We love sharing the accomplishments of the Google AI communities over the month. We appreciate all the hard work and dedication of our community members. Without further ado, here are the key highlights by products!
Antigravity

Confused About Where to Put Your Agent Skills? by Cloud GDE Darren Lester (UK) explains where agentic tools look for skills and highlights the confusion caused by differing locations. He proposes using symlinks to maintain a single source of truth at ~/.agents/skills as a future-proof solution.
How agentic AI resurrected my “Old” side project by Cloud GDE Jean-Philippe BACONNAIS (France) shares how Antigravity helped revive a dormant genealogy tree application by migrating legacy code to Quarkus and improving the UI. Facilitating tasks like documentation updates and UI harmonization allows the author to focus on new features and improvements.

Taking Action on your GCP bill: Automating BigQuery Storage Cleanup by Cloud GDE Marcelo Costa (Brazil) explains how to automate BigQuery storage cleanup using a bash script and Antigravity’s agentic workflow to reduce costs.
Scaling your productivity with spec docs in your IDE — Anti Gravity. by Angular GDE Matthew Christiansen (US) discusses improving developer productivity by using specification documents and Anti Gravity within the IDE. It suggests treating prompts as configuration through modular .md files to reduce mental overhead and create a scalable development process.
Gemini CLI
How I Distilled 27k Lines of AI Chat History into a Local LLM Wiki by AI GDE Guan Wang (Singapore) describes an experiment using the Gemini CLI to distill extensive Gemini chat history into a structured, localized AI. The resulting wiki acts as a personalized assistant summarizing facts, analyzing workflows, and identifying problem-solving habits.
Documentation as Context: A Skill to Automate Your Blueprints for the Agentic Era
Documentation as Context: A Skill to Automate Your Blueprints for the Agentic Era by Cloud GDE Darren Lester (UK) introduces an agent skill called project-documentation skill designed to automate and standardize documentation practices for software projects, especially in the context of AI agents. It emphasizes the importance of up-to-date documentation for both human developers and AI agents, detailing how the skill helps maintain READMEs, architecture documents, UI design guides, and testing documentation.

Using Gemini CLI with a Local LLM by Cloud GDE Masahiko Utsunomiya (Japan) details how to configure Gemini CLI to use a local LLM backend by combining LiteLLM Proxy and Ollama. It provides a practical guide to redirect API requests and address potential issues like missing model aliases.
Gemini

Gemini Embedding 2 — Complete Guide by AI GDE Pedro Lourenço (Brazil) is a Colab notebook providing a hands-on guide to Gemini Embedding 2 capabilities, covering word-vector arithmetic and cross-modal searches.


ADK
Saying Goodbye to Lengthy Prompts: A Practical Analysis of Google ADK Agent Skill Features by Cloud GDE Yu-wei Liu (Taiwan) introduces the Agent Skill feature in ADK v1.25.0, exploring its architecture, implementation, and benefits like reduced context burden. It discusses advantages such as modularity and team collaboration while addressing potential challenges like metadata quality and dynamic loading latency.
#Gemma 4 Running Google’s Gemma-4b locally with Google ADK and dual A40 GPUs by Cloud GDE Ashmi Banerjee (Germany) guides you through running Gemma-4b locally using ADK and dual A40 GPUs covering environment setup, vLLM serving, and LiteLLM integration.
https://medium.com/media/441b0c30781626a495f91b3383e15039/href
End-to-End AI Agent on GCP: ADK, BigQuery MCP, Agent Engine, and Cloud Run (repository | video) by Cloud GDE Mazlum Tosun (France) explains how to build and deploy an AI agent that queries BigQuery using natural language via ADK and Gemini 2.5 Flash without managing MCP servers.
Gemma

