
Whenever I speak with clients about their IT strategy, vendor lock-in seems to be a very urgent and important topic. Especially regulated organizations like banks and insurance companies try to avoid lock-in at all costs. This short article explores this topic and offers some suggestions for dealing with it.
Vendor lock-in
First, we need to define what we mean by “locking into a vendor”. Locking into a vendor usually means, that our systems depend strongly on a vendor’s capability. Switching vendors gets difficult, or prohibitively expensive. Lock-in leads to one-sided advantages for the vendor. Pricing conditions and strategies cannot be freely negotiated anymore, e.g. In addition, some industries are required to handle lock-in explicitly, e.g., financial institutes. They need to have a plan in case a vendor shuts down or deprecates products. Some form of exit-strategy.
“The EBA Guidelines require institutions to have a comprehensive, documented and sufficiently tested exit strategy (including a mandatory exit plan) when they outsource critical or important functions.”
— Source
Let’s consider an example: using a specific database like PostgreSQL.
PostgreSQL is a SQL-based, relational database, similar to MariaDB or Microsoft SQL Server. Each product offers different capabilities. PostgreSQL, e.g., offers strong support for handling CSV data and extended support for regular expressions. Microsoft SQL Server on the other hand offers Views that update automatically.
We can either use these exclusive features or not. Either we depend on PostgreSQL’s handling of CSV data or we don’t. In the first case, we locked-in to this feature. In the second case, we need to build this PostgreSQL-specific feature ourselves.
Many developers should be familiar with this situation. One standard tactic to reduce lock-in like above is to use a facade. A quick look at the Java stack shows solutions like JMS for messaging or JPA for persistence. Each with the intent to abstract the actual underlying technology away. This would, in principle, allow developers to switch between databases without changing code. The next illustration shows the idea.
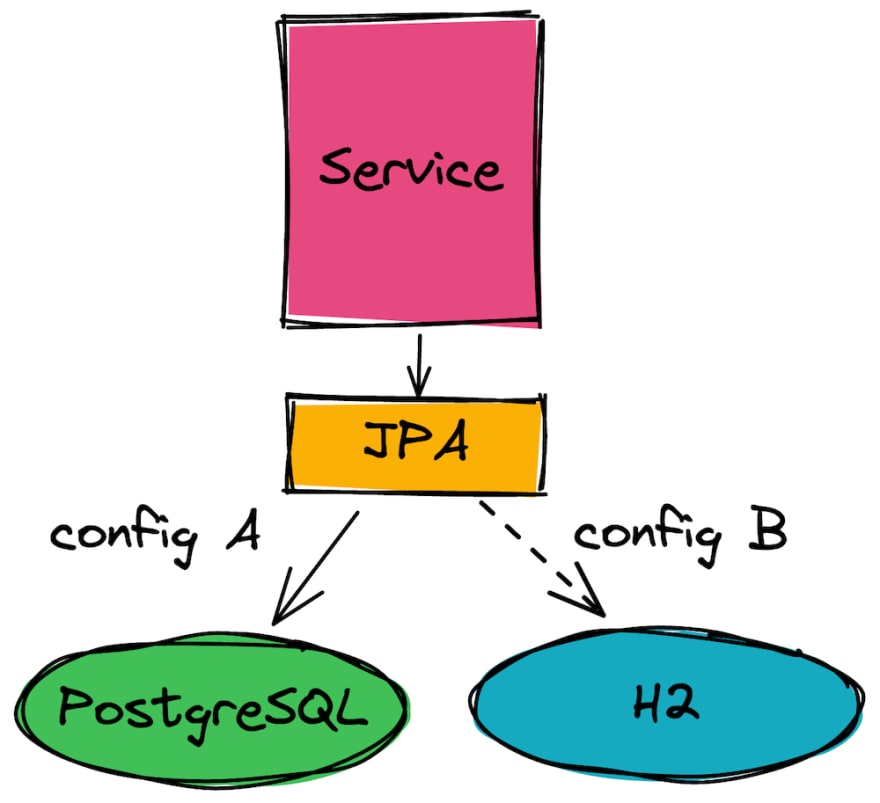
A service uses JPA to access a database. It uses SpringBoot with PostgreSQL by applying config A:
spring.datasource.platform=postgres
spring.datasource.url=jdbc:postgresql://localhost:5432/test
Switching to H2, for example for testing, requires no code changes. The service applies config B.
spring.jpa.database-platform=org.hibernate.dialect.H2Dialect
spring.datasource.url=jdbc:h2:mem:testdb
We do not need to touch the application code. We point to a different SQL flavor spring.jpa.database-platform and to the database instance location spring.datasource.url and we are good to go.
