
Disclaimer: Os exemplos usados aqui embora baseados em projetos reais são de minha autoria. Eu simplifico/altero alguns detalhes de forma a simplificar o post e preservar a IP das empresas. Esse post é 100% baseado apenas em minhas opiniões e não reflete meus empregadores.
A ideia desse post surgiu de uma discussão que eu tive com o @rponte. Com todos os debates recentes sobre “Arquitetura Limpa” e “Ports and Adapters” nós conversávamos como nos últimos 7 anos os projetos que eu passei foram estruturados em empresas como Amazon e Twitter.
A Arquitetura simples
Eu pensei nesse termo “Arquitetura Simples” como uma brincadeira com o termo arquitetura limpa. Esse estilo de arquitetura não é proposital, ele nasce naturalmente a partir do momento que o time de desenvolvimento abraça os dois seguintes princípios:
- YAGNI – You aren’t gonna need it (Você não vai precisar disso).
-
KISS – Keep it Simple Stupid ou Keep it Super Simple (Mantenha simples estúpido ou mantenha super simples).
A ideia “central” é que o time não vai gastar energia e esforço projetando sistemas tentando prever o futuro ou desacoplando camadas sem que os requisitos exijam isso.
Eu seria hipócrita em dizer que isso é/foi uma escolha consciente. Nos últimos 8 anos que trabalhei em empresas como Amazon e Twitter nós nunca nos sentamos e decidimos explicitamente “essa será a arquitetura do nosso sistema”. Os sistemas simplesmente eram escritas e vinham “à tona” nessa forma simples. Talvez pela facilidade e naturalidade de como é começar um projeto dessa forma.
Também é importante mencionar que a forma como esses sistemas são escritos não é a forma perfeita para todas as aplicações e tão pouco eu acho que essa seja a solução para todos os problemas. “There’s no silver bullet” (Não há bala de prata) é um outro princípio que eu acredito e que eu acho que deve ser sempre ponderado por todos os times nos mais diversos projetos.
As “camadas” das “Arquitetura Simples”
As camadas da nossa arquitetura são o mais simples possível (com o perdão do trocadilho) e eu sei que isso pode incomodar muita gente. Normalmente as dependências são diretas, por exemplo, um controller depende diretamente da classe que implementa o caso de uso daquele controller, ou o caso de uso depende diretamente da classe de persistência que salva os dados ou recupera os dados que ele precisa.
Os componentes podem ser observados no diagrama abaixo:
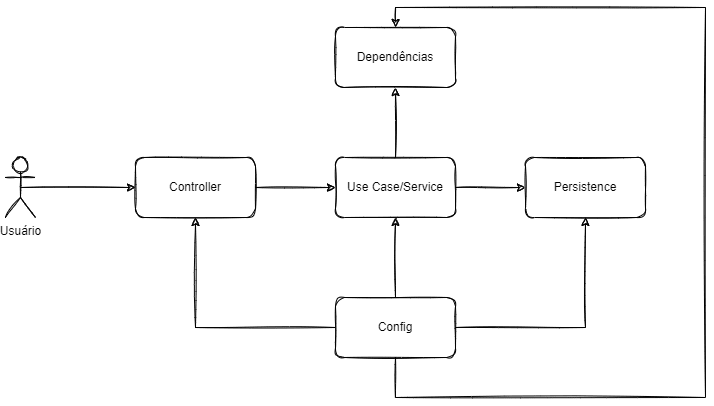
Controlers
Um controller por API, aqui a gente recebe um RequestDTO que representa a requisição de uma API RPC, fazemos todas as validações de input e outras coisas como logging.
Depois existem diversas opções aqui que variam de projeto pra projeto:
- Passamos o RequestDTO diretamente para o objeto de caso de uso. Essa opção favorece simplicidade (KISS e YAGNI), porém acopla teu objeto de caso de uso com modificações no modelo da API. Muitas vezes, isso está totalmente ok.
