Clean architecture is a staple of the modern app development space. Particularly popular for Java and Android developers, this architecture is designed to make it easier to create stable apps even when outer elements such as UI, databases, or external APIs are always changing. The focus on constant iteration has become a staple of companies like Amazon and other FAANG companies.
Today, we’ll help you get started with clean architecture by exploring popular diagrams of the design and breaking down each of the core principles.
Here’s what we’ll cover today:
- What is clean architecture?
- Clean diagram deep-dive
- Benefits of clean architecture
- Principles of clean architecture
- What to learn next
What is clean architecture?
Clean architecture is a category of software design pattern for software architecture that follows the concepts of clean code and implements SOLID principles.
It’s essentially a collection of best practice design principles that help you keep business logic, or domain logic, together and minimize the dependencies within the system. If followed, clean architecture allows software architects with decoupling components to become isolated enough to be durable and easily changed without remaking the system.
Business logic: The code that converts real-world goals or limitations into the software system. Business logic often relates to how data can be created, stored, and changed.
The concept of clean code and clean architecture was originally coined in 2008 by Robert C. Martin, known in the community as “Uncle Bob”. His book The Clean Coder has gone on to be a staple guide for modern scalable app design.
Clean architecture has grown in popularity and programmers have developed many subcategories of clean, such as hexagonal architecture, onion architecture, screaming architecture, and many more.
Clean diagram deep-dive
In its most basic form, clean architecture can be explained with the following diagram:
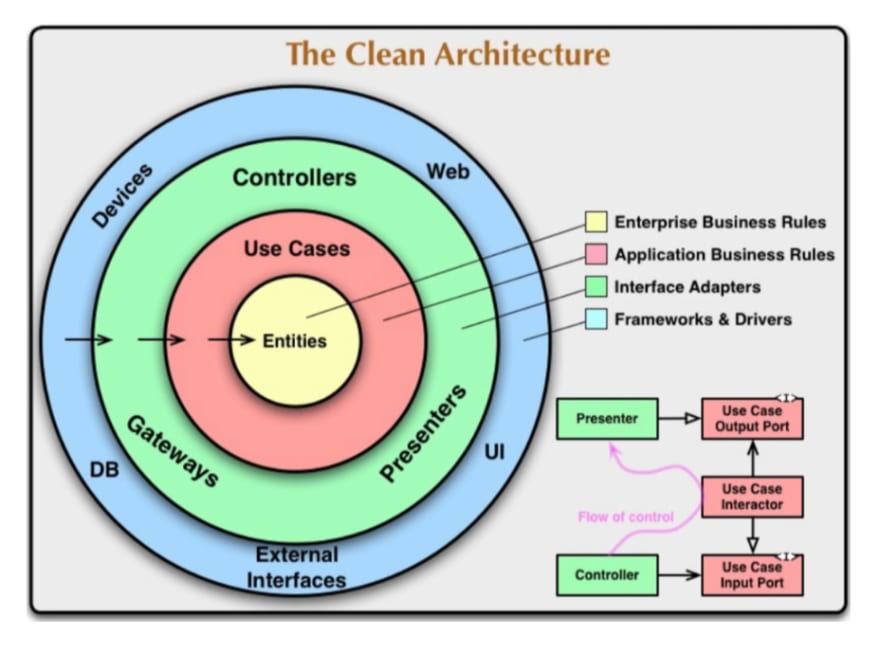
This diagram can be a bit confusing at first so let’s break it down.
- Entities: Entities is one of the two inner circle domain layers that represent domain and business logic. They are enterprise-wide business rules, or things that will always be true or static for this application. Entities can be an object with methods or just a collection of data structures and functions. They encapsulate the most general or higher-level and are therefore the least likely to change due to a change to an outer layer.
For example, the core functionalities of an app wouldn’t be changed by changing your front-end framework to React to Angular.
