In this article we are going to understand a very important concept in Kubernetes i.e. Data Storage and take a look at its working.
Volumes

So in our last article We used a Node with two pods, my-app and a database, as an example. We are going to use same example for this article.
So we have this Database Pod that our application uses, and it creates some data. If the Database container or Pod is restarted, the data is lost, which is obviously troublesome and annoying because you want your Database data or log data to be consistently persisted over time.
To solve this problem we have another Kubernetes Component known as Volumes
How it works?
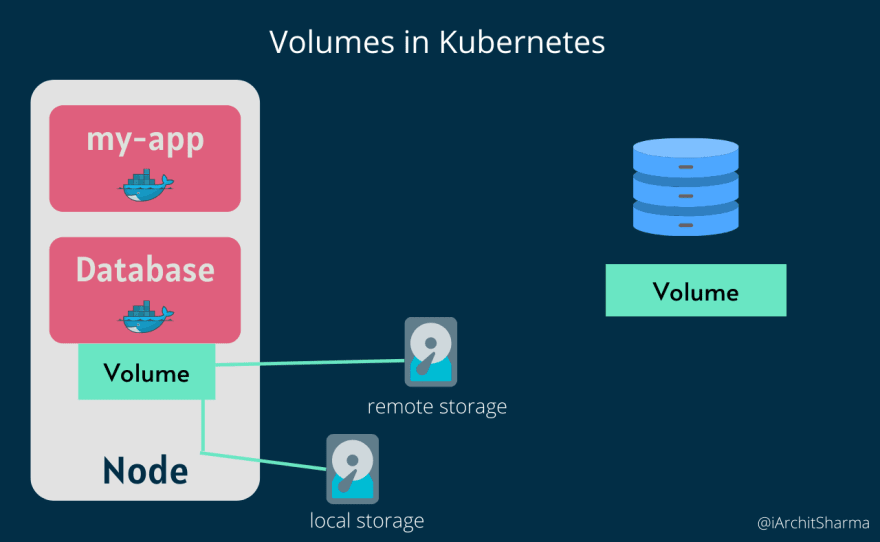
Volume basically attaches physical storage on a Hard drive to your Pod, and that storage could be on your local machine, meaning on the same server Node where the Pod is running, or it could be on a remote storage, meaning outside of the Kubernetes cluster, such as a cloud storage or your own premise storage that is not part of the Kubernetes cluster, so you just have an external reference on it.
So now, when the Database Pod or Container is restarted, all of the data is persisted.
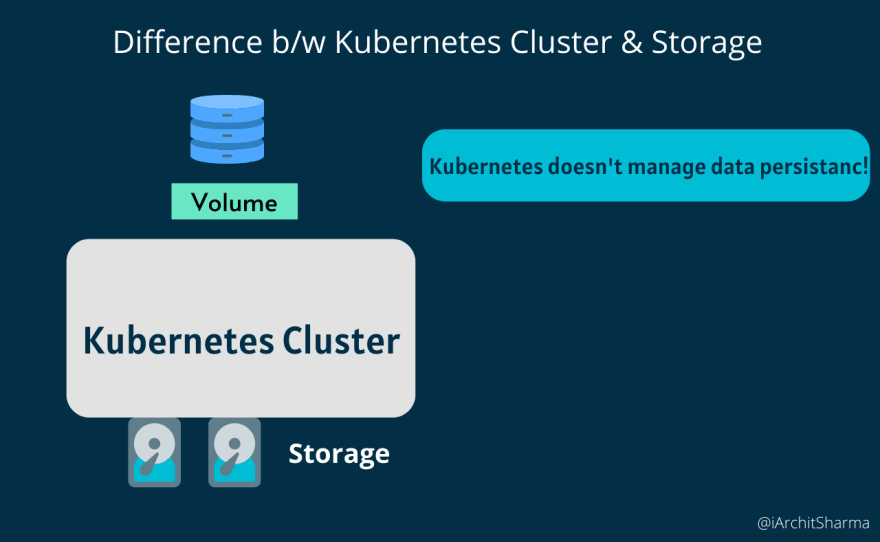
It is important to understand the distinction between the Kubernetes Cluster and the Storage, regardless of whether it is local or remote. Consider storage to be an external Hard drive inserted into the Kubernetes Cluster because Kubernetes Cluster does not explicitly handle data persistence, which means that you, as a Kubernetes user or Administrator, are responsible for backing up the data, duplicating it, maintaining it, and ensuring that it is stored on proper hardware, among other things.
In the next article we are going to take a look at two more Kubernetes Components that is Deployment and StatefulSet
Thank you for reading this blog; do follow me for more