
We need search engines with AI
Last week I had a strange problem at work to tackle. The business head wanted to know. How many Jiras the developers have worked on.
And what commits, code they have done.
While this sounds strange. This activity of searching and searching led me to discovery of a common problem. Let’s start here with the story.
If you wanted to know how many tickets, you have worked with and how many codes and commits are written per each ticket in the last two weeks. This is a pretty simple way to check how productive you have been. How would you go ahead and do that?
The step is as follow:
- Go to your ticketing system (Jira, You Track, Trello, etc.) and search by username.
- Narrow down the search to the last two weeks.
- Go to GitHub and search your commits in the previous two weeks.
- Manually cross-check which commit is for which Jira.
Wow, you’ve spent 120 minutes of your life searching through two different platforms. Just to get some productivity metrics. And in the end, you’re getting some links to stuff. And if time is money, then this is what the whole process looks like:

You want answers, not links to webpages, Jiras, or GitHub commits. So, how can you solve this problem? We already have search providers in all the websites. We have Large Language Models and ChatGPT introduced its enterprise version. Is there a way to combine them both?
Open-Source Search Engine Meets AI – Swirl Search 🌌
I recently discovered this open-source search engine, Swirl Search. And it exactly does what I wanted back them. Search through multiple platforms, and then generate the data I want via ChatGPT (or any LLM).
It’s an open-source search engine that combines many data sources and returns a single answer via it’s UI.
Now, when you take that output and send it to any Large Language Model (let’s say ChatGPT’s API). You get answers that you want within seconds instead of minutes. So, LLMs are combined with multiple data sources via Swirl, and you get what you want.
Swirl becomes a search bar of search bars 😂. You can say it’s one search bar to rule them all. And it basically searches everything at once. The best part is that it’s open source, in Python, and doesn’t require re-indexing. Meaning no extra database is required.
I find this idea to be purely genius and something that we need. With the growing data and databases.

So, let’s dive deep and see what Swirl is about.
What is Swirl Search? 🤔
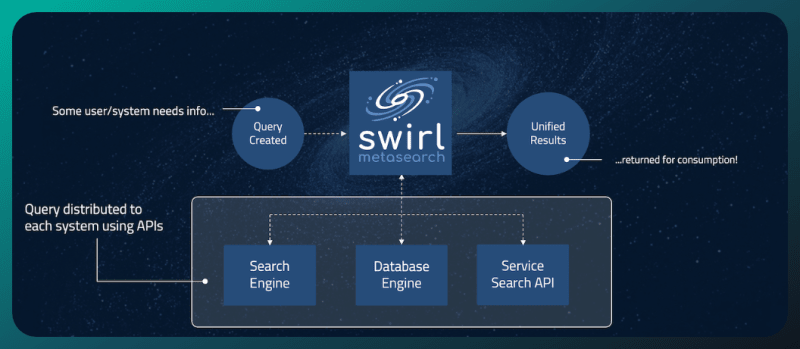
Swirl search is an open-source search tool built on the Python/Django stack. But what sets Swirl apart from other search tools? It’s the ability to adapt and distribute user queries to virtually any platform with a search API.
This includes search engines, databases, NoSQL engines, cloud services, and more. But Swirl doesn’t stop there. Once it retrieves the data, it employs Artificial Intelligence, specifically Large Language Models (LLMs), to re-rank and present the most relevant results. This is done without the need to extract or index any data, ensuring a seamless and efficient user experience.
Swirl builds on the power of Large Language Models. 💪
One of the standout features of Swirl is its use of LLMs through Swirl’s Metapipe. Large Language Models have taken the tech world by storm, showcasing their ability to understand and generate human-like text based on the information they’ve been trained on. By integrating LLMs into its framework, Swirl can provide more accurate, relevant, and context-aware search results. This is a significant leap from traditional search methods that often return vast amounts of irrelevant data.
Below is a screenshot of Retrieval Augmented Generation using Swirl. While searching for persons or lesser known data any LLM can generate generic stuff. But using Swirl and Multi-platform search you can find information and send it to your Language Model for better answers and insights.

While searching for Sid Probstein, ChatGPT gave random answers at first. But once we queried the transcript of a podcast sent via an outlook mail, it returned some amazing answers. Imagine doing this with your own data. Which will increase your productivity by a huge margin.
Integration Capabilities: Connecting with Multiple Platforms 🚀
Swirl’s strength lies not just in its advanced search capabilities but also in its extensive integration options. It offers OAuth2 support for Microsoft 365, ensuring secure access to data. Moreover, Swirl seamlessly integrates with enterprise services such as Atlassian Jira and Confluence, JetBrains YouTrack, HubSpot, and many others. Users can search multiple platforms and services with a single query, saving time and effort.
And with the recent connection to ChatGPT, you can take in the output from the search and send it to ChatGPT for some amazing answers with references. And this feature is what I liked the most about it.

Current and Upcoming Platforms available for Search using Swirl
Saving Time and Getting the Answers from Multiple Data Sources 📚
Swirl can search through multiple data sources. If it has an API, It’s searchable through Swirl.
Connect Outlook Emails, Notion, Teams Chat, and much more together. And it’s all safe and no data is collected. This is the best part of having an open-source engine.
By using Swirl search alongside generative AI language models, businesses, startups, individual creators can efficiently feed relevant data to ChatGPT, enabling users to easily derive insightful answers directly from application data.
So, if your company, startup has multiple data sources, and you want to retrieve data and generate insights from all of them. Then by using Swirl you can save time and money. Get the work done faster. Be more productive 🔥.
Check the Project on GitHub and Contribute 🌟
The best part of the Swirl is its open source. And they’re looking for contributors, community members and enthusiasts. My experience with the team has been positive.
With the upcoming Hacktoberfest, this can be a great new project to get started with.
If you like creating a search engine that queries multiple data from multiple sources altogether. Then let’s Dive into the future of search with Swirl. Check out our GitHub repository.
Give it a Star 🌟 and join the Slack. Let’s shape the future of data retrieval together!

swirlai
/
swirl-search
Swirl queries anything with an API then uses spaCy to re-rank the unified results without copying any data! Includes zero-code configs for Apache Solr, ChatGPT, Elastic Search, OpenSearch, PostgreSQL, Google BigQuery, RequestsGet, Google PSE, NLResearch.com, Miro, Microsoft 365, HubSpot, Atlassian, YouTrack, GitHub & more!
Swirl Metasearch 2.5.1
![]()
![]()
Swirl Metasearch adapts and distributes user queries to anything with a search API – search engines, databases, noSQL engines, cloud/SaaS services, etc. – and uses AI (Large Language Models) to re-rank the unified results without extracting or indexing anything. It includes OAuth2 support for Microsoft 365 alongside integration with enterprise services such as Atlassian Jira and Confluence, JetBrains YouTrack, HubSpot and more.
Using the Galaxy UI, knowledge workers can systematically review the best results from all configured services including Apache Solr, ChatGPT, Elastic, OpenSearch, PostgreSQL, Google BigQuery, plus generic HTTP/GET/POST with configurations for premium services like Google’s Programmable Search Engine, Miro and Northern Light Research.

Built on the Python/Django stack, Swirl is intended for use by anyone who wants to solve multi-silo search problems without moving, re-indexing or re-permissioning sensitive information.
Try Swirl Now In Docker
…
![[ml-story]-exploring-the-future-of-text-generation:-a-deep-dive-into-vertex-ai-using-jupyter…](https://prodsens.live/wp-content/uploads/2023/09/14631-ml-story-exploring-the-future-of-text-generation-a-deep-dive-into-vertex-ai-using-jupyter-110x110.png)


