At first glance, it might seem counterintuitive that swapping uppercase letters for lowercase ones could lead to data savings. The explanation lies in the realm of text compression, where efficiency thrives on specific characteristics:
1. Smaller Variety of Characters
Consider a text with a limited character set:
Original Text:
The quick brown fox jumps over the lazy dog.
With Uppercase Letters:
The Quick Brown Fox Jumps Over The Lazy Dog.
In the second example, where uppercase letters are introduced, the variety of characters increases. This larger set of characters can potentially reduce compression efficiency.
2. Less Common Characters Used Less Frequently
Examine a scenario where less common characters are introduced:
Original Text:
The cat sat on the mat.
With Less Common Characters:
The çat såt øn the måt.
In this case, the less common characters like ‘ç,’ ‘å,’ and ‘ø’ are used. These characters, being less frequent, might impact compression efficiency as their occurrences are not as predictable.
3. Repetition of Characters or Groups
Explore a text with repeated characters or groups:
Original Text:
She sells seashells by the seashore. The shells she sells are surely seashells.
With Repetition:
She sells seashells by the seashore. The shells she sells are surely Seashells.
Introducing repetition, as seen with the capitalization of ‘S’ in “Seashells,” might affect compression efficiency. The repetition of characters or groups provides an opportunity for optimization.
Lowercasing contributes to all three aspects, making it a valuable technique in the quest for data optimization.
Huffman Encoding Compression Effects
Huffman encoding, a cornerstone of the deflate algorithm, initiates the compression process. In this method:
- Each character in an uncompressed text file consumes a fixed amount of data, typically 8 bits (in utf-8).
- Characters are encoded into binary sequences based on their frequencies.
- Uppercase letters are replaced with lowercase counterparts to optimize the encoding.
Check out this example of encoding the string “DATA_PROCESSING”.
Step 1: Building the Frequency Table
Before diving into the encoding process, we need to construct a frequency table based on the input data. For our example, the input data is “DATA_PROCESSING”, and the frequency table is as follows:
D: 1
A: 2
T: 1
_: 1
P: 1
R: 1
O: 1
C: 1
E: 1
S: 1
I: 1
N: 1
G: 1
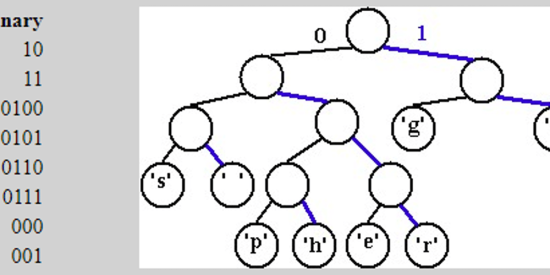
Step 2: Constructing the Huffman Tree
The Huffman tree is built by combining nodes with the lowest frequencies, eventually forming a single root node. The resulting Huffman tree for our example is as follows:
(14)
/
(6) (8)
/ /
(2) (4) (4) (4)
Step 3: Assigning Huffman Codes
Now, each character is assigned a binary code based on its position in the Huffman tree. The assigned Huffman codes are as follows:
D: 1110
A: 0
T: 1111
_: 1101
P: 1100
R: 101
O: 100
C: 11101
E: 11100
S: 11001
I: 1011
N: 1010
G: 11100
Encoding ‘DATA_PROCESSING’
With the Huffman codes established, we can now encode our original data. The binary representation of “DATA_PROCESSING” is:
0111011010111101111010110110111101111101011111110100110111001
Decoding the Encoded Sequence
The decoding process involves traversing the Huffman tree based on the encoded binary sequence. Following the tree traversal, we successfully decode the binary sequence to obtain the original data:
DATA_PROCESSING
Compression Efficiency?
Assuming an original text file size of 1000 bytes, Huffman encoding might yield a compressed file size of 550 bytes. Indeed, a suitable tool for developers dealing with resource constraints.
In scenarios where efficient data transmission over a network is crucial, Huffman encoding proves invaluable. By reducing the amount of data sent, developers can achieve significant bandwidth savings, leading to faster transmission speeds and improved overall performance.
Implementation Insights
When implementing Huffman encoding, developers should focus on the following key considerations:
- Frequency Table Construction: Efficiently build the frequency table for optimal tree generation.
- Tree Construction: Construct the Huffman tree based on character frequencies.
- Handling Edge Cases: Address edge cases to ensure robust implementation.
Leveraging existing libraries and tools streamlines the integration process, allowing developers to harness the power of Huffman encoding seamlessly.
Similar to this, I along with other open-source loving dev folks, run a developer-centric community on Slack. Where we discuss these kinds of topics, implementations, integrations, some truth bombs, weird chats, virtual meets, contribute to open–sources and everything that will help a developer remain sane 😉 Afterall, too much knowledge can be dangerous too.
I’m inviting you to join our free community (no ads, I promise, and I intend to keep it that way), take part in discussions, and share your freaking experience & expertise. You can fill out this form, and a Slack invite will ring your email in a few days. We have amazing folks from some of the great companies (Atlassian, Gong, Scaler), and you wouldn’t wanna miss interacting with them. Invite Form



