Introducing TrGLUE: First Non-Translate Turkish NLU Benchmark Ever
Turkish NLP has momentum — but consistent evaluation still lags behind English. TrGLUE is our attempt to fix that: a compact, human‑verified benchmark that covers core understanding skills in Turkish across morphology‑rich, register‑diverse text. Think of it as a sanity check for Turkish models: can they parse sentence acceptability, detect sentiment, recognize paraphrases, match questions to answers, infer entailment, and judge similarity — without getting tripped by Turkish‑specific cues like negation particles, evidential past, or case‑marked entities?

Why Turkish benchmarking is different
If you work with Turkish every day, you know its generosity with morphology is both a superpower and a trap. A single lemma can blossom into a long surface form with case, possession, tense/aspect, evidentiality, and polarity markers attached — sometimes several at once. That richness expands the space of possible inputs, but it also makes benchmarks more brittle: a tiny clitic can flip meaning, and a case suffix can turn a near‑duplicate into a different relation entirely.
On top of morphology, domain and register matter. News headlines compress syntax and drop function words; forums add slang and particles; academic text stretches sentences with stacked modifiers. When you pull tasks from different sources, labels can drift — especially if they originated in English and were translated into Turkish without acknowledging these shifts.
A quick example illustrates the point. Consider “Görüşme iptal edildi mi?” versus “Toplantı hala planlandığı gibi mi?” To an English‑trained eye, both look like yes/no questions about an event’s status. But the polarity cues differ, and “görüşme” vs “toplantı” are not interchangeable in context; a naive transfer for a paraphrase or duplicate‑question task can easily mislabel the pair. This is the kind of subtlety we wanted our pipeline to respect.
TrGLUE Benchmark
As a result, Turkish NLP needed its own benchmark for some time. Though there are translated datasets of GLUE present on Github repos, none of them captures Turkish morphology, syntax and semantics. Consequently, we proudly present TrGLUE — the first non-translated Turkish NLU benchmark ever.
Below, we introduce each task, what it measures, why it’s tricky in Turkish, how we evaluate it, and a tiny example so you can feel the difference.
Task catalog and task explanations are as follows:
- TrCoLA — Acceptability (grammatical well‑formedness)
- What it measures: Whether a sentence is acceptable Turkish (syntax/morphology consistent with native usage).
- Why it’s tricky: Agglutinative morphology and clitics produce long forms; a single missing harmony or suffix stacking error can flip acceptability.
- Tiny example:
- Accept: “Kitapları masanın üzerinde bıraktım.”
- Reject: “Kitapları masa üzerinde bıraktım.” (case mismatch; should be “masanın üzerinde”)
- Data source: Linguistic books
2. TrSST‑2 — Sentiment (binary)
- What it measures: Sentence‑level sentiment polarity in Turkish.
- Why it’s tricky: Negation particles (değil, -ma/-me), sarcasm markers, and modality particles can invert polarity.
- Tiny example:
- Pozitif: “Film beklediğimden çok daha iyiydi.”
- Negatif: “Fragmanı güzeldi ama film hiç olmamış.”
- Data source: Movies
3. TrMRPC — Paraphrase detection
- What it measures: Whether two sentences express the same meaning.
- Why it’s tricky: Near‑synonyms differ by register; case marking and light‑verb constructions shift argument structure; evidential -miş can soften assertions.
- Tiny example:
- Equivalent: “Toplantı yarına ertelendi.” vs “Toplantıyı yarına aldılar.”
- Not equivalent: “Toplantı iptal edildi.” vs “Toplantı yarına ertelendi.”
4. TrQQP — Duplicate question detection
- What it measures: Whether two user questions ask the same thing.
- Why it’s tricky: Word order is flexible; particles (“mi”, “ya”), and politeness/register can mask duplicates; case‑marked entities change intent.
- Tiny example:
- Duplicate: “AÖF kayıt tarihi ne zaman?” vs “Açıköğretim kayıtları hangi tarihte başlıyor?”
- Non‑duplicate: “ALES puanı kaç yıl geçerli?” vs “YDS puanı kaç yıl geçerli?”
- Data source: Turkish news
5. TrSTS‑B — Semantic textual similarity
- What it measures: Real‑valued similarity of sentence pairs (semantic closeness, not exact paraphrase).
- Why it’s tricky: Derivational morphology and aspect/evidentiality change nuance; lexical overlap is a poor proxy in Turkish.
- Tiny example (gold ~4.0): “Yağmur yarın sabah etkili olabilir.” vs “Yarın sabah yağış bekleniyor.”
- Data source: Translate of original dataset, then curated by humans
6. TrQNLI — Question‑Natural Language Inference
- What it measures: If a sentence contains the answer to a question (entailment vs non‑entailment).
- Why it’s tricky: Case marking affects role interpretation; pro‑drop subjects and free word order complicate retrieval heuristics.