In a nutshell, we insulate our code from the vendor-specific capabilities by putting a facade in between, e.g., JPA. Again, we need to stress this. We give up on any specific database advantage if we use a facade and commit to using only the common features. We cannot rely on PostgreSQL-exclusive features if we want to be able to switch by configuration only.
Let’s apply this concept to the cloud!
The cloud-agnostic architecture
Today, most IT companies have some form of cloud strategy. Choosing a provider is not trivial, especially in regulated industries (banks, insurances, healthcare). SOX, GDPR, HIPAA,… all must be considered when choosing a vendor.
But work does not stop there. Companies need to handle the topic of vendor lock-in. Amazon Web Services (AWS), Google Cloud Platform (GCP), and Microsoft Azure (Azure) offer comparable services and capabilities. But if we look closer, differences emerge. For example, each provider offers options for running containerized workloads. But each does this a little different, with slightly different ways to configure the underlying runtimes and especially different SLAs. Compare Google’s Cloud Run SLA to Azure’s Container Instances.
We might wonder: “What happens if Google raises the prices for their cloud offering? What happens if Azure deprecates a database product we are using?”
A common proposal seems to be: “Let’s build our platform cloud-agnostic! Let’s use Kubernetes as the insulation layer”. The idea seems easy enough. We use Kubernetes as the abstraction layer and depend on no provider-specific tooling.

We build all services as containerized workloads, i.e., OCI images – sometimes called Docker images. We deploy these to the Kubernetes product offered by the cloud vendor. Whenever we need some capability, containers are the answer. This insulates our applications from the vendor. In principle, we could switch providers as long as Kubernetes is available.
Easy? Maybe not.
The Kubernetes Datacenter
We use OCI images for everything and rely on nothing else.
- need a database? PostgreSQL in containers
- need object storage? Minio in containers
- need monitoring? ELK stack in containers
- need messaging? RabbitMQ in containers
- need XYZ? XYZ in containers
This leads to something illustrated by the next diagram.
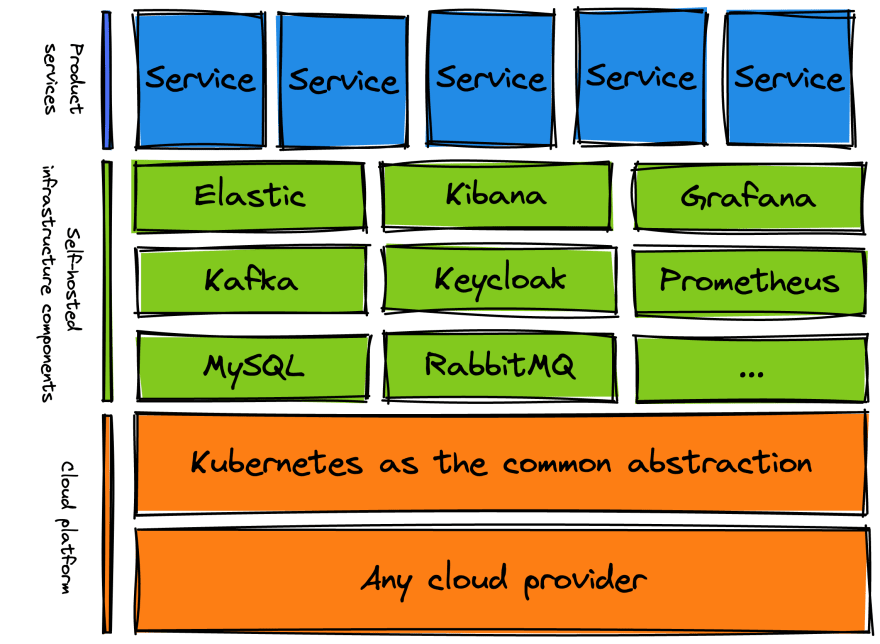
We need to host many infrastructure components ourselves. If we cannot depend on the cloud provider’s IAM solution, then we have to roll our own Keycloak.
Switching platforms
Switching from AWS to Azure means switching from AWS’ EKS to Azure’s AKS. The rest can be moved as is, from AWS to Azure without any big impact. How hard can this be? We are only changing one letter, after all ;).
