Fine-tuning language models has become a powerful technique for adapting pre-trained models to specific tasks. This article explores how to fine-tune Google’s Gemma-2B model using QLoRA (Quantized Low-Rank Adaptation) to enhance its performance in generating Python code.
What is Gemma-2B?
Gemma-2B is an open-source language model developed by Google. It is designed to assist developers in writing Python code more efficiently. However, like any pre-trained model, it may only be ideally suited for some use cases. Fine-tuning allows us to tailor Gemma-2B to specific tasks or domains.
The Role of QLoRA
QLoRA is a technique that combines quantization and low-rank decomposition during fine-tuning to reduce the amount of memory required to fine-tune the model. Here’s how it works:
- Quantization: We quantize Gemma-2B’s weights to reduce memory and computation requirements. This involves representing weights with fewer bits, which can lead to faster inference.
- Low-Rank Decomposition: Instead of updating Gemma-2B’s entire weight matrix during fine-tuning, QLoRA decomposes it into smaller matrices. These “update matrices” adapt to new data while minimizing overall changes. The original weight matrix remains frozen.
- Combining Adapted and Original Weights: QLoRA combines the original and adapted weights to produce the final results.
Fine-Tuning Gemma with QLoRA
For this demo, we will be using Google Colab to fine-tune. First, make sure that all the below packages are installed by running the !pip command and importing them.
!pip install peft datasets transformers trl accelerate bitsandbytes -q
import torch
import json
from transformers import AutoModelForCausalLM, AutoTokenizer, BitsAndBytesConfig, TrainingArguments
from peft import LoraConfig, PeftModelForCausalLM
from trl import SFTTrainer
from datasets import Dataset
from huggingface_hub import notebook_login
The use of the packages is as follows:
- peftfor running LoRA
- datasets to manage our dataset
- transformers to download Gemma
- trlto manage the training process
- bitsandbytesand accelerate for the quantized model
- The -q argument makes the installation process run quietly (printing with as minor status as possible).
Ensure you are running the colab with a GPU. Otherwise accelerate will throw an error.

To download Gemma, we must first make an huggingface account if we don’t have one. Then, accept their terms of use on their page: https://huggingface.co/google/gemma-2b-it. Afterward, we can go to our settings > Access Tokens and make a new token. We will use this token to authenticate our Colab session so we can download Gemma. We then run thenotebook_login() function and put the newly generated huggingface token in the field.
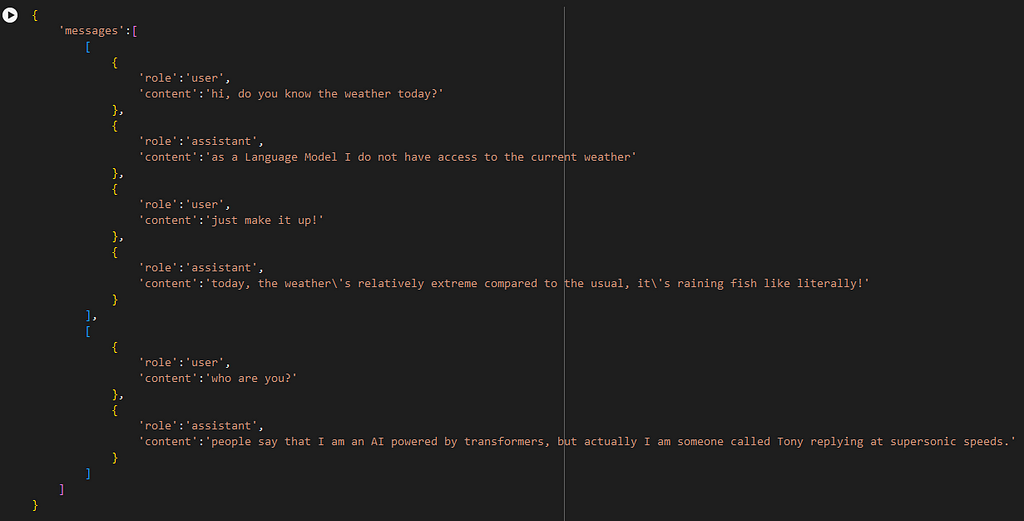
Next, we should load the dataset. You can use a custom dataset; the format should be chatml json, like the one below. It should start with the user role and end with the assistant role without any consecutive user or assistant role messages.
Then, we can load the dataset as a dictionary and turn it into a Dataset
save_path = "https://medium.com/PATH_TO_YOUR_DATASET/"
dataset_train_name = 'EN-train'
dataset_val_name = 'EN-val'
file_name_train_chatml = f"{dataset_train_name}_chatml.json"
file_name_val_chatml = f"{dataset_val_name}_chatml.json"
with open(save_path + file_name_train_chatml, 'r') as f:
dataset_train = Dataset.from_dict(json.load(f))
with open(save_path + file_name_val_chatml, 'r') as f:
dataset_val = Dataset.from_dict(json.load(f))
Next, we set up the quantization config to load the model in 4 bits with the nf4 quantization method that will calculate in float 16 precision. With that config, we’ll download the model and its tokenizer.
bnb_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_quant_type="nf4",
bnb_4bit_compute_dtype=torch.float16,
)
tokenizer = AutoTokenizer.from_pretrained("google/gemma-2b-it")
tokenizer.padding_side = 'right'
model = AutoModelForCausalLM.from_pretrained(
"google/gemma-2b-it",
device_map="auto",
quantization_config=bnb_config
)
We’ll set up the LoRA config with a rank of 16 and an alpha of 16. If we want the model to learn new knowledge, we can increase the alpha to maybe 2x the rank, but we might need a lot of data to prevent the model from overfitting. If we want to slightly change the output style of the model, we can set the alpha to about half of the rank.
