![[ml-story]-unlock-your-ideas-with-gemini:-hands-on-guide](https://prodsens.live/wp-content/uploads/2024/04/21946-ml-story-unlock-your-ideas-with-gemini-hands-on-guide-550x309.jpeg)
In March 2024, Google’s Gemini models marked their first quarter in action and since their release, they have been the new talking point.

While Generative AI isn’t something new, let’s quickly have a look at how Google’s language models have gradually evolved over the years.
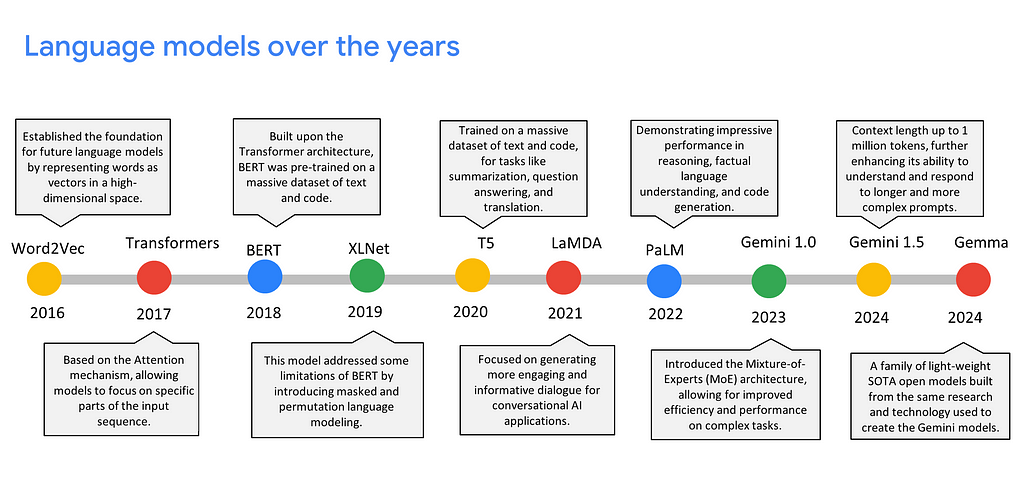
Word2Vec laid the foundation for the spotlight that today’s language models, including Gemini and other state-of-the-art (SOTA) models, currently enjoy.
In this blog, I will guide you through the Gemini models and illustrate their practical applications across a range of tasks. So, just sit tight, chill out, and enjoy learning.
Gemini
Gemini is a family of the largest, multi-modal AI models developed by Google DeepMind. Trained on a large dataset of text, code, images, videos, audio, etc., it can perform various complex tasks such as writing a summary of a big piece of text, detecting content in an image/video, documenting a large codebase, identifying bugs, and much more.
Gemini comes in three distinct versions, each tailored to specific capabilities and sizes: Ultra, Pro, and Nano.
- Gemini Ultra 1.0: The largest and most capable model.
- Gemini Pro 1.0: The top-performing model for tasks primarily involving textual data.
- Gemini Pro 1.5: Exhibits strong performance across a wide range of tasks, including handling data in the form of images, videos, audio, code, etc.
- Gemini Nano: The most efficient model designed for on-device tasks.

Architecture of Gemini
While detailing the precise architecture isn’t possible, the Gemini 1.5 model relies on Transformers and incorporates a Mixture of Experts (MoE) to handle a diverse range of tasks.
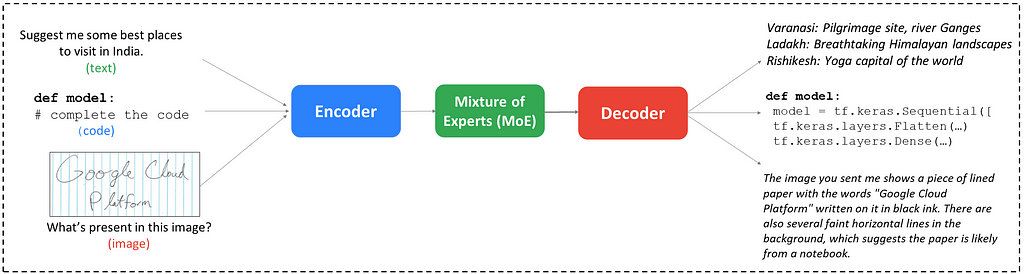
Let’s break it down into simple components.