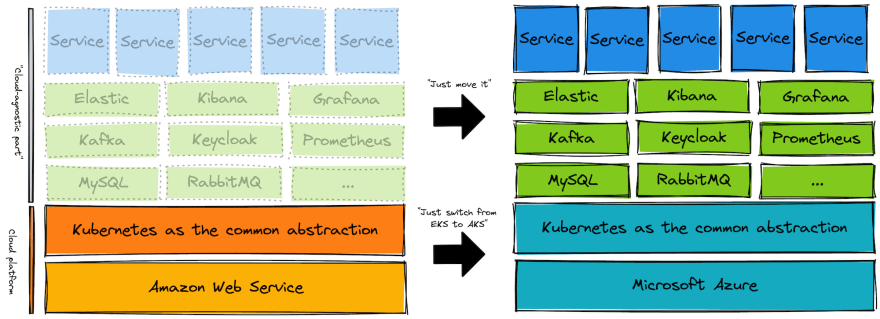
One could even say, that we could switch providers, as long as we can spin up a Kubernetes cluster ourselves. A couple of VMs should be enough. This should be possible on every platform.
So, all is well, right? As we’ll see things may be more complex than that.
The illusion of being cloud-agnostic
The idea is so alluring. And if it worked as described, then this article would not exist.
Revisiting the cloud-sales-pitch
One reason for companies to move to the cloud is to reduce the engineering effort. Using a SaaS database or a SaaS message broker or a SaaS Kubernetes is great for various reasons:
- We can reduce our operational effort. The vendor takes care of patching, updating, and so on.
- We can focus on our product instead of building an internal engineering effort. Or, rephrasing, how does maintaining a load-balancer help our business?
- We can move faster and more efficiently. The provider scales up and down, new products can be used by triggering the cloud vendor’s APIs.
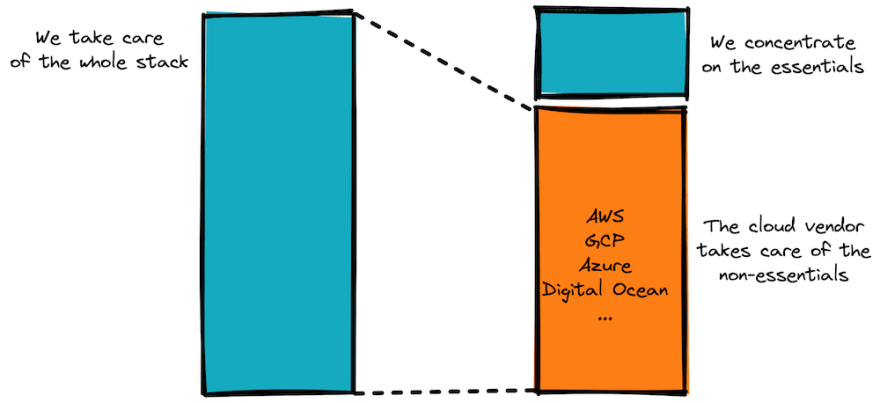
In a nutshell, we refocus our efforts and concentrate on the things that are competitive advantages. Our products. Not our self-written HTTP load-balancer.
If we examine the cloud-agnostic approach, the implications show. We build a custom datacenter, instead of leveraging the cloud provider. Instead of using the SaaS capabilities offered by the cloud vendor, we create our own – often worse – imitations. Instead of reducing the engineering effort, we increase it.
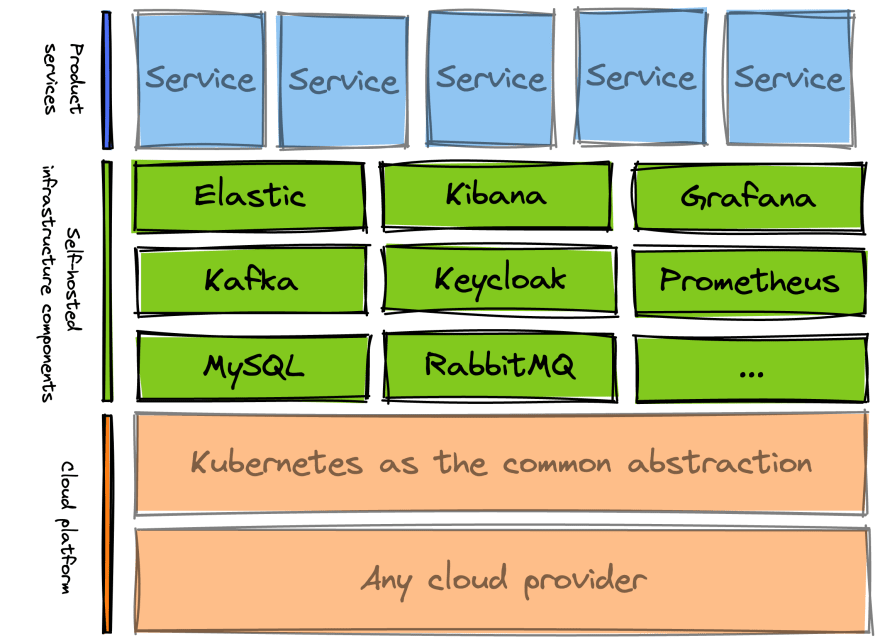
All the highlighted components must be deployed, patched, and maintained by our engineers. They work on patching a database instead of building the next great feature.