- Tiny example:
- Premise: “Konser biletleri dün satışa çıktı.”
- Question: “Biletler satışa sunuldu mu?”
- Label: entailment.
- Data source: Turkish Wiki
7. TrMNLI — Natural Language Inference (matched/mismatched)
- What it measures: Entailment, contradiction, or neutral relation between premise and hypothesis across domains.
- Why it’s tricky: Negation particles, evidentiality, and light‑verb idioms frequently cause label flips; domain shifts (news, forums) stress robustness.
- Tiny examples:
- Entailment: P: “Ankara bugün yağmurlu.” H: “Bugün Ankara’da yağış var.”
- Contradiction: P: “Toplantı iptal edildi.” H: “Toplantı planlandığı gibi yapılacak.”
- Neutral: P: “Ekip yeni bir özellik duyurdu.” H: “Kullanıcılar bu özelliği sevdi.”
- Data source: Fairy tales, news, forum chats and much more genres.
8. TrRTE — Recognizing Textual Entailment (binary)
- What it measures: Classic binary NLI with shorter, formal texts.
- Why it’s tricky: Compact sentences amplify the effect of particles and morphology; subtle lexical choices change labels.
- Tiny example:
- P: “Tüm başvurular çevrimiçi yapılır.” H: “Fiziksel başvuru kabul edilmez.” → entailment.
- Data source: News and academical writings.
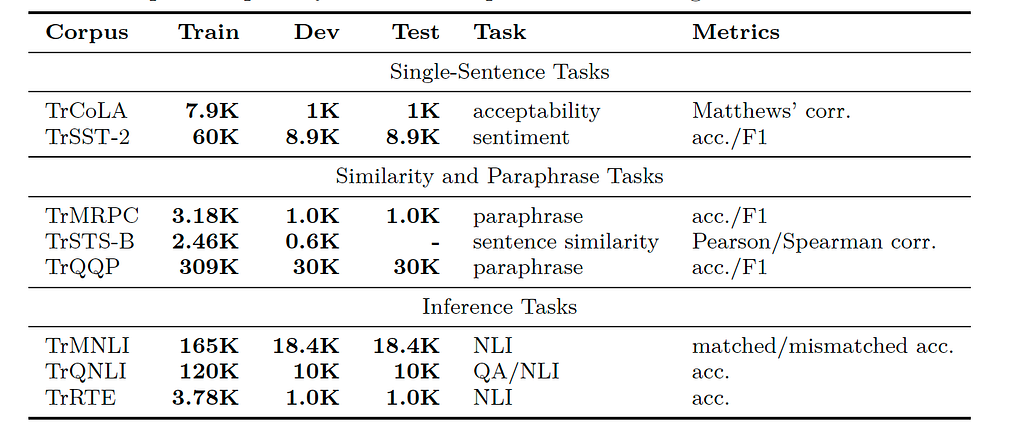
Here’s a concise summary of the tasks and dataset sizes:
Coming to the task difficulties, there are certainly Turkish‑specific pitfalls to watch across tasks. Here are some for you:
- Negation and polarity: değil, -ma/-me, yok, hiç; a single morpheme flips labels.
- Evidential past (-miş): weakens commitment, often shifting entailment toward neutral.
- Case‑marked named entities: İstanbul’a/İstanbul’dan change roles; careless matching breaks paraphrase/QQP.
- Light‑verb constructions: karar vermek, başvuru yapmak; semantics live in the nominal head, not the verb.
- Free word order and pro‑drop: surface heuristics fail; models must track roles via morphology, not just position.
With the landscape clear, the next questions are: how did we build TrGLUE without translation artifacts, how do we keep it reliable at scale, and what numbers should you expect out of the box? Here’s the pipeline, the quality controls that catch most issues, and a baseline snapshot to orient your experiments.
How we built TrGLUE (LLM-assisted, human-verified)
We started from first principles: choose permissive, diverse sources; generate or validate labels with an LLM under strict constraints; and then have humans verify and adjudicate. The goal wasn’t to replace human judgment but to amplify it, letting the model do the tedious formatting while people decide the hard linguistic calls.
Source selection came first. We prioritized datasets with clear, permissive licenses and a spread of domains so that a model tuned to newswire Turkish wouldn’t ace the benchmark by style alone. Most of our data came from large-scale and open source Turkish corpus [BellaTurca](https://huggingface.co/datasets/turkish-nlp-suite/BellaTurca), including newspaper articles, academical papers, forum chats and more genres from more subsets. You can read more about BellaTurca in [this Github blog post](https://turkish-nlp-suite.github.io/2025/10/05/bellaturca/).