Encoder: Takes input formats like text, code, images, or audio and converts them into a common internal representation that the decoder can understand.
Mixture of Experts: This component employs a network of smaller, specialized models (“experts”) instead of a single, monolithic model. The input is routed to the most relevant expert based on its characteristics for improved efficiency and performance.
Decoder: Based on the encoded information and the specific task at hand, the decoder generates outputs in different modalities, such as text, code, or translated languages.
Based on the data it receives, Gemini tailors its task execution. For instance, in the aforementioned architecture diagram, the third input consisted of an image featuring handwritten text that reads “Google Cloud Platform” accompanied by the prompt, “What’s present in this image?”

This is an image-to-text task where Gemini executed Optical Character Recognition (OCR) to recognize the content within the image. It not only accurately identified the handwritten text but also provided additional details, such as recognizing that the background was a paper from a notebook.
Benchmarks of Gemini 1.5
As an upgrade to Gemini 1.0, the Gemini 1.5 Pro model demonstrates enhanced capabilities with a significantly larger context window — increasing from Gemini 1.0’s 30,720 to an impressive 10,48,576, and it can handle up to 1 million tokens.
1 million tokens? How much is that?
That is indeed a substantial amount of data. To provide a sense of scale across various data types, this equates to videos lasting up to 1 hour, audio spanning up to 11 hours, and approximately 30,000 lines of code.
For a deeper comprehension of benchmarks and technical details, check out the official blog.
Now that you have an understanding of Gemini’s potential, let’s take a hands-on approach by engaging in practical experiments with this powerful model.
I. Gemini 1.0 Pro on Colab
This segment will illustrate the utilization of the Gemini API in your Colab notebooks.
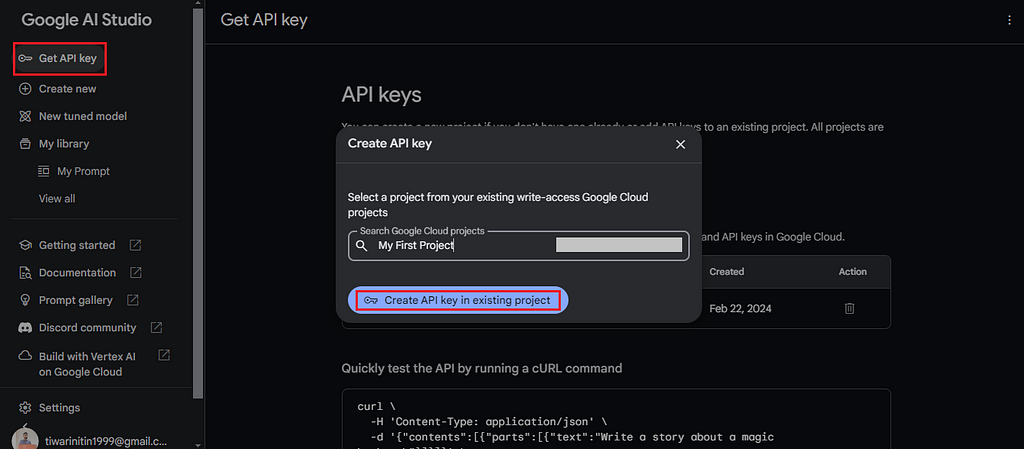
Step 1: Create an API key on Google AI Studio.
Step 2: Open a new notebook on Google Colab.
You have the option to begin from scratch by following this blog step-by-step or jump right in using this Colab notebook as a quick guide.
