
Hey, Welcome!
I’ve created “Pyetra, the poet”. It automatically generates an image using the MidJourney model and finally a text using GPT-3 davinci model.
Here is what it looks like running my script 3 times in a row, with non-cherry-picked results:
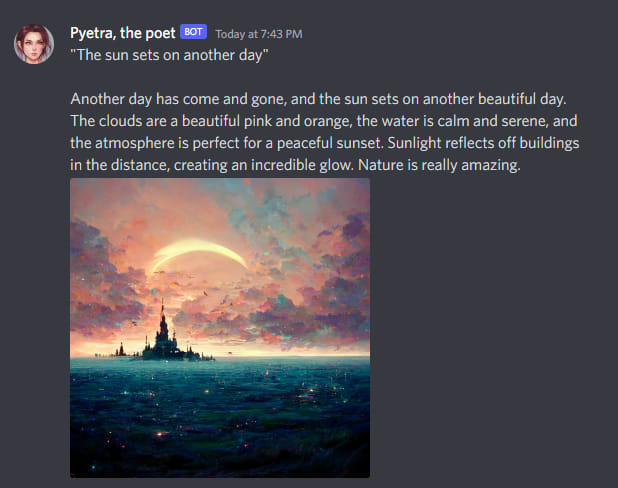


Let’s walk through the process of how this was achieved
1. Generating the image:
To generate the image I’m using a new image model called MidJourney, let’s talk about the image generation process first and then I’ll talk about the challenges of making it in an automated way
Image models receive some form of input and with it generate an output (an image), in MidJourney’s case the input is called a prompt (a text containing what you want the model to generate)
Some examples:
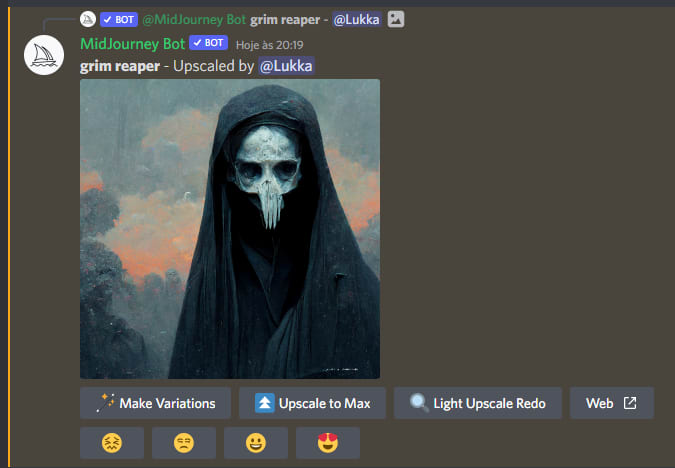
A simple prompt: “grim reaper”
A complex prompt: “warrior woman as the angel of death wearing armor with massive black wings on back, dark fantasy, mist, fog, heavenly light, epic, barroque, roccoco, details, photorealistic render, 3ds max + v ray, extremely detailed and intricate, center composition, elegant, vfx, unreal engine 5, octane render, extremely contrast, extremely sharp lines, 8k, –ar 2:3”

Note that the level of detail and ‘tags’ in the prompt plays a huge role in the generation of a more complex, detailed, and creative image, that is often referred to ‘prompt quality‘, the interesting thing is that it’s not necessarily about the size of the prompt, it’s about using ‘tags’ the model will understand
Here’s the upscaled version of the image we just generated

How to generate high-quality prompts?
In my case, I’ve created a machine learning model that learned from a dataset of high-quality prompts and now is able to generate random high-quality prompts
To achieve this I had to create such dataset, I used selenium, which is a browser automation tool and with it, I did what’s called web scraping, going to the MidJourney website and some discord channels to retrieve a big volume of high-quality prompts made by other people. If you’re on desktop you can see a portion of my dataset clicking in this link
The fact that the MidJourney website had a section about the featured creations, showcasing amazing creations and the prompt that was used to generate them, really helped


After web scraping prompts, manually labeling and assigning a score to each one of them, based on the image they generated and my personal opinion about the image, I finally had my dataset ready to use
I then trained a machine learning model to predict a prompt that would receive a high score from me
The only thing left was passing the prompt to MidJourney so it could generate the image, but there’s a challenge about this
Some image models like DALL-E plan to provide an API, a way to interact with the model in your code, with an API it’s pretty simple to integrate the image model and create your own projects, products, or solutions utilizing the model, without an API there are still some ways to interact with it but they’re more inconsistent and I wouldn’t recommend doing so for anything serious or in production
Currently (at the time of this post) MidJourney doesn’t have an API, so to automatically generate an image with this model I had to make a custom script that uses selenium (the browser automation tool I mentioned) to log in to a discord account in the browser and then interact with the MidJourney bot using it’s /imagine command
2. Generating the text:
To generate the text I’m using the OpenAI model text-davinci-002
At first, I thought about just sending the MidJourney prompt to davinci, but the results were always very generic, and more or less the same
Since some words like ‘rendering’, ‘8k’, ‘illustration’, ‘detailed’, ‘unreal engine’, ‘hdr’, ‘high contrast’ are very common in those prompts I would often see davinci talking about them and getting out of topic, talking about the video games industry and such (because of topics like rendering and unreal engine).