peft_config = LoraConfig(
lora_alpha = 16,
lora_dropout=0.1,
r=16,
task_type='CAUSAL_LM'
)
After this, we can configure the training. For this case, we’ll set the per_device_train_batch_size to 2 and gradient_accumulation_steps to 16. This means that one step will contain 32 (1 * 2 * 16) rows of training data since the normal colab only provides 1 GPU device. We limit the max_steps to 100 so the training doesn’t take too long. If we calculate it, the training will go through 3200 rows of the training data. If we don’t set the max_steps the training will go through 1 epoch, which is the whole dataset one time. We’ll also want to save checkpoints every 20 steps by setting the save_steps parameter 5 times over the entire training process since 100 ÷ 20 is 5.
We’ll pass the peft_config and the training arguments into the SFTTrainer (supervised fine tuning trainer) and set the neftune_noise_alpha to 5 to increase fine tuning performance by adding noise to the embedding layer. Then we run the trainer.train() method to start training.
training_arguments = TrainingArguments(
output_dir = "https://medium.com/PATH_TO_TRAINING_OUTPUT",
evaluation_strategy="steps",
logging_strategy="steps",
lr_scheduler_type="constant",
logging_steps=20,
eval_steps=20,
save_steps=20,
per_device_train_batch_size=2,
per_device_eval_batch_size=2,
gradient_accumulation_steps=16,
eval_accumulation_steps=16,
num_train_epochs=1,
fp16=True,
group_by_length = True,
optim="paged_adamw_32bit",
max_steps = 100
)
trainer = SFTTrainer(
model,
tokenizer=tokenizer,
train_dataset=dataset_train,
eval_dataset=dataset_val,
peft_config=peft_config,
neftune_noise_alpha=5,
max_seq_length=500,
args = training_arguments
)
trainer.train()
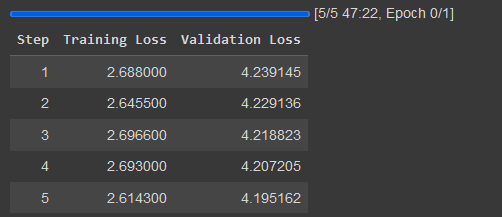
The 5 checkpoints will be saved output_dir with the above configuration, but if we want to ensure that we saved the model, we can run this code. This code will save the model’s adapters.
trainer.model.save_pretrained(“/SAVE_DIR”)
We can load the model adapters with this code, the model being the base pretrained Gemma model.
finetuned_model = PeftModelForCausalLM.from_pretrained(model=model, model_id="https://medium.com/SAVE_DIR")
Let’s load another instance of Gemma and compare it with the fine tuned model.
model_2 = AutoModelForCausalLM.from_pretrained(
"google/gemma-2b-it",
device_map="auto",
quantization_config=bnb_config
)
messages=[
{
'role':'user',
'content':'Who is Francesco Lelli?',
}
]
input_ids = tokenizer.apply_chat_template(messages, add_generation_prompt=True, tokenize=True, return_tensors="pt").to("cuda")
# print(input_ids)
outputs_finetuned = finetuned_model.generate(input_ids=input_ids, max_new_tokens=1024, do_sample=False)
outputs = model_2.generate(input_ids=input_ids, max_new_tokens=1024, do_sample=False)
print("finetuned: " + tokenizer.decode(outputs_finetuned[0]).split('modeln')[-1])
print("normal : " + tokenizer.decode(outputs[0]).split('modeln')[-1])
finetuned: Francesco Lelli is an entrepreneur and angel investor focused on technology and healthcare startups. He is the co-founder and CEO of HealthTech Startup Studio, a venture builder for healthcare startups, and the founder of HealthTech Startup Weekend, an annual event for healthcare startups. He is also a mentor and advisor to numerous startups and healthcare companies.
normal: Francesco Lelli is an entrepreneur and angel investor focused on early-stage technology companies in the healthcare, consumer, and enterprise sectors. He is the founder and CEO of Lelli Founders, a venture studio that invests in disruptive startups with the potential to revolutionize industries.
Fine-tuning language models like Google’s Gemma-2B with advanced techniques such as QLoRA offers a promising avenue for enhancing model performance in specific domains, such as Python code generation.
The comparison between the fine-tuned model and the original Gemma-2B model illustrates the potential of fine-tuning; it can significantly alter the model’s outputs, making them more relevant and tailored to specific queries. This capability allows developers and researchers to create highly specialized models without extensive computational resources.
As AI and machine learning evolve, techniques like QLoRA will become increasingly important for making the most of pre-trained models. Whether you’re a developer looking to enhance code generation tools, a researcher aiming to push the boundaries of what’s possible with language models, or simply an enthusiast curious about the latest in AI, fine-tuning with QLoRA offers a path to achieving more with less.
In conclusion, adapting and enhancing language models is an exciting AI research and development frontier. By embracing these techniques, we can unlock new levels of performance and efficiency, paving the way for more intelligent and responsive AI systems.
![]()
Fine-tuning Gemma with QLoRa was originally published in Google Developer Experts on Medium, where people are continuing the conversation by highlighting and responding to this story.




