
Hello my esteemed readers, today we will cover installing Apache Spark in our Ubuntu 22.04 and also to ensure that also our Pyspark is running without any errors.
From our previous article about data engineering, we talked about a data engineer is responsible for processing large amount of data at scale, Apache Spark is one good tools for a data engineer to process data of any size. I will explain the steps to use using examples and screenshots from my machine so that you don’t run into errors.
What is Apache Spark and what is it used for?
Apache Spark is a unified analytics engine for large-scale data processing on a single-node machine or multiple clusters. It is open source, in that you don’t have to pay to download and use it. It utilizes in-memory caching and optimized query execution for fast analytic queries for any provided data size.
It provides high-level API’s in Java, Scala, Python and R ,optimized engine that supports general execution graphs. It supports code reuse across multiple workloads such as batch processing, real-time analytics, graph processing, interactive queries and machine learning.
How does Apache Spark work?
Spark does processing in-memory, reducing the number of steps in a job, and by reusing data across multiple parallel operations. With Spark, only one-step is needed where data is read into memory, operations performed, and the results written back thus resulting in a much faster execution. Spark also reuses data by using an in-memory cache to greatly speed up machine learning algorithms that repeatedly call a function on the same dataset. We create DataFrames to accomplish data re-use, an abstraction over Resilient Distributed Dataset (RDD), which is a collection of objects that is cached in memory, and reused in multiple Spark operations. This dramatically lowers the latency as Apache Spark runs 100 times faster in-memory and 10 times faster on disk than Hadoop MapReduce.
Apache Spark Workloads
Spark Core
Spark Core is the underlying general execution engine for spark platform that all other functionality is built upon. It is responsible for distributing, monitoring jobs,memory management, fault recovery, scheduling, and interacting with storage systems. Spark Core is exposed through an application programming interface (APIs) built for Java, Scala, Python and R.
Spark SQL
Performs interactive queries for structured and semi-structured data.. Spark SQL is a distributed query engine that provides low-latency, interactive queries up to 100x faster than MapReduce. It includes a cost-based optimizer, columnar storage, and code generation for fast queries, while scaling to thousands of nodes.
Spark Streaming
Spark Streaming is a real-time solution that leverages Spark Core’s fast scheduling capability to perform streaming analytics. It ingests data in mini-batches and performs RDD (Resilient Distributed Datasets) transformations on those mini-batches of data.
Machine Learning Library (MLib)
Spark includes MLlib, a library of algorithms to do machine learning on data at scale. Machine Learning models can be trained by data scientists with R or Python on any Hadoop data source, saved using MLlib, and imported into a Java or Scala-based pipeline.
GraphX
Spark GraphX is a distributed graph processing framework built on top of Spark. GraphX provides ETL, exploratory analysis, and iterative graph computation to enable users to interactively build, and transform a graph data structure at scale. It also provides an optimized runtime for this abstraction.
Key Benefits of Apache Spark:
-
Speed: Spark helps to run an application in Hadoop cluster, up to 100 times faster in memory, and 10 times faster when running on disk. This is possible by reducing number of read/write operations to disk. It stores the intermediate processing data in memory.Through in-memory caching, and optimized query execution, Spark can run fast analytic queries against data of any size.
-
Support Multiple Languages: Apache Spark natively supports Java, Scala, R, and Python, giving you a variety of languages for building your applications.
-
Multiple Workloads: Apache Spark comes with the ability to run multiple workloads, including interactive queries, real-time analytics, machine learning, and graph processing.
Now we have a basic understanding about Apache Spark, we can proceed to our installation in our machines.
To download Apache Spark in Linux we need to have java installed in our machine.
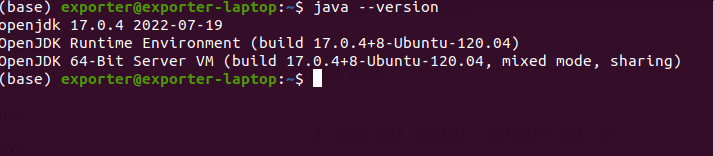
To check if you have java in your machine, use this command:
java --version
For example in my machine, java is installed:
In case you don’t have java installed in your system, use the following commands to install it:
Install Java
first update system packages
sudo apt update
Install java
sudo apt install default-jdk -y
verify java installation
java --version
Your java version should be version 8 or later version and our criteria is met.
Install Apache Spark
First install the required packages, using the following command:
sudo apt install curl mlocate git scala -y
Download Apache Spark. Find the latest release from download page
wget https://dlcdn.apache.org/spark/spark-3.3.0/spark-3.3.0-bin-hadoop3.tgz
Replace the version you are downloading from the Apache download page, where I have
entered my spark file link.
Extract the downloaded file you have downloaded, using this command to extract the file:
tar xvf spark-3.3.0-bin-hadoop3.tgz
Ensure you specify the collect file name you have downloaded, since it could be another version. The above command extracts the downloaded file into the directory that you downloaded in. Ensure you know the path directory for your spark file.
For example, my spark file directory appears as shown in the image:

Once you have completed the above processes it means you are done with download the Apache Spark, but wait we have to configure Spark environment. This is one the section that give you errors and you wonder what you aren’t doing right. However, I will guide to ensure that you successfully configure your environment and able to use Apache Spark in your machine and ensure Pyspark is runs as expected.
How to Configure Spark environment
For this, you have to set some environment variables in the bashrc configuration file
Access this file using your editor, for my case I will use nano editor, the following command will open this file in nano editor:
sudo nano ~/.bashrc
![]()
This is a file with sensitive information, don’t delete any line in it, go to the bottom of file and add the following lines in the bashrc file to ensure that we will use our Spark successfully.
export SPARK_HOME=/home/exporter/spark-3.3.0-bin-hadoop3
export PATH=$PATH:$SPARK_HOME/bin
export SPARK_LOCAL_IP=localhost
export PYSPARK_PYTHON=/usr/bin/python3
export PYTHONPATH=$(ZIPS=("$SPARK_HOME"https://dev.to/python/lib/*.zip); IFS=:; echo "${ZIPS[*]}"):$PYTHONPATH
Remember when I asked you to note your Spark installation directory, that installation directory should be assigned to export SPARK_HOME
export SPARK_HOME=
For example you can see mine is set to:
export SPARK_HOME=/home/exporter/spark-3.3.0-bin-hadoop3
Then write the other lines as they are without changing anything and save that bashrc file. The image below shows how the end of my bashrc file appears after adding the environment variables.

After exiting our bashrc file from our nano editor, you need to save the variables. Use the following command:
source ~/.bashrc
The below image show how you write the command, I wrote my command twice but just write it once.

How to run Spark shell
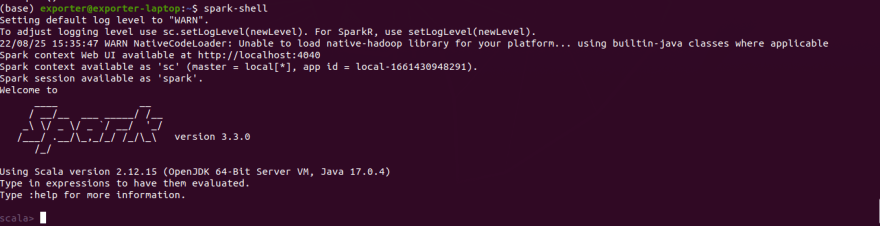
For now you are done with configuring the Spark environment, you need now to check that your Spark is working as expected and use the command below to run the spark shell;
spark-shell
For successful configuration of our variables, you see an image such as this one.
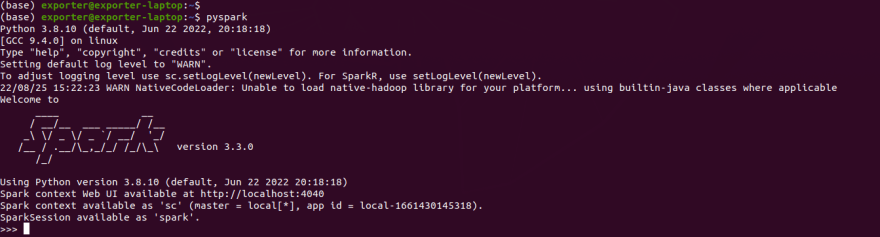
How to run Pyspark
Use the following command:
pyspark
For successful configuration of our variables, you see an image such as this one.
In this article, we have provided an installation guide of Apache Spark in Ubuntu 22.04, as well as the necessary dependencies; as well as the configuration of Spark environment is also described in detail.
This article should make it easy for you to understand about Apache Spark and install it. So esteemed readers feel free to give feedback and comments.