But, let’s say that we are fine with all this extra effort. Let’s say that building our development landscape on GCP using only VMs and Kubernetes is acceptable. Including hardening and securing Kubernetes, which in itself are major tasks.
Even after investing all this effort, we are still not cloud-agnostic. Let’s discuss some examples, starting with the obvious and then moving to the maybe-not-so-obvious.
Bare capabilities
Looking at the distribution of datacenters, the Global cloud does not seem so Global after all. Depending on our business, this may or may not be an issue. For example, if we are building a system for a German bank, then we have to meet GDPR requirements. That means we are not free to use any capability worldwide, just like that.
If e.g., we want to serve clients across Africa, choosing a provider is not easy. AWS and Azure have some presence in South Africa, GCP offers some CDN capabilities, but that’s that.
So, building an architecture around the available datacenters is a leaky abstraction. Failover, resilience, and latency – all depend on the location of the datacenters. If one provider offers fewer locations than another, then we are locked in. We need to be aware of this fact and consider its impact when moving from one cloud to another.
If we require special hardware, e.g., dedicated servers, we will find out pretty quickly, that limitless scale may be a problem, too.
Networking
When it comes to networking, the different capabilities of the cloud vendors are often overlooked. Again, on a high level, the vendors seem similar if not identical.
Take for example the concept of a Virtual Private Cloud, short VPC. Unlike AWS and Azure, GCP’s Virtual Private Cloud resources are not tied to any specific region. They are considered to be global resources. However, a VPC is part of a GCP project. A project is used on GCP to organize related resources, e.g., everything an application would need. All subnets within a VPC can communicate unless forbidden by firewall rules. If we want to control communication centrally, we can introduce a so-called Shared VPC, where multiple projects leverage the same VPC. This architecture is not easily transferred to other providers.
The data gravity-well
There are at least two aspects to consider when talking about data and the cloud: cost and data-affinity. Let’s discuss cost first.
Take for example Azure and their data transfer pricing. Moving data into (ingress) an Azure data center is usually free of charge. We can upload terabytes of data without paying a single cent.
Getting data out of a data center (egress) can be expensive on the other hand. Suppose we have one petabyte of data stored in an Azure datacenter and want to move that date someplace else. Using the data transfer pricing page we end up with a five-digit figure (Full disclosure, this is a simplified calculation. Cloud vendors offer better and more cost-effective ways if we want to move data of this size. Pricing calculation on clouds is super-complicated and requires a Math Ph.D.).
The point is: that once data is in a specific data center, getting it out can become expensive quickly and should be planned for.
The second aspect we want to discuss is the data-gravity or data-affinity. The idea is that applications tend to move close to the data they need. If the customer data is in a GCP Spanner instance, then chances are that the applications will run on GCP, too. Sure, we could store data in GCP and have our applications hosted on AWS. But such an architecture is loaded with downsides. Security, cost, latency, and so on may make such an approach undesirable.
Security
Security is the backbone of any non-trivial architecture, especially in the cloud. Every major vendor takes this seriously. AWS, Azure, and GCP are all in the same boat here. A security breach at either vendor negatively impacts trust in all the other vendors, too. This understanding is what Google calls shared fate. It is the cloud provider’s most important job: to stay secure and help customers build secure systems.
However, every vendor approaches security slightly differently. Sure, they all have an IAM approach. They all support encryption. They all allow some form of confidential computing.
But if we look closely, we find differences. The way a secure cloud architecture is setup uses the same concepts (access control, perimeters,…) but how we implement them is completely different. Let’s consider two examples: Key management and Privileged Identity Management.