# Install the Generative AI SDK.
!pip install -q -U google-generativeai
# Import libraries.
from google.colab import userdata
import google.generativeai as genai
from PIL import Image
# Configure the API key (you can configure the API key in Colab Secrets).
API_KEY = userdata.get('gemini')
genai.configure(api_key=API_KEY)
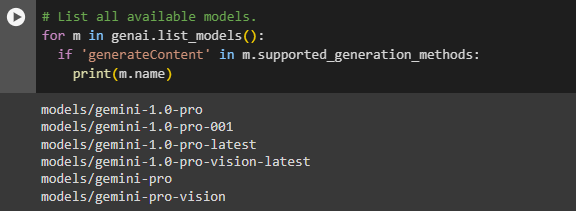
# List all available models.
for m in genai.list_models():
if 'generateContent' in m.supported_generation_methods:
print(m.name)
# Configure the model.
model = genai.GenerativeModel(model_name='gemini-pro')
# Give the prompt.
prompt = "Suggest some best places to visit in India."
# Get response.
response = model.generate_content(prompt)
print(response.text)
Prompt: “Suggest some best places to visit in India.”
Here’s the response for the above prompt, and that’s pretty decent.

Now, let’s take another example, this time with an image and a prompt using the Gemini Pro Vision model.
# Configure the model.
model = genai.GenerativeModel(model_name='gemini-pro-vision')
# Load the image (you will need to upload an image on Colab).
img = Image.open('/content/image.jpg')
# Display the image.
img
prompt = "Identify the place from the image."
# Give the input image and prompt, get response.
response = model.generate_content([prompt, img], stream=True)
response.resolve()
print(response.text)
Prompt: “Identify the place from the image.”


This photo was taken during my visit to Jakarta, Indonesia, at the National Monument (Monas), and Gemini has yet again answered it correctly.
Feel free to experiment with a variety of prompts, such as generating code, extracting small texts from image, summarizing a blog, or even solving a math problem.
II. Gemini 1.5 Pro on Google AI Studio
Now, let’s delve into additional possibilities with Gemini, tackling more complex tasks.
Note: As of February 2024, Gemini 1.5 Pro is currently available in a limited preview on Google AI Studio to certain users. Join the waitlist to get access.
Step 1: Open Google AI Studio and select the Gemini 1.5 Pro model.
Let’s try some experiments with files and videos. I have a PDF of a Class IV History textbook with around 98 pages. The book is about the life of Chhatrapati Shivaji Maharaj and includes images, text, questions and answers, along with some tables.

On page 70 of the textbook, I found a tabular data which describes the council of eight ministers who managed different portfolios.

Let’s pose a question to Gemini based on this table. The PDF file contains 41,382 tokens.
Prompt: In the council of eight ministers, who looked after the department of Defence? What was their designation in Hindi?
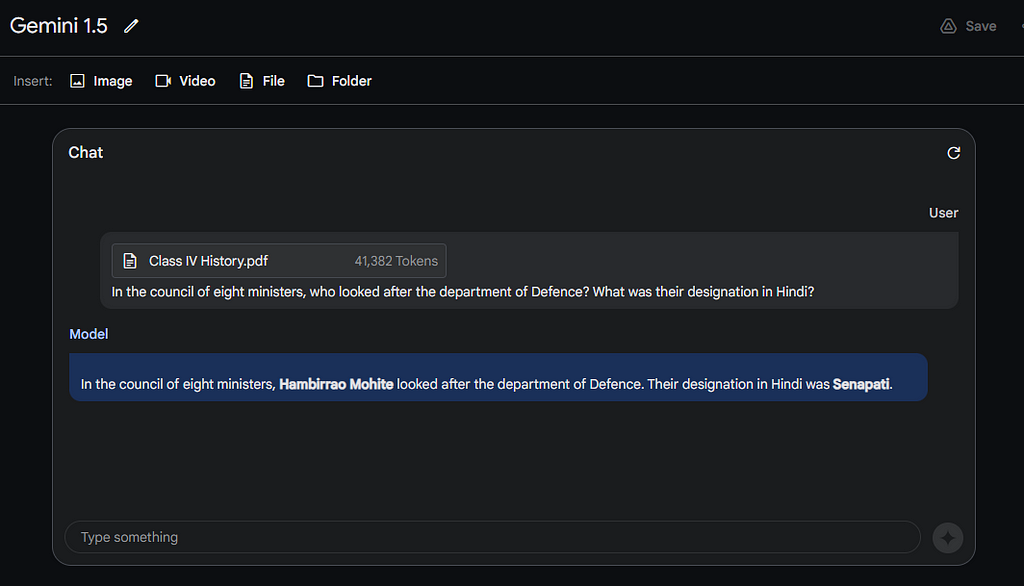
That’s an accurate response. The model looked at all 70 pages and correctly took out the information from the table.