- Esse RequestDTO é traduzido pra uma entidade de negócio do caso de uso se as entidades forem extremamente anêmicas. Essa opção favorece simplicidade porém em muitos casos a entidade vai ser criada incompleta e vai ser um objeto mutável que é preenchido com mais informações na camada de negócio.
- Traduzimos o RequestDTO para algum outro DTO que é usado exclusivamente como input da API de caso de uso. Esse é o modelo mais flexível que desacopla negócios da API porém é mais verboso e exige transferir os dados de um DTO pra outro. A flexibilidade ajuda se o caso de uso utilizar inputs diferentes, por exemplo, uma API síncrona e um worker assíncrono.
Por que? É comum o controller fazer várias regras referentes a obtenção de dados, logging e outras validações. Misturar isso com a coordenação entre diversos outros objetos como invocar serviços externos e salvar no banco de dados deixa o controller grande demais. No geral, nós quebramos o controller pra:
- Reduzir o tamanho e complexidade da classe.
- Facilitar a segregação de responsabilidades e consequentemente os testes de unidade.
Sobre traduzir o RequestDTO para um outro modelo interno, é comum a API e consequentemente seu DTO evoluir a passos diferentes do modelo interno. Em 100% dos projetos que participei, toda vez que tentamos utilizar um único modelo interno e pra request a coisa desandou e depois tínhamos que fazer um refactoring pra desacoplar os modelos um do outro. Hoje em dia, eu já insisto em começarmos com modelos separados pra evitar essa dor.
Casos de Uso/Entidades
As classes dessa camada normalmente caem em 2 grupos:
- Classes de caso de uso: Essas classes implementam as regras de negócio da aplicação colando entidades, persistência e dependências. Aqui o modelo é bem flexível e varia de aplicação pra aplicação. No geral, se tem uma classe de caso de uso por caso de uso do usuário mas diversos modelos e entidades de suporte que ajudam a extrair responsabilidades específicas em classes menores.
- Entidades: São as entidades do nosso sistema. Elas podem ser anêmicas sendo apenas simples estrutura de dados ou agrupar comportamento que alteram o valor do objeto. As entidades também nos ajudam a encapsular módulos e comportamentos que são comuns ao resto da aplicação.
Por que? Uma coisa que eu aprendi ao longo dos anos é ter muito cuidado em reusar essas classes de caso de uso para múltiplas APIs. No início essa ideia parece funcionar mas com o tempo as regras de negócio vão mudando e as classes de caso de uso vão ficando cheias de regras especiais para diferentes APIs. Um bom exemplo é quando chamamos essas classes de “Manager”, por exemplo, ProductManager e aí você implementa create/update/delete/read na mesma classe só pra reusar algumas funções em comum. Agora imagine que o caso de uso de update tem 3 dependências, o de delete tem 2 e o create tem outras 3. Mesmo que haja sinergia entre elas, as vezes as dependências vão ser diferentes e no pior dos casos a sua classe pode acabar com 8 dependências diferentes. Nesse caso, talvez seja melhor quebrar em classes de caso de uso diferentes e abstrair os comportamentos comuns que são independentes de caso de uso nas entidades de domínio.
Ainda nessa camada a maior polêmica é, devo anotar nossas entidades com anotações de persistência ORM? Na maioria dos projetos que eu entrei entidades de persistência e entidades de domínio são mantidas separadamente e sempre temos que converter de uma pra outra. Porém, olhando pra trás eu me pergunto se essa separação é realmente necessária. Novamente, nessa mesma maioria dos projetos, sempre houve um mapeamento 1:1 de um campo de domínio pra um campo na persistência. Essa separação só nos causa mais dor na hora de implementar algo novo e definitivamente quebra o nosso princípio KISS e YAGNI. Se eu fosse começar um projeto novo, provavelmente eu começaria com o domínio mapeado com o framework de ORM. Se as coisas começarem a divergir então eu faria uma task para separá-los.