All providers support some form of bring-your-own-key. We can use our keys for de- and encryption. These keys are usually stored in the provider’s data center. But what if we want to maintain control of the keys and not store them in an external datacenter? That is where External Key Management comes into play. Using this approach, we can control the location and distribution of the keys. At the time of this writing, the GCP offering is superior compared to AWS and Azure, offering capabilities like Key Access Justifications.
Privileged Identity Management, short PIM, allows a user to carry out privileged operations without having “root” or “admin” privileges all the time. In a nutshell, we elevate the user’s privileges for some timeframe. “Ok, you can dig through the database for the next 15 min to debug this issue”. Again, at the time of this writing, only Azure offers this as part of their cloud. AWS and GCP require additional tooling.
These capabilities are subject to change. Vendors tend to fill gaps in their portfolios. Nevertheless, we need to be aware, that each cloud vendor has different capabilities especially when it comes to cross-cutting concerns like security.
In the end, the specifics don’t matter that much. The security capabilities leak into all other aspects of our system landscape.
Infrastructure-as-Code
It is considered good practice to automate infrastructure environments using tools like Terraform or CDK. This helps reduce configuration drift and increases the overall quality of our infrastructure. However, the capabilities of the underlying cloud provider tend to get baked into the infrastructure code.
Moving infrastructure code from GCP to Azure effectively means rewriting everything. Sure the concepts or the high-level architecture may be similar. But for the code, this is similar to moving an application from Java to Go-Lang. In Terraform switching from a GCP provider to an Azure provider means throwing everything away.
The illusion
A true cloud-agnostic approach is an illusion at best. Sure, we can move our OCI-compliant images (read “Docker images”) from one Kubernetes environment to the next. But this is only one tiny piece of a system architecture. And let me stress, that the capabilities of Google’s Kubernetes Engine and Azure’s Kubernetes Service are not the same.
Remember JEE? Same promise. The sales pitch was: We can build an enterprise Java application, package it as an Enterprise Application Repository (EAR) and then run it on JBoss, WebSphere, Weblogic. Only that this was an empty promise with lots of technical challenges. Build once, run everywhere? More like, build once, debug everywhere.
So what can be done?
Strategies for dealing with lock-in
Know the scope of the issue
The first and most important thing is keeping inventory of what we are using. We need to know what products are in use and why if we want to make informed decisions and judge trade-offs. This must be automated and enforced right from the start. Cleaning up after the fact is very difficult and probably does not lead to a complete inventory.
Labels, tags, and comprehensive automation are key.
By the way, keeping inventory is important regardless of the lock-in discussion. Losing track of what we are using is super easy in the public cloud.
Prefer loosely coupled architectures
A few architectural guidelines can lessen the pain of vendor lock-in.
We can mitigate lock-in by following first principles. Loosely coupled architectures are popular for a reason. We can build systems that allow replacing single components if we follow this principle. E.g., if we move our dependency to GCP’s Pub/Sub to a specific component, moving to AWS requires replacing that component with a new AWS SNS version.
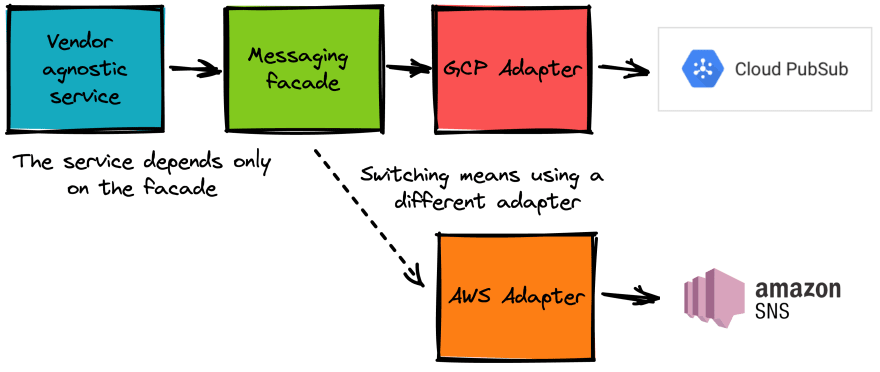
The Messaging Facade is the only direct dependency of our Vendor agnostic service. Moving from GCP to AWS means building and using a different adapter. The service itself need not change.
We build facades whenever a hard dependency on a specific product is needed. This keeps the effects to a minimum when moving between providers. The ideas outlined by the twelve-factor methodology are very useful in this case. But, and this is a big one, we need to be aware of the underlying SLAs, which will impact our design. There is a big difference between 99.9% and 99,95% uptime. Again a potential lock-in which not visible in the code.