Alright, let’s try another query. On page 67, there’s a picture showing Shivaji Maharaj inspecting the navy.

Prompt: What’s happening in the image at Page 67 of the textbook?
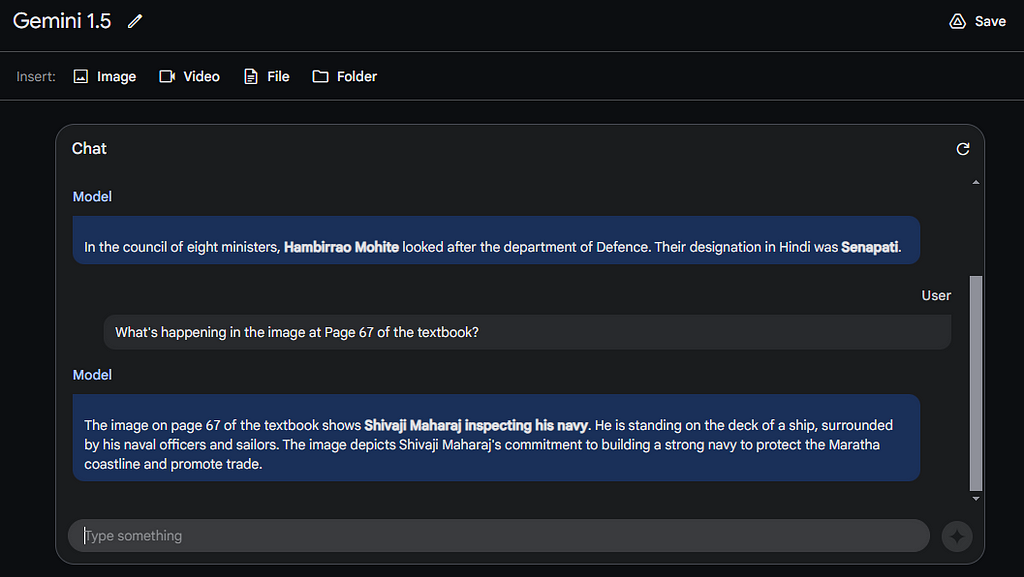
I’m really amazed with the response how Gemini 1.5 has described the image in detail. It’s noteworthy that the image isn’t even a real photograph but rather an animated depiction and yet the result was accurate.
Now, let’s attempt an even more intricate example. I have saved a 06:28 minute video clip of the opening scene from “The Godfather”, one of the greatest movies of all time that I’m truly obsessed with. 🙂
https://medium.com/media/4a3ea1d4aaae34d5f61456e1b345459d/href
Once again, for context, the clip revolves around Amerigo Bonasera seeking justice from Don Vito Corleone on his daughter’s wedding day. The token size of this video clip is 1,02,044, signifying a substantial amount of information indeed.
Prompt: Identify the name of the movie from the clip.