The results felt purely descriptive and I realized midway that wasn’t exactly what I was aiming for, I realized that I wanted something more poetic but not explicitly a poem
So at first I sanitized the prompt removing a bunch of those words that make davinci go out of topic, it got way better, but I still wasn’t satisfied with the results
Then I thought about passing into davinci exactly what can be found in the image and not just the prompt that was used to generate it
To achieve this I used Google Vision to get the exact features and elements of the images
If you’re unfamiliar with this Google product here are some of its capabilities
Meet Google Vision
It provides a list of ‘labels’, that are classifications made by the model, it often contains objects present in the image as well as some insights like ‘fictional character’

It provides a list of ‘objects’, usually, it returns very few objects but the ones more present in the image
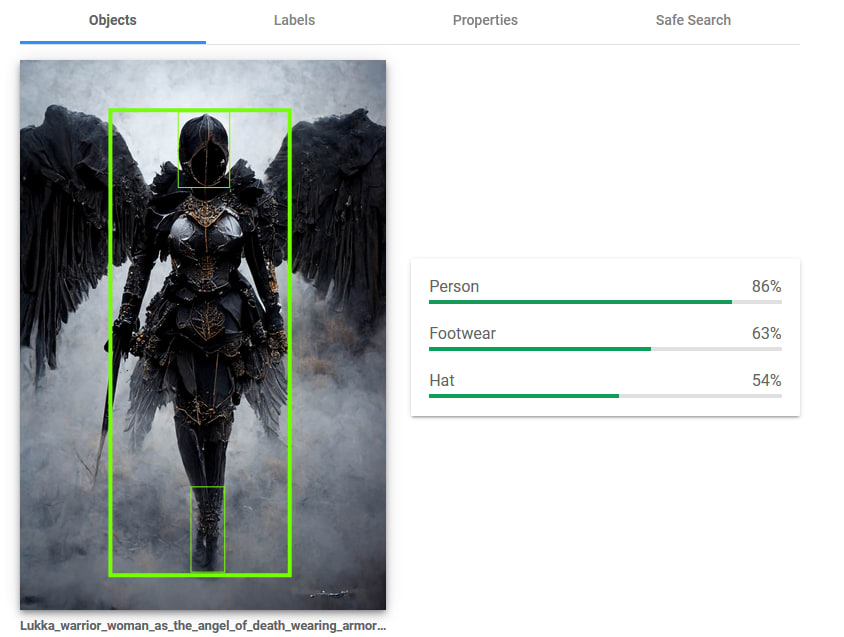
It provides a list of ‘properties’, with pieces of information such as colors present in the image and it’s aspect ratio
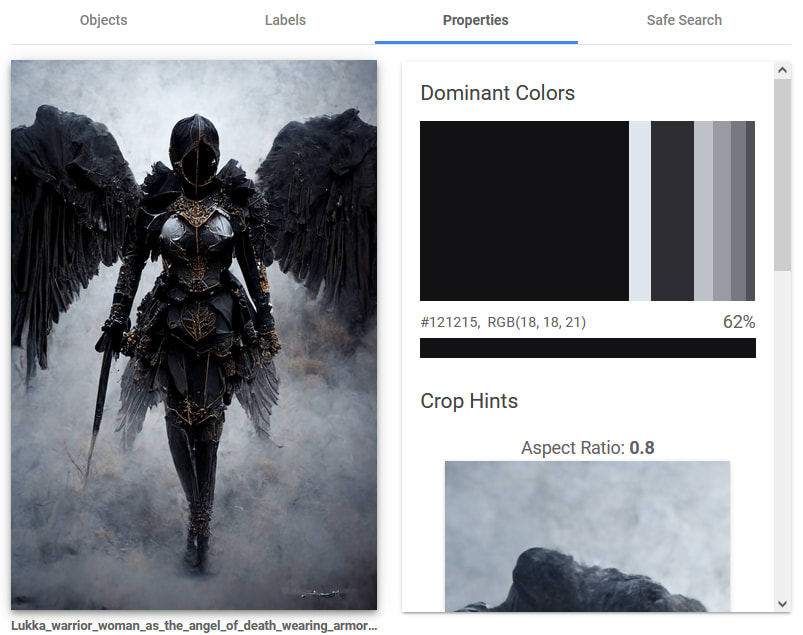
By providing all this information to davinci the text it’ll generate will be about the elements, colors, and features that can be found in the image, so it will be a lot less generic and a lot more specific to the image itself
Currently, I’m doing a mix of both ideas I had, I have excluded a set of words from the prompt (like ‘unreal engine’ and ‘rendering’) and I’m passing the sanitized prompt as well as the google cloud vision image information to the davinci model.
And here’s the final result:
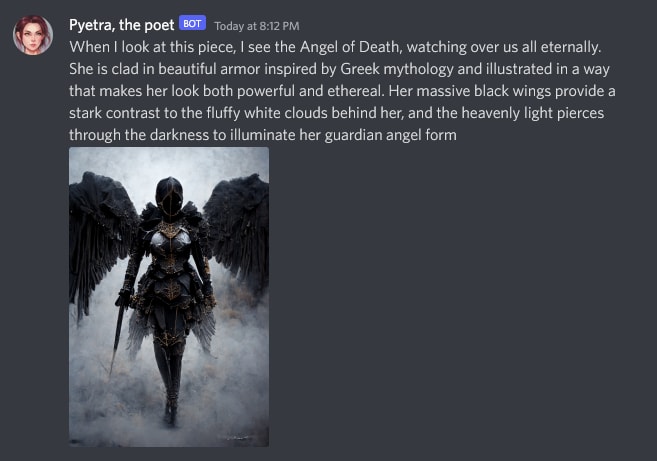
In summary, this is what’s going on:

My cloud architecture looks like this:
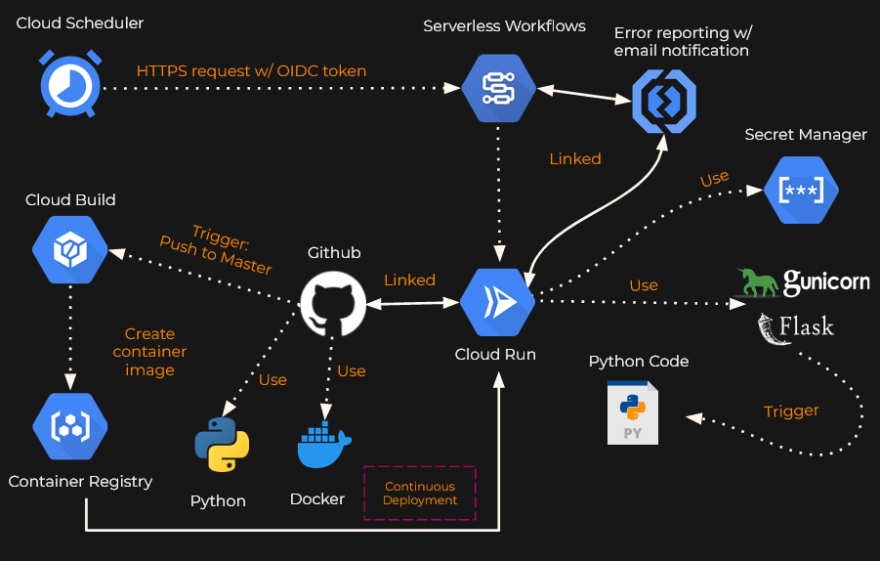
(Since I can’t modify the google cloud function runtime to install chrome and use selenium I’m using google cloud run with docker instead)
Below you can find exactly the davinci API call that I’m doing, where the variable ‘formatted_all_features’ contains the colors, labels, and objects found in the image, and ‘formatted_sanitized_prompt’ contains the MidJourney prompt without keywords that are irrelevant to the davinci text generation
response = openai.Completion.create(
model='text-davinci-002',
prompt=(
f"Write a text talking loosely about the art that you made and its"
f" {formatted_all_features} and {formatted_sanitized_prompt}"
),
temperature=1,
max_tokens=800,
top_p=1,
frequency_penalty=1.02,
presence_penalty=1.02
)
Hope you enjoyed reading or this was informative in any capacity.
- The banner of this post was generated using MidJourney
- MidJourney is an evolving project and the experience is still changing significantly, the images contained in this post were generated in 8/7/2022 (%m/%d/%Y)
Feel free to ask questions, make suggestions and contact me:
My email is lukkamvd@gmail.com
here’s my linkedin



The difference between the right word and the almost right word is more than just a fine line! it’s like the difference between a lightning bug and the lightning!