Gemma 4 Tutorial: Build a Local AI Coding Agent with Gradio and Ollama by AI GDE Aashi Dutt (India) explains how to build a local, multimodal AI coding assistant using Gemma 4, Ollama, and Gradio with agentic tool use.
Serve and Inference Gemma 4 on TPU by AI GDE Nitin Tiwari (India) explains how to deploy and run inference with Gemma 4 on TPUs using vLLM. It demonstrates setting up a TPU v6e instance and using a frontend application to achieve significantly lower latency compared to traditional GPUs.
Running Gemma 4 E2B on CPU: Is Local AI Finally Practical? (Kaggle notebook) by AI GDE Gabriel Preda (Romania) tests Gemma 4 E2B on a no-GPU setup to evaluate performance, limitations, and real-world usability. Gabriel also shared From OOM Errors to Working Model: Fine-Tuning Gemma 4 E2B Step-by-Step using Unsloth (Kaggle notebook) for a limited hardware environment.
TPU v6e vs A100 80GB×2 for Gemma 4 31B on vLLM: 21 Benchmarks Show When Each Wins by AI GDE Sho Tanaka (Japan) compares the performance of TPU v6e-4 and NVIDIA A100 across 21 input/output profiles for serving Gemma 4 31B. It demonstrates that TPU excels in short profiles and TPOT latency, while A100 performs better in medium and long profiles.
Deploy Gemma 4 on Cloud Run: Pay Only When You Actually Use It by Cloud GDE Daniel Gwerzman (UK) details how to deploy Gemma 4 on Cloud Run to leverage scale-to-zero capabilities and covers improvements like reasoning and function calling.
The Gemma 4 E2B Fine-Tuning Cookbook by AI GDE Rabimba Karanjai (US) provides a complete recipe for adapting Gemma 4 E2B to a specific domain by covering dataset construction, QLoRA configuration, and production deployment.
Taming the Giant: Fine-Tuning Gemma 4 E2B-IT into an Insurance Expert by AI GDE Guan Wang (Singapore) details the process of fine-tuning Gemma 4 E2B-IT using Tunix on TPU v5litepod-4 to create a high-precision insurance advisor. It covers overcoming memory limitations, data engineering with InsuranceQA-v2, and LoRA application to improve accuracy.
Fine-tuning Gemma
Beyond Classification Labels: Fine-Tuning Gemma 3 1B-IT with Financial Reasoning (part 1, part 2) by AI GDE Luca Massaron (Italy) discusses fine-tuning for financial sentiment analysis using reasoning-augmented data from teacher-student distillation.
Post-Training Gemma 3 for Earth Observation (EO) Understanding: A JAX Stack + TPU Pipeline for Multi-Label Sentinel Satellite Remote Sensing Scene Classification (repository) by AI GDE Henry Ruiz (US) introduces a domain-focused post-training and benchmarking pipeline for adapting Gemma 3 4B IT to Earth Observation tasks using a TPU-native JAX stack.

