x-crawl
x-crawl is a flexible Node.js multifunctional crawler library. Flexible usage and numerous functions can help you quickly, safely, and stably crawl pages, interfaces, and files.
If you also like x-crawl, you can give x-crawl repository a star to support it, thank you for your support!
Features
- 🔥 Asynchronous Synchronous – Just change the mode property to toggle asynchronous or synchronous crawling mode.
- ⚙️ Multiple purposes – It can crawl pages, crawl interfaces, crawl files and poll crawls to meet the needs of various scenarios.
- 🖋️ Flexible writing style – The same crawling API can be adapted to multiple configurations, and each configuration method is very unique.
- ⏱️ Interval Crawling – No interval, fixed interval and random interval to generate or avoid high concurrent crawling.
- 🔄 Failed Retry – Avoid crawling failure due to short-term problems, and customize the number of retries.
- ➡️ Proxy Rotation – Auto-rotate proxies with failure retry, custom error times and HTTP status codes.
- 👀 Device Fingerprinting – Zero configuration or custom configuration, avoid fingerprinting to identify and track us from different locations.
- 🚀 Priority Queue – According to the priority of a single crawling target, it can be crawled ahead of other targets.
- ☁️ Crawl SPA – Crawl SPA (Single Page Application) to generate pre-rendered content (aka “SSR” (Server Side Rendering)).
- ⚒️ Control Page – You can submit form, keyboard input, event operation, generate screenshots of the page, etc.
- 🧾 Capture Record – Capture and record crawling, and use colored strings to remind in the terminal.
- 🦾 TypeScript – Own types, implement complete types through generics.
Example
Take the automatic acquisition of some photos of experiences and homes around the world every day as an example:
// 1.Import module ES/CJS
import xCrawl from 'x-crawl'
// 2.Create a crawler instance
const myXCrawl = xCrawl({maxRetry: 3,intervalTime: { max: 3000, min: 2000 }})
// 3.Set the crawling task
/*
Call the startPolling API to start the polling function,
and the callback function will be called every other day
*/
myXCrawl.startPolling({ d: 1 }, async (count, stopPolling) => {
// Call crawlPage API to crawl Page
const res = await myXCrawl.crawlPage({
targets: [
'https://www.airbnb.cn/s/experiences',
'https://www.airbnb.cn/s/plus_homes'
],
viewport: { width: 1920, height: 1080 }
})
// Store the image URL to targets
const targets = []
const elSelectorMap = ['._fig15y', '._aov0j6']
for (const item of res) {
const { id } = item
const { page } = item.data
// Wait for the page to load
await new Promise((r) => setTimeout(r, 300))
// Gets the URL of the page image
const urls = await page.$$eval(
`${elSelectorMap[id - 1]} img`,
(imgEls) => {
return imgEls.map((item) => item.src)
}
)
targets.push(...urls)
// Close page
page.close()
}
// Call the crawlFile API to crawl pictures
myXCrawl.crawlFile({ targets, storeDir: './upload' })
})
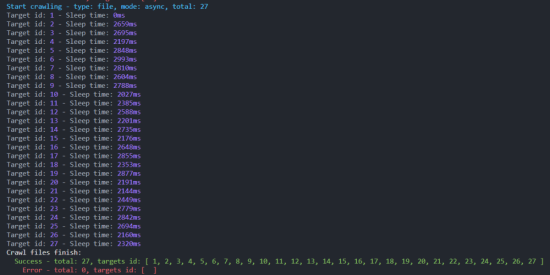
running result:


Note: Do not crawl at will, you can check the robots.txt protocol before crawling. This is just to demonstrate how to use x-crawl.
More
For more detailed documentation, please check: https://github.com/coder-hxl/x-crawl