- Use Cases: Use Cases is the second domain layer. It defines application-specific business rules. They encapsulate and implement all of the approved use cases for the application. The use cases control the flow to and from entities and can call on entities to use their enterprise-scale rules to complete certain user tasks.
Changes in this layer will not affect entities or more external layers. However, this layer will have to be changed if external layers are changed.
- Interface Adapters: This layer adapts input into a form that’s most usable by the use cases and entities layers. It also formats output from the entities or use cases into a form that’s most suitable for external-facing channels. The adapters layer is the effective boundary between the inner and outer circle layers. No code inward of this layer should know about or reference anything more external than this layer.
You can think of interface adapters as a translator that converts and relays information in the way that’s most usable by inner and outer layers respectively.
- Framework and Drivers: Framework and Drivers is the presentation layer that is usually composed of frameworks and tools such as databases, web frameworks, and so on. This layer doesn’t feature much code but rather contains all necessary concrete references to specific details like database-specific operations or commands specific to the current framework.
For example, this would wholly contain the MVC architecture of a GUI.
The two ways to understand this diagram are to take look at it as a flow chart or as a dependency cone.
Flow Chart
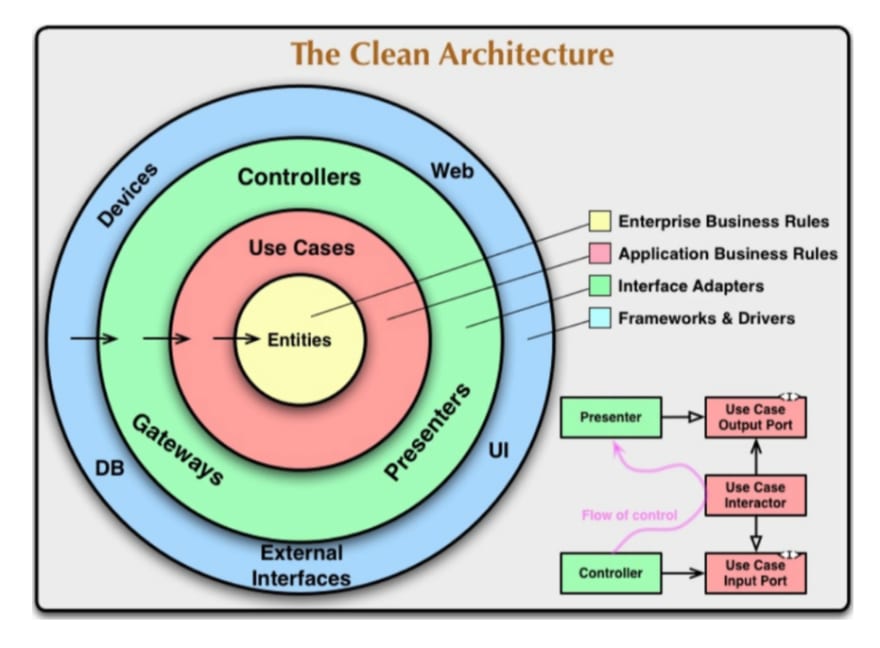
The full flow chart above is great for understanding the path data takes through the program. Input enters from the left “Framework and Drivers” layer and goes through the configuration channels to reach the APIs and JOBS.
This green “Interface Adapters” section can process the input with plain code business logic and match them with one of the approved use cases. Each business activity will have a single use case to cover it. If the input does not fit an expected use case, the system sends an error.
Once it’s processed into a form the core can understand, the core Enterprise and Application domain logic applies completes the task, and produces an output.
The output is first passed back through the interface adapter layer and is converted into a form that’s most usable for the outer layers. Based on the use case of the output, it is then pushed to the appropriate output channel, such as a database, app view, or network device.
This demonstrates a principal factor of the Dependency Rule: all dependencies point inward throughout this process, so external layers can be changed without affecting the inner layers.
