving no space for OOVs at all. Part-of-word type vocabs are quite beneficial for Turkish too, as you can guess words enjoy being decomposed into smaller parts (strategies for decomposing the word forms will come in another article). As we already remarked, tr_core_web_trf is a Transformer based model hence having a WordPiece type vocabulary.
tr_core_web_lg and tr_core_web_md are packaged with static vectors, obviously we needed vector types that support morphemes of Turkish. Here Floret vectors come to rescue. Floret is an extended version of fastText that uses Bloom embeddings to create compact vector tables with both word and subword information. Turkish morphemes enjoy subword representations quite a bit, hence quite proper for our new packages. Our Floret vector can be individually downloaded from their Hugging Face repos too [1]. Before picking the correct parameters, we experimented with subword length parameters.
Putting it altogether & the training process
Putting it all together, we packaged Floret vectors, downloaded a Turkish Transformer model from Hugging Face, prepared the NER dataset and the treebank. Finally all we had to do was to write these plain yaml lines to start the training:
workflows:
all:
- preprocess_ud
- train_tagger
- evaluate_tagger
- preprocess_ner
- train_ner
- evaluate_ner
- assemble
- package
All scripts can be find under spaCy Turkish Github repo.
Training was done on Google Cloud. Thanks to generous support of the GDE program 😊. All models were trained on a c2-standard-16 type instance. If you want to do the training together, you can watch my video tutorial “How to train spaCy models” here. Please be aware that my instance is called duygu1 😄 😄 (there’s a duygu2 too, it’s a TPU VM).
Dear readers, this was our peek to the brand new spaCy Turkish models. This work is a part of my Fall-Winter 2023 campaign “Turkish NLP with Duygu” and generously supported by Google Developer Experts program.
If you want to learn more about Turkish NLP, you can visit my campaign webpage or even better my Youtube channel “NLP with Duygu”. It’s always great to meet you for Turkish NLP, for more of content please stay tuned and happy meanwhile 🎉🎉🎉
References
- Turkish NLP Suite Hugging Face: https://huggingface.co/turkish-nlp-suite
- Turkish NLP Suite Github: https://github.com/turkish-nlp-suite
- All About Turkish Linguistics playlist: https://www.youtube.com/watch?v=ZiArCDOuNVo&list=PLJTHlIwB8Vcqltlhbmsc12Srthv73OeOF
- Turkish Wiki NER Dataset
Github: https://github.com/turkish-nlp-suite/Turkish-Wiki-NER-Dataset
Huggingface: https://huggingface.co/datasets/turkish-nlp-suite/turkish-wikiNER - Turkish BOUN Treebank: https://github.com/UniversalDependencies/UD_Turkish-BOUN
![]()
Brand new spaCy Turkish models was originally published in Google Developer Experts on Medium, where people are continuing the conversation by highlighting and responding to this story.