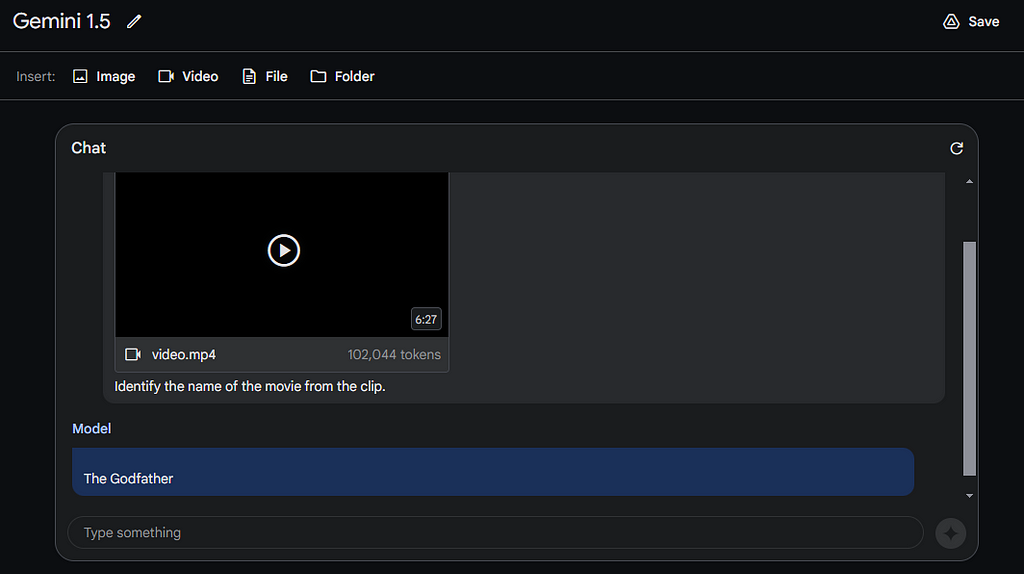
That’s absolutely correct response indeed — The Godfather. Now, let’s explore another question. This time, let’s inquire about the specifics of what is happening in the scene.
Prompt: What’s happening in the clip?
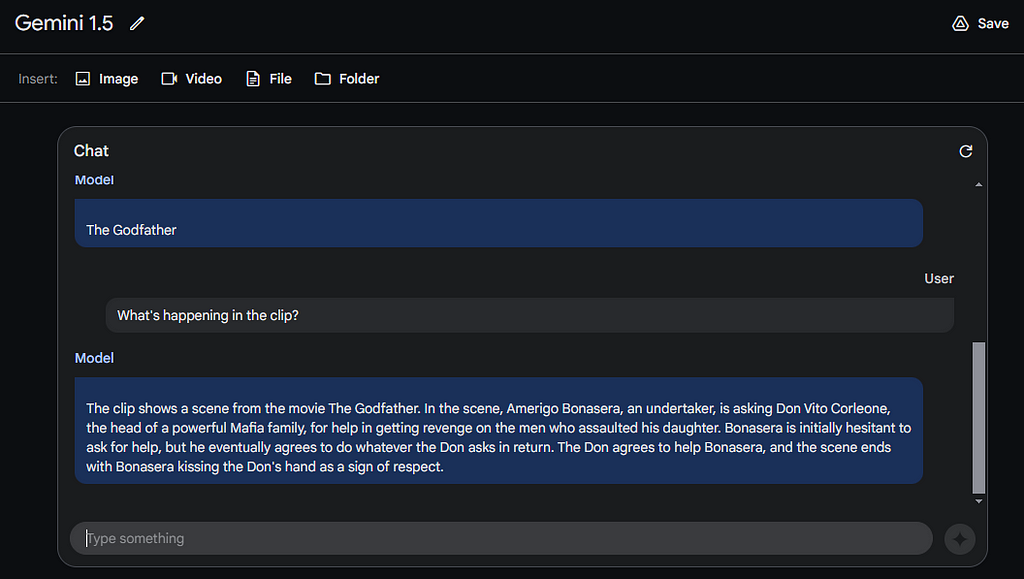
This response really shook me off. Gemini successfully processed such a huge data and perfectly described the scene.
Wasn’t it exciting to witness the capabilities of Gemini 1.5? If you’re eager to explore how to utilize Gemini on Google Cloud, the upcoming section will provide detailed coverage.
III. Gemini on Vertex AI
Step 1: Open Google Cloud console, and search for Vertex AI.
Step 2: Navigate to Vertex AI Studio and select Model Garden.