Next step would be assigning coarse labels to instances. Here we made 2 legs in parallel, the first leg is to generate labels with semantic similarity methods (please refer to the research paper for all the details) and the second leg is to prompt our LLM of choice, [Snowflake Arctic](https://www.snowflake.com/en/product/features/arctic/) — a truly free LLM. Finally we collected the instances where those 2 labels do not agree. Here’s an example prompt, prompt we used to generate Arctic labels for QNLI:
Hello, I’m generating a question answering corpus for Turkish in the same fashion
of SQuAD. I’ll send a paragraph as input and I’d like you to output question and
answer pairs. The original dataset has answers with numerical entities, proper
nouns, noun phrases, adjectives and adverbs, please make sure we have them as
well. Make sure to use when, who, how, how many, how much etc. in the questions.
Also use paraphrasing in questions. Additionally, I wanna include verb phrase
answers , specific to Turkish syntax e.g. ’Atatürk bu ülkeyi büyük zorluklarla
savaşarak kurdu. - Atatürk Türkiye’yi ne şekilde kurdu? - büyük zorluklarla’. I’ll
input the context, you output 10 question-answer-index triplets. Keep in mind
that SQuAD is a span extractive type question answering, hence the answer must
come from the paragraph and the index should mark the start of the answer span.
Please keep the casing of answer as in the paragraph. When giving the answers,
take Turkish morphology in the account. The answer may or may not contain a
suffix depending on the question. Separate output triplets with a newline, also
use the | character as a separator between the triplet. Like this: CONTEXT:
Cumhuriyet Atatürk ve silah arkadaşları tarafından büyük mücadelelerden sonra
1923’te ilan edildi. OUTPUT: Cumhuriyet ne zaman ilan edildi? | 1923’te | 78
Türkiye Cumhuriyeti’nin kurulma tarihi nedir? | 1923 | 78
Cumhuriyeti kimler ilan etti? | Atatürk ve silah arkadaşları | 11
Cumhuriyet ne şekilde kuruldu? | büyük mücadelelerden sonra | 50
INPUT:
The final step is to feed those instances to the human annotation, our backbone of dataset construction. Each batch of data received two annotators and a concise guideline sheet describing label definitions, Turkish‑specific pitfalls, and examples with rationales. Disagreements went to adjudication, where we required a written rationale for the final call. This forced us to confront ambiguous cases rather than silently compromise, and it produced a small library of “gotcha” examples we now use for training annotators and testing models.
Benchmark results
After all the curation our datasets are ready to use 😊 We’re offering an ofiicial TrGLUE script in [our Github repo](https://github.com/turkish-nlp-suite/TrGLUE), it’s almost the same with the official GLUE script. You can run all the tasks with run.sh , as well as you can run a single task with run_single.sh . These bash scripts simply evoke the Python script, here’s a single run with CoLA:
python3 run_trglue.py
--model_name_or_path dbmdz/bert-base-turkish-cased
--task_name cola
--max_seq_length 128
--output_dir berturk
--num_train_epochs 5
--learning_rate 2e-5
--per_device_train_batch_size 128
--per_device_eval_batch_size 128
--do_train
--do_eval
--do_predict
With the official scripts [BERTurk](dbmdz/bert-base-turkish-cased) achieves the following results:
| Task | Metric(s) | Score |
|---------|--------------------------------|-------------|
| TrCoLA | Matthews corr. | 42.0 |
| TrSST-2 | Accuracy / F1 | 87.4 / 91.3 |
| TrMRPC | Accuracy / F1 | 74.4 / 72.7 |
| TrSTS-B | Pearson / Spearman (dev) | 71.3 / 69.9 |
| TrQQP | Accuracy / F1 | 95.4 / 94.3 |
| TrMNLI | Matched / Mismatched accuracy | 87.9 / 90.8 |
| TrQNLI | Accuracy | 90.6 |
| TrRTE | Accuracy | 92.2 |
After dissecting the results, we found out CoLA is an inherently difficult task. We even evaluated some multilingual LLMs on this task and guess what they were not very successful either. Our research paper includes results of CoLA for your curiosity.
Dear readers, thank you for spending your time with this work and for pushing Turkish NLP forward alongside us. We hope TrGLUE proves useful in your experiments, and we’d love to hear where your models shine — and where they stumble. Until next time, stay curious and keep sharing your findings.
Resources
[Arxiv Preprint]( https://www.arxiv.org/abs/2512.22100) [HF repo](https://huggingface.co/datasets/turkish-nlp-suite/TrGLUE) [Github repo](https://github.com/turkish-nlp-suite/TrGLUE) [Github blog post](https://turkish-nlp-suite.github.io/2025/12/19/trglue/)Special thanks
goes to Google Cloud TPU program (where I ran the benchmarking scripts) and Snowflake for offering a truly liberated LLM, Arctic.
![]()
Introducing TrGLUE: First Non-translate Turkish NLU Benchmark Ever was originally published in Google Developer Experts on Medium, where people are continuing the conversation by highlighting and responding to this story.