We can apply the same ideas if we consider the data architecture. The providers offer mostly comparable solutions for basics like SQL databases, document stores, or key-value use cases. Risk is reduced, if we use standard databases without fringe technology. We can be pretty sure, that we can find something like MongoDB, something like PostgreSQL, something like Kafka on every major cloud.
This is even possible for networks. We can design our network architecture in a way, that allows it to be transferred between providers. We need to be aware of the differences, e.g., the way VPCs work. But the other building blocks, like gateways or subnets, are quite similar. As outlined above, the specific capabilities will leak, but the impact will be reduced if we follow these suggestions.
Again, we need to read the SLAs. We need to be aware of the restrictions and advantages of the products. Not every SQL database supports 100 TBs of data. Not all load-balancers are equal.
Strategic and tactical lock-in
If we want to leverage the cloud provider’s capabilities, then there is no way around lock-in.
We want a reduced engineering effort.
We want higher quality and security.
We want innovation.
So, we approach this strategically.
We identify the areas where lock-in must be kept to a minimum. We use the facade-approach outlined above. We only use products, that have corresponding counterparts on the other platforms.
If we need a SQL database, we choose GCP Cloud SQL instead of GCP’s Cloud Spanner. Cloud SQL is a managed PostgreSQL or MySQL. Similar to Azure Database for PostgreSQL.
The same holds for the runtime. If we use containers, we could use Google’s GKE because a comparable product exists on AWS with Amazon EKS. We could even use the serverless Google Cloud Run, because it is based on KNative, which we could port to Azure or AWS, too.
On the other hand, maybe we could fulfill requirements by using and depending on a product that is not available on other platforms. Take for example Google’s BigTable. It is comparable to Amazon’s DynamoDB. Comparable but not identical. Should we avoid using BigTable in this case? Maybe not. We can ask how difficult rebuilding the component using BigTable to work with DynamoDB would be. We should try to put a number on this. “We need 1 Sprint to move from BigTable to DynamoDB”. This objective number allows us to make a well-informed call, on whether or not locking-into BigTable makes economic sense.
Again, having a good inventory is key. We cannot make these judgment calls if we are not fully aware of who is using what.
Create the exit-strategy up-front
This is the most relevant point, even if it appears trivial. We need to build our exit-strategy first. Most of the points raised above must be tackled right from the start. Otherwise, the suggestions may prove very expensive or even impossible.
Building an exit-strategy with the back to the wall is not a good place to be. We need to consider our options carefully. We must start by asking “What happens if Google shuts down its cloud business within the next 6 months?” and define necessary actions. Having a ball-park estimate of the lock-in is better than running with no idea at all.
And we must not forget to revisit and update our exit strategy regularly. Maybe we are using new products or the vendor’s introduced new capabilities. These must also be handled by our strategy. Otherwise, the exit-strategy will be shelf-ware. Outdated the moment it is written.
Summary
As we saw, building a fully cloud-agnostic system is difficult if not impossible. And even if, the economics are questionable. Dealing with lock-in strategically makes more sense. We need to be aware of lock-ins and the associated costs. A good and automated inventory system is a prerequisite. Nothing is worse than finding out by accident, that an application cannot move from AWS to Azure because of surprising dependencies.
There are ways to build systems that support moving between providers.
Build a comprehensive inventory
First and foremost we need to make sure to know what we are talking about. Having an automated inventory is essential. We need to get this right, before anything else.
Focus on common capabilities
If we do not need some special feature of Cloud Spanner, then let’s not use it. If the capabilities of PostgreSQL meet our requirements, then maybe we should go with PostgeSQL.
Prefer loosely coupled architectures
We mentioned facades and adapters. Nothing to write home about. But mature and good patterns leading to a good architecture.
Run experiments
We may not know, what moving data means. We may not know what switching from Pub/Sub to SNS implies. Running experiments and trying things out is the only way to clarify these questions. Ideas are fine, but running code is the way to go.
Be strategic
Think lock-in through before you get to it. Understand the options before you stand with your back to the wall. Choose lock-in based on numbers. What is the cost of lock-in? What is the opportunity-cost of not-locking-in and building a custom solution?
None of these suggestions is a silver-bullet. None will avoid lock-in. We want to use the cloud provider’s products. But we want to be in a flexible position. We want to be partners that see eye-to-eye.
Being realistic about lock-in and its implications is more useful than falling into the snake-oil pit of easy cloud-agnostic solutions.
There is more to this than “use Kubernetes and you are done”.