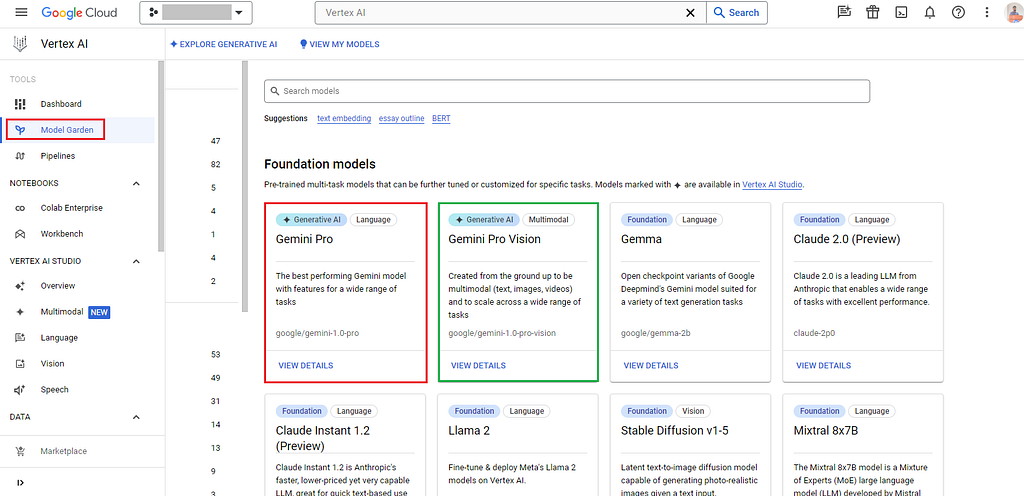
Within the Model Garden, both the Gemini Pro and Gemini Pro Vision foundation models are readily accessible. Select the model of your preference; for this instance, I’ll be using the Gemini Pro Vision model.
Step 3: Click on “View details”, and on the subsequent screen, you’ll find the option to use the Gemini Pro Vision either in Vertex AI Studio or within a Colab notebook.
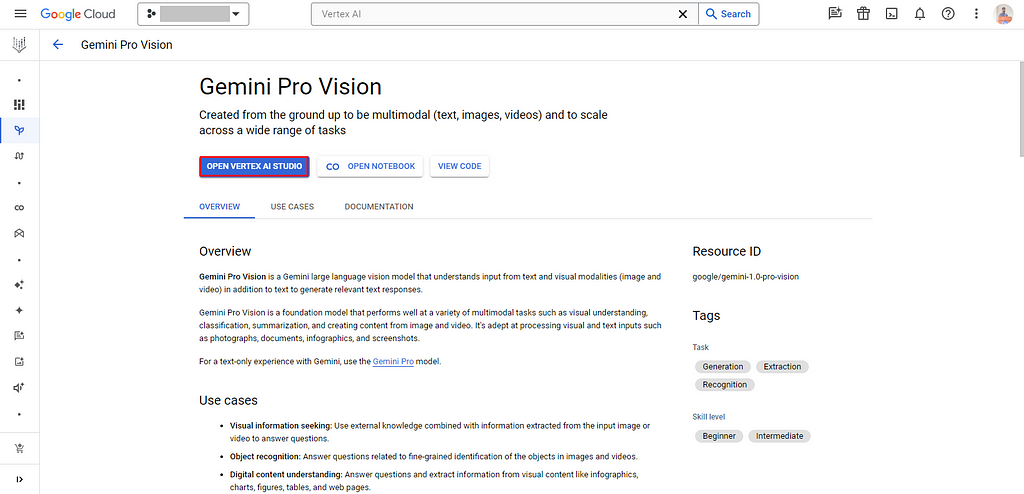
Alternatively, you can directly go to Vertex AI Studio → Multimodal to explore and experiment with the provided examples.