Dependências externas
Para cada serviço externo, onde externo significa uma chamada de rede, nós criamos uma classe. Essa classe funciona como uma Facade e Anti-Corruption Layer entre o nosso domínio e as dependências externas. A API com essa classe normalmente se dá em tipos simples ou através das nossas próprias entidades.
Por que? Aqui queremos isolar as dependências daquele sistema externo em um único ponto. Logo se a API mudar, for deprecated ou algo específico daquele sistema acontecer, apenas 1 classe do nosso código é afetada.
Camada de Persistência
Similar a camada que interage com os serviços externos. Nós temos uma camada de persistência que contém a classe que faz a chamada ao banco de dados e as entidades de persistência que são mapeadas por algum framework ORM (se você já nao tiver feito isso no domínio).
Por que? Nós tentamos manter a persistência tão simples quanto possível. Inclusive, hoje em dia é possível implementar a maioria dessas operações utilizando frameworks, como por exemplo, o Spring DATA.
Configurações e preocupações transversais
Colando todas essas camadas nós temos a camada de configuração. Normalmente, essa camada é representada pelo framework de injeção de dependências de sua escolha que cria todos os objetos e faz o wiring para que eles funcionem juntos.
É nessa camada também que carregamos as variáveis de ambiente que variam por região(US, JP, BR, etc…) e/ou stage (dev, pre-prod e prod).
Outra configuração que eu colocaria nessa camada são preocupações transversais. Classes que interceptam algum comportamento entre camadas, por exemplo. Esses interceptadores são bem comuns na camada de Controller, por exemplo. Eles podem realizar funções como validação de dados, autenticação, logging de chamadas, etc… tudo isso feito ANTES da chamada ser tratada pelo controller. Como essas funções são bem genéricas, é fácil isolar elas e acopla-las com todos os controllers da aplicação.
Por que? Por convenção. A maioria dos locais que eu trabalhei tem a convenção de não colocar muitas annotations no código da camada de casos de uso. Além disso, sobre as config classes, é que muitos dos nossos objetos são criados com algumas lógicas interessantes. Logo usar config classes em vez de annotations acaba facilitando por nos dar mais controle e flexibilidade.
Eu já passei por alguns exemplos bem específicos onde as anotações atrapalharam mas dito isso, pros projetos que nós tínhamos não há muita diferença entre usar as anotações ou não, logo, se estivesse começando um projeto novo eu faria o que é mais simples e segue as convenções da empresa.
Estudo de caso 1: ReviewsService
Para ilustrar a “arquitetura” que eu mencionei acima, vamos imaginar como seria o sistema de submissão de avaliações (reviews) de produto de um grande e-commerce.
Disclaimer: Qualquer semelhança com a realidade é mera coincidência. 🤭
Imagine que nós temos que implementar o caso de uso: CreateReview. Depois de esboçamos o system design e discutimos com o time nós chegamos ao seguinte fluxo:
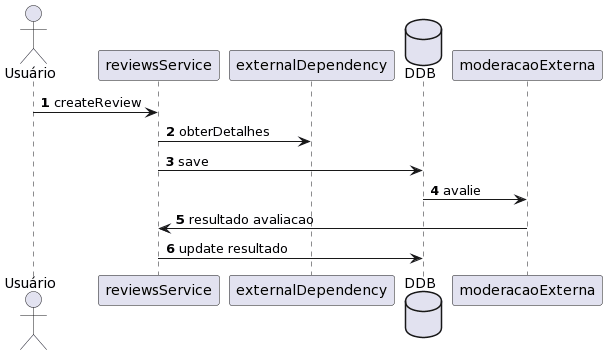
- Usuário invoca o serviço para criar uma nova review.
- reviewsService invoca um serviço externo para obter detalhes adicionais da review. Por exemplo, apelido do usuário.
- reviewService salva a review no banco de dados.
- Banco de dados notifica um serviço de moderação com uma nova review criada.