Clean cone diagram
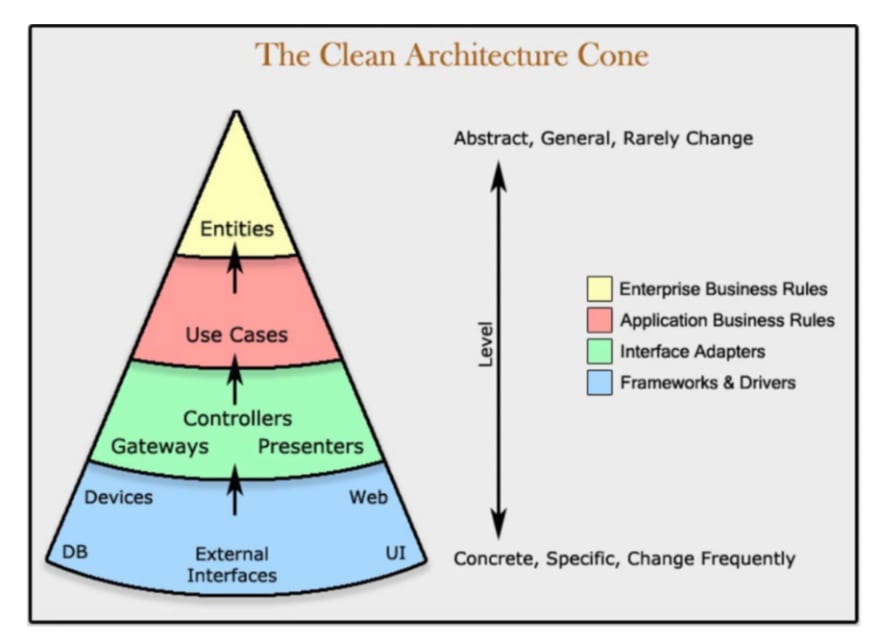
This view is better for understanding the dependency inversion of the system and seeing the level of abstraction for each layer. The main takeaway of this diagram is that clean architecture allows outer layers to depend on inner layers but not the other way around.
This is because external implementation tools like UI, databases, and interfaces often change as trends develop but the core logic of an application rarely changes. As a result, clean architecture is set up to allow these tools to change without much issue because they do not have dependencies.
The layers closer to the core are more abstracted and do not make reference to concrete implementations. Instead, they keep things at a more business-type logic level. On the other hand, the outer layers are more concrete and will reference particular tools or implementations.
Benefits of Clean Architecture
- Highly Testable: Clean architecture is built from the ground up for testing. You can create test cases for each layer to determine where errors occur within the circle.
Since each layer has a defined role, it’s often obvious where an error has occurred. It also allows you to skip certain test cases depending on what you’ve updated because internal layers shouldn’t be affected by changes to the internal layers.
- Framework Independent: Clean architecture doesn’t rely on tools from any specific framework and doesn’t use the framework as a dependency anywhere in the code.
As a result, you can easily update or change the framework at any time with minimal work required to transition. All internal layers should still work even if you adopt a different framework.
- Database Independent: The majority of your application will not know or need to know what database it’s drawing from. This means you can adopt a new database with no changes to the majority of the source code.
This means you could transition from an SQL to a NoSQL database instantly, without changing any code.
- UI Independent: UI frameworks exist on the outermost layer and therefore are just a presenter for data passed from internal layers.
Nothing depends on the presenter, and therefore, you can change the UI framework at any time.
Principles of clean architecture
Clean architecture is defined as any architecture that follows clean principles. This means you can combine programming paradigms to create clean microservice architectures or clean versions of any other architecture used in software development.
Some of these principles are shared with SOLID and other popular strategies, so you may already be familiar with some!
Let’s explore each.
Common Closure Principle
The Common Closure Principle (CCP) states: “The classes in a component should be closed together against the same kind of changes. A change that affects a component affects all the classes in that component and no other components.”
This is essentially the Single Responsibility Principle applied to app components. In other words, a component should only have a single reason to change. If that thing does change, it should affect the whole component. If something other than the single responsibility changes, the component shouldn’t require changes.