JAX & TPU


Run Any HuggingFace Model like Gemma3 on TPUs: A Beginner’s Guide to TorchAX (repository) by AI GDE Ahmed Elnaggar (Germany) guides on running HuggingFace models on TPUs using TorchAX to leverage JAX’s high performance without rewriting code. Ahmed also shared a follow-up tutorial, Fine-Tune Any HuggingFace Model like Gemma on TPUs with TorchAX.
Loading and Transform your Dataset using Grain for Model Building in JAX/FLAX by AI GDE Joan Santoso (Indonesia) introduces Grain and demonstrates building a sentiment analysis model in JAX/Flax. It covers creating custom data sources and transformations to build efficient data loaders for training.
Building a Nano MoE Language Model in JAX from Scratch by AI GDE Kartikey Rawat (India) provides a deep dive into the mechanics and importance of MoEs and demonstrates how to build a model using pure JAX/Flax.
Building Neural Networks with Flax NNX by AI GDE Wesley Kambale (Uganda) introduces NNX and covers building a CNN for image classification using production-grade architectures.
Autoscaling LLM Inference on GKE with TPU v5e and vLLM by AI GDE Anubhav Singh (India) shares a practical guide on deploying and autoscaling LLM inference using vLLM on GKE with TPU v5e with details of quota management, capacity planning, and etc.
A guide to speeding up and vectorizing for NumPy users by AI GDE Sho Tanaka (Japan) provides an introductory guide for NumPy users to speed up and vectorize code using JAX. Key features: PRNG differences, jax.jit compilation, jax.vmap vectorization, and automatic differentiation.
Benchmarking TPUs for Search Problems (repository) by AI GDE Vikram Tiwari (US) benchmarks TPUs for search problems using JAX and Antigravity. He creates scripts to identify TPU resources and uses YAML-based experiment setups to perform searches on public datasets.
Pallas
[Featured on TPU Developer Hub ✨] Pallas for people who know JAX but not kernels yet by AI GDE Aritra Roy Gosthipaty (India) introduces and explores Pallas to write custom, high-performance kernels within the JAX ecosystem. It demonstrates how Pallas abstracts hardware complexities, simplifying the process of writing optimized, hardware-level code.Fused INT8 Weight-Only Quantization in Pallas by AI GDE Rishiraj Acharya (India) shares how he wrote a custom JAX/Pallas kernel for INT8 weight-only quantization to accelerate LLM text generation by streaming compressed weights directly into local SRAM. This approach doubles memory efficiency by decompressing weights on the fly within hardware registers to avoid main memory bottlenecks while maintaining the codebase in Python. Rishiraj also shared two practical guides:
- Block-Sparse Attention Kernel via JAX/Pallas: how to build a custom Block-Sparse Attention kernel in JAX/Pallas to fix the massive memory and compute bottlenecks that happen when LLMs process long text.
- Ring Attention & Sequence Sharding with JAX: hands-on deep dive into overcoming the KV cache memory bottlenecks of million-token context windows using Ring Attention on TPUs.
Profiling TPU Kernels — XProf, HLO, and the Roofline Model by AI GDE Keshan Sodimana (Sri Lanka) provides a systematic protocol for diagnosing TPU kernel performance bottlenecks using XProf, HLO, and the roofline model. It covers capturing traces and decoding compiler output to optimize custom kernels in Python. Keshan also shared The Ratchet Loop: Optimizing a TPU Kernel abo how to optimize a TPU kernel to the hardware ceiling using the Ratchet Loop for reproducibility and regression prevention.
Fine-tuning Gemma using JAX and TPU
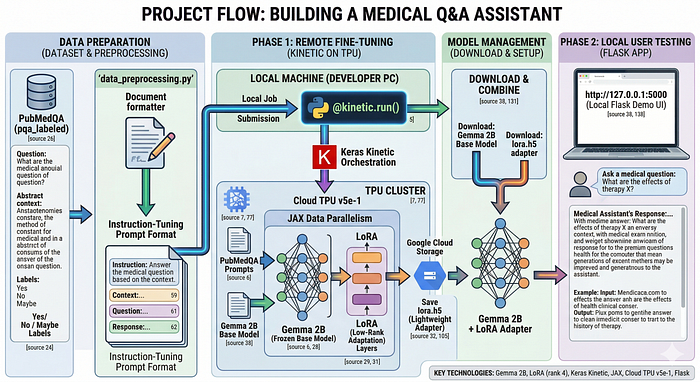
Building a Cardiology Assistant: Synthetic Data and JAX-Based Fine-Tuning by AI GDE Luca Massaron (Italy) demonstrates building a specialized cardiology assistant using a compact model and an efficient JAX/Tunix pipeline. It covers synthetic data generation, fine-tuning, and evaluation to showcase domain adaptation without requiring massive models and datasets.