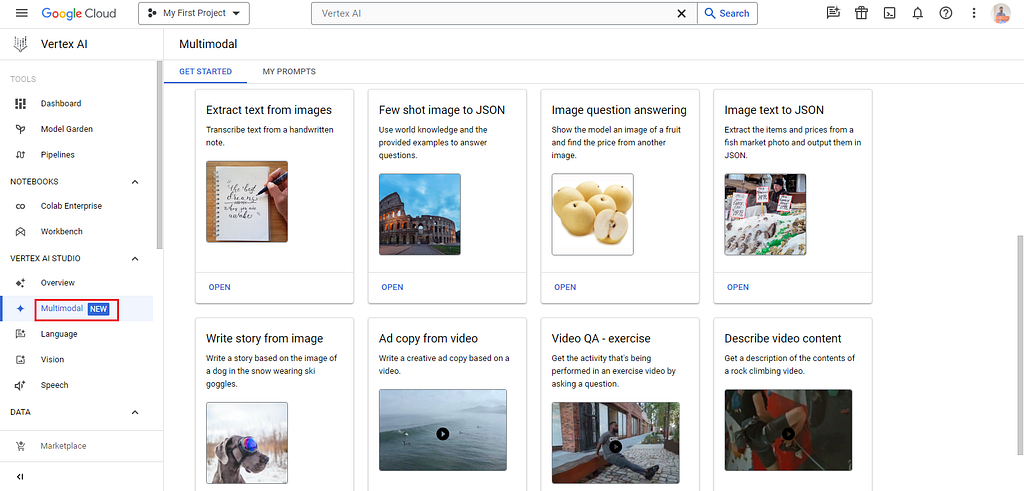
I’ve selected the Image question answering example, but feel free to try out any other example.
In the prompt, I provided the following image of me:
Prompt: What do you see in the image below?

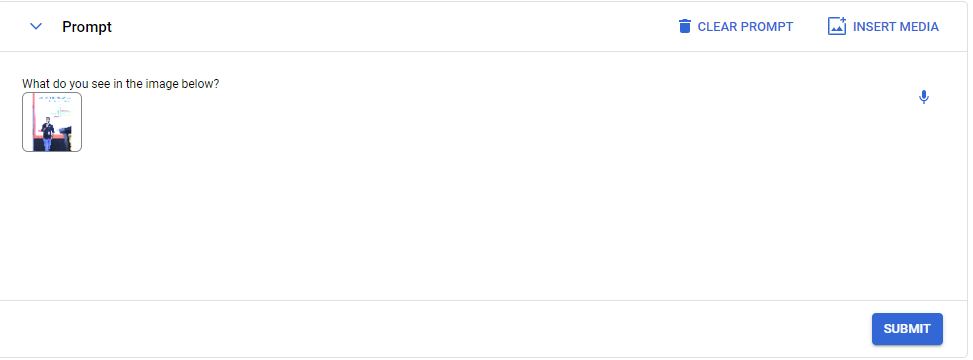
Here’s the response from Gemini Pro Vision. It has precisely described the content from the image. If you notice in the image, portions of the words “of” and “TensorFlow” are missing, yet Gemini Pro Vision perfectly inferred what those words might be.

Feel free to play around with more examples and some interesting prompts to uncover Gemini’s potential.
And with that, we conclude this blog. To recap, we began by exploring the evolution of language models, introduced Gemini models, discussed their high-level architecture, delved into benchmarks, and proceeded with practical demonstrations of the Gemini API on Google Colab.
Additionally, we explored utilizing the Gemini 1.5 models on Google AI Studio and Vertex AI within Google Cloud.
Bonus: Check out this recorded session where I talked about Gemini and their hands-on examples that we covered in this blog.
https://medium.com/media/e6d3b2f7416835b1164435bcb5f9a591/href
I hope you enjoyed reading this blog and learned the capabilities of Gemini. I’m excited to see what you build with Gemini. If you have any questions or interesting ideas, feel free to share with me at LinkedIn.
Until next time, stay tuned for more blogs.
Acknowledgment

Developed during Google’s ML Developer Programs Gemini sprint, this project benefited from generous GCP credits that facilitated its completion. I express my gratitude to the MLDP team for the support provided.
![]()
[ML Story] Unlock your ideas with Gemini: Hands-on guide was originally published in Google Developer Experts on Medium, where people are continuing the conversation by highlighting and responding to this story.