For example, a component that searches our database for a user’s input should only be changed if the method of searching changes. The search component should not change if the database or user input changes.
CCP is designed to increase the maintainability of a system by reducing the number of components that need reworking with a single change. If every component had multiple reasons to change, you’d have to devote more hours to reworking and verifying each component after a small change is made. If each component is only affected by a single type of change, you only have to worry about reworking the component that pertains to the change.
Dependency Inversion Principle
The Dependency Inversion Principle states that:
1) “High-level modules should not depend on low-level modules. Both should depend on abstractions (e.g., interfaces).”
2) “Abstractions should not depend on details. Details (concrete implementations) should depend on abstractions.”
This is perhaps the most important principle for clean architecture. The first part of this principle reverses traditional OOP software design. Without DIP, programmers often construct programs to have high-level (less detail, more abstract) components explicitly connected with low-level (specific) components to complete tasks.
DIP decouples high and low-level components and instead connects both to abstractions. High and low-level components can still benefit from each other, but a change in one should not directly break the other.
The second part can be thought of as “the abstraction is not affected if the details are changed”. The abstraction is the user-facing part of the program.
The details are the specific behind-the-scenes implementations that cause program behavior visible to the user. In a DIP program, we could fully overhaul the behind-the-scenes implementation of how the program achieves its behavior without the user’s knowledge.
This process is known as refactoring.
This means you won’t have to hard-code the interface to work solely with the current details (implementation). This keeps our code loosely coupled and allows us the flexibility to refactor our implementations later.
Common Reuse Principle
The Common Reuse Principle (CRP) states: “The classes in a component are reused together. If you reuse one of the classes in a component, you reuse them all.”
The idea behind this principle is that classes within your component should be inseparable. If you find a situation where you need one class and not others, it’s an indication that your component is not fulfilling a single use.
Any time a component uses a class from another component, it creates a dependency between the components. Clean architecture mainly focuses on reducing the number of dependencies keeping components together and therefore tries to avoid this at all costs. While it may seem like more work to split up components, it will save you time in the long run because you won’t have to refactor as many components with each update.
Release Equivalence Principle
The Release Equivalence Principle states that: “the unit of reuse, a component, can be no smaller than the unit of release. Effective reuse requires tracking of releases from a change control system. The package is the effective unit of reuse and release.”
This is the hardest principle to unpack so we’ll go piece by piece.
- The unit of reuse can be no smaller than the unit of release. This means you cannot release a component with the intention that only a portion is reused. The entirety of what’s released must be reusable.
- Effective reuse requires tracking of releases from a change control system. Authors must name their releases with a way to identify versions such as a number or name to allow users to version control.
- The package is the effective unit of reuse and release. Reusing packages is cleaner than reusing sole classes because it allows you to pass the full unit of functionality along with all of its pieces. By reusing the entire package, you’re able to maintain CRP because whole components are shared and maintain package cohesion because all updates are included in the package.
Each of these individual aspects allows single-responsibility components to be reused across clean architectures without the reuse process resulting in more work.
What to learn next
Congratulations on taking your first step toward designing clean architecture! The field of design architecture is always changing so it can be tough to keep up to date. Some other trending architectural styles are:
- Domain-Driven Design (DDD)
- Event-Driven Design (EDD)
- Hexagonal Architecture
- Microservice architecture
To help you understand these architectures and other skills to make effective programs, Educative has created Effective Software Development for Enterprise Applications. This course explores all the top industry methodologies for application design, teaches you when to use each, and how to avoid common pitfalls.
By the end, you’ll have the app design you’ll need to ace your interview and excel in the modern enterprise app space.
Happy learning!
Continue learning about architectures on Educative
- Hexagonal architecture tutorial: Build maintainable web apps
- Microservices Architecture Tutorial
- MVC Architecture in 5 minutes: a tutorial for beginners
Start a discussion
What other kinds of architectures do you want to learn about? Was this article helpful? Let us know in the comments below!