- Serviço de moderação retorna o resultado da avaliação para o reviewsService.
- ReviewsService faz update no banco de dados com o resultado da avaliação.
Agora na hora da implementação nós imaginamos as seguintes classes/camadas:

Controllers
Nós temos 2 controllers:
- CreateReview que implementa nossa API. Esse controller recebe a requisição, faz todas as validações de entrada necessárias e transforma o RequestDTO em CreateReviewDTO que é enviado para a nossa classe de caso de uso. Essa transformação é opcional e nem todo projeto faz isso, o porquê eu fiz isso aqui? Pra manter consistência com o UpdateReview controller/caso de uso. Mais detalhes no passo 8.
- UpdateReview controller que implementa uma outra API. Eu coloquei essa API aqui pra dar uma visão pra um caso de uso que é utilizado por duas entradas diferentes. Mais detalhes no passo 8 abaixo.
Casos de Uso/Entidades
- CreateReviewUseCase cola a nossa regra de negócio. Essa classe chama um serviço externo através do Adapter DetalheReviewsAdapter. Com a informação do DTO e do retorno do Adapter, uma nova review é criada.
- Review e outras entidades de domínio (não representadas no diagrama). Essas entidades estão anotadas com nosso framework de ORM para simplificação.
Persistência
- ReviewDAO persiste a nossa entidade Review no banco de dados. Essa classe é fortemente acoplada ao nosso BD de escolha, nesse caso, o AWS DynamoDB
Esses dois componentes não são da camada de persistência, mas eu vou deixar a explicação aqui por curiosidade/completude:
- O DynamoDB através da funcionalidade de streams (post em breve, prometo 😊) envia uma mensagem sempre que uma nova review é criada. A mensagem contém as informações que foram criadas na review e é enviada para uma fila no AWS SQS (outro post futuro).
- A fila do SQS é consumida por um serviço de moderação de outro time. (Eu estou simplificando bastante aqui, dificilmente nós iríamos expor uma fila SQS, isso tem mais cara de um tópico SNS com múltiplos subscribers).
Adapters/Integração
- Depois de moderada, a nossa review é aprovada ou rejeitada. Um pequeno Worker implementado por uma classe chamada ModerationListener fica ouvindo por mensagens enviadas pelo sistema de moderação. O ModerationListener recebe a mensagem e transforma em um UpdateReviewDTO necessário para chamar a nossa classe de UpdateReviewUseCase.
Percebeu agora porque eu decidi criar um DTO de entrada por caso de uso? Como meu requisito contém múltiplas entradas no meu sistema eu não quis fazer o Listener depender de uma classe da camada de APIs (o RequestDTO).
Note que a solução aqui seguiu uma estratégia “clássica”. Em um ambiente de cloud poderíamos ter resolvido esse problema com um microserviço que roda separadamente dentro de um AWS Lambda.
Simplificações e Trade-offs nesse caso de uso
Como escrever um sistema que escala para milhares de requisições por segundo é muito complexo, várias simplificações foram feitas:
- Várias das chamadas que fazemos poderiam ser Decorators assíncronos que reagem a um primeiro update no banco de dados. Algo mais event-driven para garantir mais escalabilidade. Um bom exemplo é o DetalhesReviewAdapter que poderia ser, por exemplo, um decorator que adiciona informações depois que a review é escrita no nosso banco de dados e nos desacoplaria de esperar uma chamada síncrona ser feito a um serviço externo.
- Eu não adicionei em nenhum caso de uso outras checagens como Idempotência. Normalmente você faz isso assim que possível para evitar chamadas a outras dependências desnecessariamente.
- Toda a moderação, como isso afeta a review e como lidar com escritas concorrentes também não foram lidadas aqui.
- Não estou usando outros padrões como “event source”. Estou considerando que os dados vão ser stateful em vez de guardar as ações e dali tirar um snapshot do review resultante (Se estiver curiosa(o) dê uma olhada no padrão de Event Sourcing).