Write Once, Scale Everywhere by AI GDE Rabimba Karanjai (US) presents an end-to-end pipeline for fine-tuning Gemma 2B using LoRA and serving it via a custom REST API. It utilizes KerasNLP and JAX as a backend to enable flexible execution on both NVIDIA GPUs and Cloud TPUs while demonstrating performance gains through XLA compilation.
Fine-tuning Gemma 3 on Burmese Agriculture QA Dataset (TPU + Tunix + LoRA) (repository) by AI GDE Aye Hninn Khine (Thailand) focuses on fine-tuning Gemma 3 on a Burmese agriculture dataset using TPUs and LoRA.
Implementations & Tools in JAX
- jaxgpt: Building LLMs in JAX and TPUs by AI GDE Aakash Nain (India): a showcase of how to build and train scalable LLMs in pure JAX using a multi-host environment
- QwenImage Inference on TPU with PyTorch/XLA by AI GDE Sayak Paul (India): PyTorch/XLA based SPMD implementation of the QwenImage image-gen pipeline to run on TPU v6e
- google-smi & tpustat by AI GDE Minho Ryu (Korea): a TPU-oriented status CLI in the style of nvidia-smi and the TPU equivalent of the gpustat workflow
- MegaText by AI GDE Minho Ryu (Korea): a streamlined pretraining framework for LLMs on TPUs (built on JAX, inspired by MaxText)
- flaxchat by AI GDE Taha Bouhsine (US): a minimal, end-to-end LLM training harness for TPU pods (built on JAX/Flax NNX)
- gemma3-vllm-tpu-gke-autoscaling by AI GDE Anubhav Singh (India): a deployment guide covering quota management, capacity planning, model compatibility, and HPA-based autoscaling for vLLM on GKE with TPU.
- Code Auditor by AI GDE Usha Rengaraju (India): LLM-powered code security auditing tool using NVIDIA NIM + free open-source safety stack
TPU vs. GPU
https://medium.com/media/a268b96ca3fb987997e367545008738a/href
GPU vs TPU: Which one to use for Artificial Intelligence? by AI GDE Carlos Alarcon (Colombia) explains criteria for choosing between GPUs and TPUs for ML projects through real-world tests on Colab. It highlights specific use cases such as inference, self-attention, and massive matrix multiplication to help users optimize hardware selection for efficiency and cost.
ML acceleration guide: TPUs vs GPUs by AI GDE Glen Yu (Canada) compares TPUs and GPUs for ML acceleration by detailing architectures, precision types, and XLA’s importance. He also shares a code example to demonstrate performance differences between the hardware types.
Keras
[kinetic doc] Fine-tuning Gemma 4 on TPU with Kinetic by AI GDE Adonai Vera (Colombia) details how to fine-tune Gemma 4 Instruct 26B on a TPU using Kinetic and LoRA for memory efficiency. It outlines the process for environment setup, weight storage in GCS, and performing inference with the fine-tuned model. He also contributed to the Keras ecosystem by adding — reservation flag to kinetic pool. [keras.io] Scaling Context-Aware Two-Tower Music Retrieval via JAX Data Parallelism and Keras 3 on TPUs by AI GDE Rishiraj Acharya (India) introduces a production-ready KerasRS implementation for context-aware music retrieval using a dynamic Two-Tower model and the Yambda dataset.In my Kinetic era — Fine-tuning Gemma 3 to speak Gen Z on a Cloud TPU with one decorator by AI GDE Jigyasa Grover (US) demonstrates supervised fine-tuning for Gen Z style transfer using Gemma 3 1B and TPU v5 Lite. It simplifies deployment to GKE via Kinetic while utilizing Keras Hub/Kaggle for model management.
On-device ML
#Gemma 4 Bringing Multimodal Gemma 4 E2B to the Edge: A Deep Dive into LiteRT-LM and Qualcomm QNN by AI GDE Kartikey Rawat (India) explores the deployment of Gemma 4 E2B on Android devices using LiteRT-LM and Qualcomm QNN for NPU acceleration. It details architectural innovations and engineering changes required for production-ready on-device inference.
Running Gemma 4:E2B on Android: A Minimal Kotlin App
#Gemma 4 Running Gemma 4:E2B on Android: A Minimal Kotlin App (repository) by AI GDE Gabriel Preda (Romania) details a minimal Android chatbot developed in Kotlin using Gemma 4:E2B for fully offline local inference. It outlines key implementation steps such as UI creation, LiteRT-LM integration, and Markdown support.
Cloud

Building a Healthcare Recommender with Keras, Two Towers and Google Cloud by AI GDE Rubens Zimbres (Brazil) shares how he built the Prescription Recommender app, which takes plain language symptoms as input, identifies likely diseases, and suggests medications, diets, and workouts.
Building an AI Agent Mesh with Gemini 3, OpenClaw, and ACPX by Cloud GDE Timothy Olaleke (Portugal) explains how to build an AI agent mesh using Gemini 3.1 Pro, OpenClaw, and ACPX with covering multi-agent orchestration, gateway architecture, and real-world deployment patterns.
ML Research
#Gemma Anthropogenic Regional Adaptation in Multimodal Vision-Language Model by AI GDE Aye Hninn Khine (Thailand) introduces the method to improve the cultural relevance of VLMs in specific regions while maintaining global performance.
#Gemma Investigating Refusal Mechanisms in Gemma 3 Models for Enhanced AI Safety by AI GDE Ruqiya Bin Safi (Saudi Arabia) studies refusal mechanisms in Gemma 3 by isolating the single directional subspace responsible for refusal behavior using vLLM and TPU infrastructure. It explores mechanistic interpretability to modulate model behavior and improve AI safety through controlled experiments and adversarial analysis.
![]()
[Mar-Apr 2026] AI Community — Activity Highlights and Achievements was originally published in Google Developer Experts on Medium, where people are continuing the conversation by highlighting and responding to this story.