Já em termos de trade-offs, notem o seguinte:
- Percebem que nossas entidades de domínio estão acopladas ao banco de dados. Por quê? Na maioria dos projetos, o mapeamento é quase 1-1. Se os dois começassem a divergir, eu faria o seguinte refactoring.
- Criar um novo DTO específico para a persistência.
- Manter a entidade de domínio como está e copiar o código para o novo DTO.
- Atualizar as classes de persistência para usar o novo DTO.
- Eu adicionei uma complexidade extra com a adição de DTOs por caso de uso. As vezes, isso nem é necessário e você pode simplesmente passar o DTO do controller direto.
- O nosso listener chama o caso de uso mas muitas vezes, nós queremos que todas as chamadas, mesmo quando feitas dentro do mesmo sistema passem pela API. Nesse caso, o nosso ModerationListener invocaria a API não tendo visibilidade ao caso de uso ou banco de dados. Isso protege os dados e nos dá mais segurança forçando todo mundo a passar pela API.
As complexidades estão nas “bordas”
Você pode estar pensando. “Essa “arquitetura” é simplória demais” ou “Mas e os testes?”. Pois bem, as soluções escritas nesse “padrão” são todas bem testadas, tanto do ponto de vista de unidade quanto de end-to-end. Na unidade, com frameworks modernos como Mockito (Nem tão moderno assim), nós conseguimos fazer mocks de classes concretas facilmente. Também é possível criar fakes através de herança sobrescrevendo os métodos públicos e dando o comportamento que desejamos.
Com relação a simplicidade, a ideia é que seja simples mesmo. A maioria dos problemas que enfrentei nesses últimos 8 anos de carreira não foi relacionado a como implementar uma regra de negócio ou classe X estar fortemente acoplada a classe Y. Os problemas que enfrentei foram mais do tipo:
- Serviço externo A retorna erro Y quando deveria retornar Z.
- Execuções concorrentes afetando os dados
- Infra não escalando ou problema específico da infra.
- Interação e coordenação entre 3 ou mais sistemas sem uso de transações.
- Mensagens duplicadas nas filas ou falta de retries.
Percebeu como um domínio desacoplado dificilmente nos ajudaria com os problemas acima? A maioria dos problemas grandes que enfrentamos se deram por decorrência de erros no System Design ou de comportamentos inesperados entre sistemas, afinal de contas, sistemas distribuídos são estranhos.
Conclusão
Nesse artigo eu apresentei uma proposta que vai de encontro a outros estilos de arquitetura como “Ports and Adapters” ou a “arquitetura limpa”. Não me entendam mal, eu não sou 100% contra esses modelos, e há exemplos de sucesso na indústria com o uso arquitetura hexagonal e/ou clean. Porém tais necessidades devem emergir dos seus requisitos.
Vejam o caso do Netflix. Ali eles tinham a necessidade de conseguir trocar entre datasources de forma rápida e o input/output deles obedecia uma certa forma homogênea que o estilo da Arquitetura Hexagonal podia suprir.
Finalmente, esse artigo não é uma receita do que você deve fazer. Eu apenas decidi a minha experiência e demonstrar que tem muito software sendo escrito, entregue e rodando com sucesso mundo afora que não segue os estilos de “arquitetura” que vemos nos livros. Esses sistemas são bem testados e rodam todo dia para milhões de usuário simultâneos.
Espero que vocês tenham gostado do artigo e que isso te faça pensar se você realmente precisa de tantas classes na hora de escrever seu sistema. Se tiverem alguma dúvida, não deixem de perguntar nos comentários ou no twitter.


![[mldp-newsletter]-nov-2023 — machine-learning-communities:-highlights-and-achievements](https://prodsens.live/wp-content/uploads/2023/12/17515-mldp-newsletter-nov-2023-machine-learning-communities-highlights-and-achievements-380x250.jpg)
